Использование Caché SQL Gateway
Гришина Мария,
В Caché реализован специальный механизм Caché SQL Gateway, позволяющий обращаться к внешним источникам данных посредством ODBC. Таким образом, этот механизм позволяет программам на языке Caché Object Script осуществлять обращение к внешним реляционным базам данных. В отличие от Caché ODBC (JDBC и др.), предоставляющих доступ к данным Caché для внешних реляционных источников, SQL Gateway – это средство, позволяющее взаимодействовать с реляционными источниками данных в противоположном направлении.
Поскольку для связи с внешними реляционными источниками данных Caché SQL Gateway использует ODBC, необходимо создать и/или настроить источник данных ODBC (DSN) соответствующей “внешней” базы данных. Для этого необходимо выполнить следующие действия (или убедиться, что они уже выполнены):
1) Инсталлировать драйверы ODBC соответствующей СУБД. Некоторые драйверы, например MS SQL Server как правило, уже присутствуют в Windows. Некоторые, такие как MSM SQL, MySQL устанавливаются отдельно. Некоторые (Oracle, Caché) инсталлируются при установке клиентской части СУБД.
2) Создать источник данных (DSN) из программы настройки ODBC. Например, в ОС Windows 2000 эта программа доступна из меню Windows: Start->Settings->Control panel->Administrative tools->Data Sources (ODBC) (Рис.1). Рекомендуется для работы через SQL Gateway создавать системные DSN.
3) После создания DSN появится диалог конфигурации, который специфичен для каждого отдельного драйвера. Как правило, необходимо указать имя сервера, имя пользователя и пароль, и некоторые другие настройки, например, БД по умолчанию.
Рис. 1. ODBC Data Source Administrator
Возможно несколько способов использования SQL Gateway:
Создание так называемых link-таблиц и хранимых (Persistent) классов Caché, использующих Gateway-хранение (т.е. данные которых хранятся во внешних СУБД);
выполнение запросов, обращаясь непосредственно к внешним таблицам (с использованием класса Caché %ResultSet (который обычно используется разработчиками для выполнения запросов к классам Caché) в сочетании с классами %SQLGatewayConnection и %DynamicQueryGW);
работа с SQL Gateway на низком уровне (используя функции SQL Gateway API).
Использование класса %Library. с Caché SQL Gateway
Для осуществления выборки из внешних источников данных, удобно использовать библиотечные классы %Library.ResultSet и %Library.DynamicQueryGW.
Пожалуй, это наиболее простой и удобный способ доступа к внешним данным в тех случаях, когда требуется только получать множество строк путем вызова SQL-команды или хранимой процедуры. Для работы таким способом не требуется регистрировать DSN, не требуется описывать связанные таблицы, не требуется знать методы класса %SQLGatewayConnection (кроме Connect / Disconnect), используемые при работе с SQL GateWay на низком уровне. В Листинге 2 приведен пример выполнения выборки с использованием класса %ResultSet.
Листинг 2 Set Connection=##class(%SQLGatewayConnection).%New()
Set res = Connection.Connect("DSNName","username","pwd")
Set ResSet=##class(%ResultSet).%New("%DynamicQueryGW:SQLGW")
Do ResSet.Prepare("SELECT * FROM TABLE",,Connection)
Do ResSet.Execute()
while ResSet.Next()
{
For i=1:1:ResSet.GetColumnCount()
{
if (i'=ResSet.GetColumnCount())
{
Write ResSet.GetData(i)_", "
}
else
{
Write ResSet.GetData(i),!
}
}
}
d Connection.Disconnect()
Рассмотрим этот пример по шагам:
-Сначала создается соединение с DSN для чего создается экземпляр класса %Library.SQLGatewayConnection, затем вызывается метод Connect(), которому в качестве аргументов передается имя созданного источника данных (DSN), а также, если это необходимо, имя пользователя и пароль:
Set Connection=##class(%SQLGatewayConnection).%New()
Set res = Connection.Connect("DSNName"," username", “pwd")
-Затем создаем объект класса %ResultSet
ResSet=##class(%ResultSet).%New("%DynamicQueryGW:SQLGW")
-Определяем и выполняем запрос (обратите внимание Connection, т.е. созданное SQLGateWay соединение передается третьим параметром): Do ResSet.Prepare("SELECT * FROM TABLE",,Connection)
Do ResSet.Execute()
while ResSet.Next()
{
For i=1:1:ResSet.GetColumnCount()
{
if (i'=ResSet.GetColumnCount())
{
Write ResSet.GetData(i)_", "
}
else
{
Write ResSet.GetData(i),!
}
}
}
-Разрываем соединение: Do Connection.Disconnect()
Важно отметить, что объект %SQLGatewayConnection создается отдельно не случайно. Само соединение с удаленным источником данных занимает довольно много времени, поэтому было бы нерационально открывать соединение для каждого отдельного запроса.
Использование мастера связывания таблиц
Для создания в Caché таблиц, представляющих собой связи с таблицами “внешних” ODBC-источников предусмотрен мастер связывания таблиц (Link Table Wizard), который доступен из SQL-менеджер.
Рассмотрим по шагам создание link-таблицы Caché (будем считать, что вы уже зарегистрировали нужный DSN в Редакторе конфигурации). Для того, чтобы запустить мастер связывания таблиц откройте SQL-менеджер и перейдите к нужной области, в которой вы хотите создать вашу link-таблицу. Мастер доступен из меню SQL-менеджера (Рис. 4. SQL-менеджер Caché): Файл->Связать таблицу (или щелкните правой кнопкой мыши на пункте “Таблицы” для выбранного пакета и в контекстном меню выберите “Создать таблицу”, а затем “Связать таблицу”).
Рис. 4. SQL-менеджер Caché
В результате этих действий откроется мастер создания связей с “внешними” таблицами (Рис. 5), работа мастера заключается в выполнении определенной фиксированной последовательности шагов. Как видно из рисунка 5, на первом шаге мастера не нужно выполнять никаких действий, нажмите кнопку “Далее”.
Рис. 5. Первый шаг мастера
На втором шаге мастера (Рис. 6) отображается список источников данных, зарегистрированных в Caché (зарегистрированных Gateway-соединений). Выберите нужное Gateway-соединение и нажмите кнопку “Далее”.
Рис. 6. Второй шаг мастера
На третьем шаге мастера (Рис. 7) отображается список таблиц, доступных в выбранном источнике данных. Выберите нужную таблицу и нажмите кнопку “Далее”.
Рис. 7. Третий шаг мастера
Рис. 8. Четвертый шаг мастера
На четвертом шаге мастера (Рис. 8) отображается список столбцов выбранной таблицы “внешнего” ODBC-источника, укажите столбцы, которые должны присутствовать в новой таблице и нажмите кнопку “Далее”.
Пятый шаг мастера. Здесь вы можете отредактировать имена полей, если необходимо. Обратите внимание на то, что названия полей должны соответствовать синтаксису Caché для свойств объектов, например, знаки подчеркивания недопустимы. Приведя имена столбцов создаваемой таблицы к нужному виду, нажмите кнопку “Далее”.
Рис. 9. Пятый шаг мастера
На шестом, заключительном шаге мастера вы можете указать, какое поле (поля) является первичным ключом и отредактировать имя таблицы Caché, которая будет создана мастером, и соответствующего данной таблице хранимого класса Caché. Имена таблицы и соответствующего ей класса не обязательно должны совпадать. Если, например, в вашем приложении в именах классов желательно придерживаться определенного стиля, или в приложении уже есть класс с данным именем, возможность изменять названия классов (и таблиц) может быть полезной. В том случае, если указанное имя класса содержит недопустимые, с точки зрения Caché символы (например, подчеркивания), Caché удалит эти символы из имени класса.
Рис. 10. Шестой шаг мастера
По окончанию работы мастера создается таблица Caché, данные которой физически расположены во “внешнем” источнике данных. Созданная link-таблица доступна из Caché SQL. Автоматически для созданной таблицы создается хранимый (Persistent) класс Caché, использующий GateWay-хранение. Объектами созданного класса можно пользоваться как обычно, т.е. можно описывать методы, вычислимые поля, суперклассы и т.д., но нельзя изменить схему GateWay-хранения. Впрочем, ничто не мешает добавить в описание класса альтернативные способы хранения. Когда вы сочтете нужным, можно будет поменять хранение с “внешнего” на “внутреннее” незаметно для окружающих.
Отличием от использования “внутренних” таблиц Caché является невозможность комбинировать в одном запросе “внутренние” (родные) и “внешние” таблицы.
Обратите внимание: если с обычными, “внутренними” таблицами вы сначала описываете хранимый класс, одной из проекций которого является SQL-представление, другими словами класс первичен, таблица вторична, то в случае с внешними таблицами все наоборот. Сначала вы описываете внешнюю таблицу с помощью мастера, затем автоматически создается новый класс, соответствующий новой таблице.
В Листинге 1 приведен пример класса, созданного с помощью мастера связывания таблиц.
Как видно из примера, в качестве стратегии хранения для этого класса определена GSQLStorage, что означает, что данные хранятся в таблице внешнего ODBC-источника. Поскольку созданным классом можно пользоваться как обычно, т.е. добавлять методы, вычислимые поля и т.п., в данном примере, для иллюстрации такой возможности, к созданному классу добавлен SQL-запрос.
Листинг 1 Class dbo.Manager Extends %Persistent [ ClassType = persistent, SqlRowIdPrivate, SqlTableName = Manager,
StorageStrategy = GSQLStorage ]
{
Parameter CONNECTION = "Managers,NOCREATE";
Parameter EXTERNALTABLENAME = "dbo.Manager";
Property Id As %Integer(EXTERNALSQLNAME = "Id")
[ SqlColumnNumber = 4, SqlFieldName = Id ];
Property Name As %String(EXTERNALSQLNAME = "Name",
MAXLEN = 50) [ SqlColumnNumber = 2, SqlFieldName = Name ];
Property OrdersAmount As %Integer
(EXTERNALSQLNAME = "OrdersAmount") [ SqlColumnNumber = 3, SqlFieldName = OrdersAmount ];
Index MainIndex On Id [ IdKey, PrimaryKey ];
Query ManagerInfo() As %SQLQuery
{
SELECT Id,Name,OrdersAmount FROM Manager
ORDER BY Name
}
}
Работа с SQL GateWay на низком уровне
С SQL GateWay можно работать и на низком уровне, используя функции SQL Gateway API. Большинство функций SQL Gateway API инкапсулированы в классе %Library.SQLGatewayConnection, что несколько облегчает кодирование. Необходимо отметить, что %SQLGatewayConnection – это только часть всего того, что относится к SQL Gateway в Caché. В основном методы %SQLGatewayConnection соответствуют по названию и использованию соответствующим функциям API. Все методы класса %SQLGatewayConnection возвращают значение типа %Status, что позволяет осуществлять обработку ошибок. Рассмотрим отдельно некоторые методы.
Для соединения с ODBC-источником данных (DSN) используется метод Connect (DSN,User,Password): Set Connection=##class(%SQLGatewayConnection).%New()
// устанавливаем соединение
Do Connection.Connect(DSN, "User", "pwd")
Для разрыва соединения используется метод Disconnect(): Set sc=Connection.Disconnect() Прежде, чем выполнять запрос, необходимо сначала создать команду (Statement). Для создания команды используется метод AllocateStatement(), аргумент (Handle) методу AllocateStatement() передается по ссылке (перед именем аргумента ставится “.”): Set sc=Connection.AllocateStatement(.Stat)
Для удаления команды используется метод DropStatement(): Set sc=Connection.DropStatement(Stat)
Перед выполнением запроса его необходимо “подготовить”, для чего используется метод Prepare(Stat, sql). В качестве аргументов методу передается созданная команда и строка sql-запроса. Возможно выполнение запросов с параметрами, тогда в строке sql на месте параметров ставятся знаки “?”: //подготовка запроса
Set sc=Connection.Prepare
(Stat,"SELECT * FROM TABLE WHERE Name=? AND Age=?") Если передается sql-запрос с параметрами, то эти параметры необходимо подготовить и присвоить им определенные значения. Для подготовки параметров используется метод BindParameters(). Аргументы метода BindParameters():
созданная команда;
типы параметров: 1 – in (входной), 2-in/out (входной/выходной), 4-out (выходной);
cписок типов данных ODBC (например: 4-int, 9-DATETIME, 12-VARCHAR, 8-DOUBLE, …);
размеры буферов в байтах;
число знаков после точки (только для Decimal и Float);
список длин типов данных в байтах;
Все аргументы метода BindParameters(), начиная со второго имеют тип %List и должны передаваться в качестве аргументов функции $LB(). Если в запросе несколько параметров, то в качестве аргументов $LB() передаются значения через запятую, соответствующие каждому параметру в порядке их следования в строке запроса, например: Set sc=Connection.BindParameters(Stat,$LB(1,1),$LB(12,4),
$LB(50,4),$LB(0,0),$LB(50,4))
Значение нужного типа данных ODBC можно посмотреть в глобале ^%qCacheSQL (область %CACHELIB) по первому индексу равному "odbcdt", тогда второй индекс соответствует нужному типу данных (Рис. 11).
Присваивание значения параметру осуществляется с использованием метода SetParameter(Stat, $LB(val), Numb). В качестве аргументов методу SetParameter() передаются:
созданная команда;
значение параметра как аргумент функции $LB(); порядковый номер параметра в строке запроса.
Метод SetParameter() вызывается отдельно для каждого переданного параметра: Set sc=Connection.SetParameter(Stat,$LB(“Alice”),1)
Set sc=Connection.SetParameter(Stat,$LB(5),2) Для выполнения запроса используется метод Execute(Stat), которому в качестве аргумента передается созданная команда: Set sc=Connection.Execute(Stat)В Листинге 3 приведен пример запроса к внешней таблице с использованием методов класса %Library.SQLGatewayConnection. Данный запрос выбирает все поля из таблицы INFO внешнего ODBC-источника (с именем DSNName), для которых значение поля Age=21, а значение поля Name начинается с буквы “D”.
Листинг 3 Set Connection=##class(%SQLGatewayConnection).%New()
// устанавливаем соединение
Do Connection.Connect("DSNName","sa","pwd")
// создание новой команды
Set sc=Connection.AllocateStatement(.Stat)
// подготовка запроса
Set sc=Connection.Prepare(Stat,"SELECT * FROM INFO WHERE
Age=? AND Name LIKE ?")
// подготовка параментов
Set sc=Connection.BindParameters(Stat,$LB(1,1),$LB(4,12),
$LB(4,50),$LB(0,0),$LB(4,50))
Set sc=Connection.SetParameter(Stat,$LB(21),1)
Set sc=Connection.SetParameter(Stat,$LB("D%"),2)
// выполнение запроса
Set sc=Connection.Execute(Stat)
For { Q:'Connection.Fetch(Stat)
S Sc=Connection.GetOneRow(Stat,.Row)
For J=1:1:$LL(Row) Write $LG(Row,J)_" "
Write !
}
// удаление команды
Set sc=Connection.DropStatement(Stat)
// разрыв соединения
Set sc=Connection.Disconnect()
Регистрация ODBC источников данных в Caché
Для регистрации DSN в Caché откройте Редактор конфигурации из меню Caché-куба и перейдите к вкладке “Дополнительно” (Рис.2). Вы увидите отдельный пункт “SQL Gateway”. Нажмите правую кнопку мыши для появления контекстного меню. И выберите пункт меню “Добавить”. Можно иначе - просто нажать кнопку “Добавить”.
В появившемся диалоговом окне (Рис. 3) укажите имя Gateway-соединения. Затем для созданного Gateway-соединения укажите имя ранее созданного DSN (обязательно), а также имя пользователя и пароль, если это необходимо.
После выполнения указанных действий DSN зарегистрирован в системе. Перезагрузка не требуется. Указанные действия можно повторить для других источников данных.
Рис. 2. Редактор конфигураций Caché

Рис. 3
Создание link-таблиц в Caché
В Caché имеется возможность создавать таблицы, представляющие собой связи с таблицами “внешних” ODBC-источников. Это так называемые link-таблицы Caché, данные которых физически хранятся во “внешней” СУБД. Для создания link-таблиц в Caché предусмотрен специальный мастер связывания таблиц (Link Table Wizard), доступный из SQL-менеджер. По окончании работы мастера создается таблица Caché и соответствующий этой таблице хранимый класс Caché, использующий GateWay-хранение (GSQLStorage).
Для того, чтобы пользоваться мастером создания связей с внешними таблицами, источники данных ODBC необходимо зарегистрировать в редакторе конфигурации. Это объясняется тем, что Caché не может самостоятельно получить список DSN.
Оптимизация загрузки данных в Caché
Александр Чеснавский,
Системы управления базами данных являются неотъемлемой частью любой автоматизированной информационной системы, обеспечивая создание базы данных, поддержание ее в актуальном состоянии и предоставление эффективного доступа пользователей и их приложений к содержащейся в БД информации. В связи с этим весьма актуальной становится проблема оптимизации приложений для более производительного выполнения таких операций, как загрузка и поиск данных. Данная статья содержит набор практических рекомендаций по улучшению систем, созданных на основе СУБД Caché. Основной акцент сделан на проблеме массовой загрузки данных (“bulk load”).
Прежде всего хотелось бы отметить, что СУБД Caché поддерживает несколько моделей данных – объектную, реляционную и иерархическую, благодаря чему открывается большой простор для способов загрузки данных. В одних случаях нам удобно(и, возможно, достаточно) создавать наборы данных с помощью объектного или реляционного подхода, для достижения же максимальной производительности следует использовать возможности прямого доступа к глобальным структурам Caché.
В качестве первого примера рассмотрим простое создание экземпляров классов в Caché. Несмотря на кажущуюся простоту, этот пример позволит оценить преимущества и недостатки различных способов массовой загрузки данных в Caché.
Итак, ниже мы видим несложное определение класса, содержащее три целочисленных свойства a, b и c, а также стандартные индексы aIN, bIN и cIN , определенные для свойств a, b и c соответственно.
Class Temp.A Extends %Persistent [ ClassType = persistent, ProcedureBlock ] { Property a As %Integer; Property b As %Integer; Property c As %Integer;
Index aIN On a; Index bIN On b; Index cIN On c; }
Листинг 1 Определение класса Temp.A
Поставим перед собой задачу создания одного миллиона экземпляров этого класса. Наиболее очевидный способ создать требуемое количество объектов - это инстанцировать в цикле один миллион экземпляров, заполнить их данными и сохранить.
Для этого можно использовать следующий код:
for i=1:1:N { Set obj=##class(Test.A).%New() Set obj.a=$Random(1000) Set obj.b=$Random(1000) Set obj.c=$Random(1000) Do obj.%Save() }
Листинг 2 Загрузка данных на основе объектного подхода
Попробуем выполнить этот код. На моей машине ( Intel Pentium III 800 Mhz ,256М ОЗУ, Microsoft Windows 2000 SP 4, Caché 5.0.5.936.2) этот процесс занял 473.421 секунд (7 минут и 53 секунды). Стоит отметить, что на время загрузки влияют такие факторы, как размер кэша глобалей и программ, журналирование, транзакции, блокировки и т.д. Конкретное влияние этих факторов будет рассмотрено ниже. Если говорить про описанную выше загрузку объектов, то длительность этого процесса можно объяснить накладными расходами на создание объектов и их сохранение, многочисленными проверками и преобразованиями, которые необходимо проводить в рамках объектного подхода.
Подобных издержек можно избежать с использованием реляционного представления тех же самых данных в Caché. Изменим код таким образом, чтобы в цикле не инстанцировать и сохранять экземпляры классов, а создавать их аналоги с помощью оператора SQL INSERT.
for i=1:1:N { Set val1=$Random(1000) Set val2=$Random(1000) Set val3=$Random(1000) &sql(INSERT INTO Test.A (a, b, c) VALUES (:val1,:val2,:val3) ) }
Листинг 3. Загрузка данных на основе SQL-подхода
Результат выполнения этого кода показал, что избавившись от накладных расходов, связанных с объектным подходом, время добавления одного миллиона объектов сократилось более чем в два раза и составило 233.045 секунды (3 минуты 53 секунды). Кроме того, дополнительных расходов, связанных с проверкой ограничений, созданием индексов и т.п. можно избежать, используя директивы %NOLOCK, %NOCHECK, %NOINDEX (INSERT %NOLOCK,%NOCHECK,%NOINDEX …). Если данная производительность не является достаточной, то существует возможность прямого доступа к хранимым структурам Caché. Как известно, данные в Caché логически хранятся в виде разреженных многомерных массивов.
Количество измерений этих массивов не ограничено, и не требуется заранее определять максимальную размерность. Поведение массивов в памяти ничем не отличается от поведения массивов, сохраняемых на диске. Все, что нужно сделать, для того чтобы конкретный массив стал хранимой структурой - это добавить перед именем массива знак ^ («циркумфлекс»). Например, следующий код ^ myArray (1,” red ”,-4)=”green” говорит о том, что в массиве (хранимые массивы в Caché называются глобалами, в отличие от локалей – массивов в памяти) myArray в «ячейке» с индексами ( 1, “red”, -4 ) хранится значение “green”. Важно отметить, что в качестве индексов в Caché могут выступать целые числа, дробные числа, строки.
Если вернуться к примеру загрузки данных, то создать набор экземпляров класса Temp. A можно и с помощью прямого доступа к глобалам. Это связано с тем, что в Caché как классовое представление, так и реляционное в основе своей содержат многомерные структуры данных. Стандартная схема хранения в Caché выглядит следующим образом: в глобале данных (в нашем случае это ^ Test . AD) на нулевом уровне хранится идентификатор последнего объекта (^ Test . AD =99). На первом уровне в индексе хранится сам идентификатор, а в узле список свойств объекта. Так, например, для объекта с идентификатором 11, у которого свойства a, b и c равны 1, 2 и 3 соответственно, запись в глобале будет выглядеть следующим образом: ^Test.AD(11)=<<$ListBuild("","1","2","3")>>
Возникает вопрос, почему первый элемент списка является пустым? Он используется для идентификации экземпляров классов-потомков. В нашем случае класс Test . A наследует только от системного класса % Persistent и в схеме хранения определен лишь один класс Test. A, поэтому значение первого элемента списка пустое. Если же определить класс Test. B, являющийся наследником от Test . A , то по умолчанию экземпляры класса Test . B будут хранится в одном глобале с экземплярами класса Test.
A, и для определения класса, к которому принадлежит конкретный экземпляр, и вводится первый элемент в списке.
Кроме того, если в классе определены индексы, то по умолчанию создается структура хранения для индексов (в нашем случае это ^ Test . AI ). Структура этого глобала довольно проста (здесь рассматриваются лишь стандартные индексы): для каждого индекса с именем indexName создается узел в глобале, который выглядит следующим образом: ^Test.AI(" indexName ",value , ID )=.
Здесь value – значение свойства, на которое «настроен» данный индекс в объекте с идентификатором ID. Таким образом, зная структуру хранения объектов в Caché, можно создать набор экземпляров, используя низкоуровневые средства. Рассмотрим следующий код:
for i=1:1:N { Set val1=$Random(1000) Set val2=$Random(1000) Set val3=$Random(1000)
Set ^Test.AD(i)=$ListBuild("",val1,val2,val3) Set ^Test.AI("aIN",val1,i)="" Set ^Test.AI("bIN",val2,i)="" Set ^Test.AI("cIN",val3,i)=""
Set ^Test.AD=i }
Листинг 4. Загрузка данных на основе прямого доступа
Здесь в цикле создается узел в глобале ^Test.AD, который заполняется случайными значениями, а также формируются индексы в глобале ^Test.AI. После создания очередного «объекта» счетчик количества объектов увеличивается на единицу. Благодаря использованию прямого доступа время загрузки уменьшилось до 98 секунд. Однако, это не предел для оптимизации. С алгоритмической точки зрения, оказывается излишним увеличение в цикле счетчика объектов. Его можно вынести вне конструкции for и избавиться от N -1 дополнительных обращений к глобалу ^Test.AD. Тогда код будет выглядеть следующим образом, а время выполнения уменьшится до 85 секунд:
for i=1:1:N { Set val1=$Random(1000) Set val2=$Random(1000) Set val3=$Random(1000)
Set ^Test.AD(i)=$ListBuild("",val1,val2,val3) Set ^Test.AI("aIN",val1,i)="" Set ^Test.AI("bIN",val2,i)="" Set ^Test.AI("cIN",val3,i)="" } Set ^Test.AD=N
Листинг 5. Загрузка данных на основе прямого доступа. Улучшение 1.
Данный код, как и предыдущий, не использует транзакции и блокировки. Более корректным решением было бы использование конструкции TSTART - TCOMMIT, обрамляющие запись в глобал, а также установка соответствующих блокировок. Однако, использование транзакций при массовой загрузке данных снижает скорость записи приблизительно на 40 процентов, и в условиях “bulk load” в ряде случаев можно отказаться от использования связки TSTART - TCOMMIT - TROLLBACK (зачастую при массовой загрузке данных система функционирует как однопользовательская, и необходимо любыми способами достичь максимальной производительности).
Выше уже говорилось, что данные в Caché хранятся в виде многомерных разреженных массивов (глобалов). Однако это лишь логическое представление. На физическом уровне глобалы организованы в виде B *-деревьев, детальное описание которых не является предметом этой статьи. Однако, для создания эффективных алгоритмов записи в глобал следует знать, что наиболее быстро происходит добавление элементов, когда индексы добавляемых элементов упорядочены в лексикографическом порядке (что имеет место в случае заполнения глобала ^Test.AD). При добавлении неупорядоченных элементов происходит частое расщепление блоков, в которых хранятся глобалы, что неизбежно приводит к падению производительности (в нашем случае это формирование индексов в глобале ^Test.AI). Эффективным средством для борьбы с этой проблемой является использование промежуточного буфера в памяти. Запись в глобал происходит через этот буфер. Элементы в нем автоматически упорядочиваются и сбрасываются на диск в лексикографическом порядке, что положительно сказывается на производительности. К счастью, в Caché предусмотрен механизм создания такого буфера с помощью команд $ SORTBEGIN /$ SORTEND . Критический участок кода обрамляется этой конструкцией,и далее работа с глобалами идет также, как и без использования $ SORTBEGIN /$ SORTEND . Таким образом, абсолютно прозрачно для разработчика формируется буфер, который сбрасывает на диск глобалы с уже упорядоченными индексами.
Чтобы использовать эту возможность, необходимо незначительно изменить код:
Set res=$SortBegin(^Test.AI) for i=1:1:N { Set val1=$Random(1000) Set val2=$Random(1000) Set val3=$Random(1000)
Set ^Test.AD(i)=$ListBuild("",val1,val2,val3) Set ^Test.AI("aIN",val1,i)="" Set ^Test.AI("bIN",val2,i)="" Set ^Test.AI("cIN",val3,i)="" } Set ret = $SortEnd(^Temp.AI) Set ^Test.AD=N
Листинг 6. Загрузка данных на основе прямого доступа. Улучшение 2.
Если же говорить о производительности, то выполнение этого кода при N =1000000 занимает порядка 38 секунд, что быстрее варианта без использования связки $ SORTBEGIN /$ SORTEND более чем в два раза.
Последняя стратегия записи в глобал активно использует временные структуры. Поэтому одним из средств увеличения производительности служит настройка размера кэша глобалей. Сама настройка проводится очень просто – необходимо указать новый размер кэша в Редакторе Конфигураций ® Основное. Более интересным представляется определение требуемого размера кэша. Это можно сделать несколькими способами:
Во-первых, методом экспериментальной проверки, при котором наиболее подходящий размер кэша подбирается вручную.
Во-вторых, с помощью набора утилит для анализа производительности системы (GLOSTAT, PERFMON и другие), входящих в состав Caché. Среди прочей статистики о системе, они содержат информацию об эффективности использования кэша глобалов и программ, с помощью которой можно с большей точностью определить необходимый размер кэша. А благодаря тому, что каждый процесс ( в том числе и тот процесс, в котором мы загружаем данные) является отдельным процессом операционной системы, то появляется возможность дополнительной настройки производительности средствами операционной системы.
Рассмотрим более подробно профилировку программы с помощью утилиты ^%MONLBL. Эта утилита служит для сбора статистики по выполнению программ. Процедура использования этой утилиты (как и многих других утилит сбора статистики) следующая: запустить монитор, выполнить программу, которую требуется проанализировать, получить статистику и остановить монитор.
После запуска утилиты ^% MONLBL предлагается выбрать набор программ для профилировки и набор метрик. Для выбора предоставляется более 50 метрик, среди которых есть метрики, связанные с числом глобальных ссылок (GloRef), операций с глобалами (GloSet, GloKill). Кроме того, есть возможность анализа статистик по обращению к физической организации глобалов в виде B *-дерева (DirBlkRd, UpntBlkRd, BpntBlkRd и другие), функционированию в распределенной среде( NetGloRef, NCaché Hit, NCaché Miss и другие) и т.д.
Для анализа описанной выше программы рассмотрим временные статистики (Time, TotalTime).
После настройки утилиты запустим программу загрузки одного миллиона объектов. Стоит отметить, что при сборе статистики процедура загрузки будет проходить медленнее, что связано с накладными расходами на сбор данных. Отчет, созданный с помощью ^% MONLBL, выглядит следующим образом.
Line Time TotalTime 1 0.000026 0.000026 add(N=1000) public 2 0 0 { 3 0.039753 0.039753 k ^Test.AD 4 0.021115 0.021115 k ^Test.AI 5 0.000165 0.000165 Set ret = $SortBegin(^Test.AI) 6 0.000013 0.000013 for i=1:1:N 7 0 0 { 8 7.349726 7.349726 Set val1=$Random(1000) 9 6.954847 6.954847 Set val2=$Random(1000) 10 6.966766 6.966766 Set val3=$Random(1000) 11 15.408908 15.408908 Set ^Test.AD(i)= $ListBuild("",val1,val2,val3) 12 13.878284 13.878284 Set ^Test.AI("aIN",val1,i)="" 13 11.493729 11.493729 Set ^Test.AI("bIN",val2,i)="" 14 11.358133 11.358133 Set ^Test.AI("cIN",val3,i)="" 15 4.163146 4.163146 } 16 21.203588 21.203588 Set ret = $SortEnd(^Test.AI) 17 0.035609 0.035609 Set ^Test.AD=N 18 0.000029 0.000029 }
Листинг 7 Результат сбора статистики с помощью утилиты ^%MONLBL
С помощью подобных отчетов, возможно, включающих большее количество полей, можно провести построчный анализ программы и выбрать наиболее подходящую реализацию алгоритма.
Еще одна возможность увеличения производительности – отключение журналирования. Это также может в определенной степени увеличить скорость загрузки данных в Caché, однако, как и отказ от использования блокировок и транзакций, требует известной осторожности, т.к.
отключение журнала приведет к отмене отката транзакций (TROLLBACK). Кроме того, на основе журнала функционирует механизм теневых серверов и останов журналирования приведет к тому, что теневые сервера не смогут получать данные от основного сервера.
До этого был рассмотрен довольно абстрактный случай создания набора экземпляров. В реальной жизни создаваемые экземпляры необходимо зачастую брать с внешних носителей информации. Например, для биллинговых систем типична ситуация загрузки данных о звонках из плоских файлов. Рассмотрим, каким образом данная задача может быть решена средствами Caché.
Допустим, что в плоском файле с разделителями хранятся данные о компаниях: название, адрес, ключевые цели и т.д. Наша задача – переместить эти данные из плоских файлов в объекты Caché. Для этого создадим описание класса с требуемыми полями (для простоты не будем определять индексы):
Class Test.B Extends %Persistent [ ClassType = persistent, ProcedureBlock ] { Property city As %String; Property company As %String; Property mission As %String; Property state As %String; Property street As %String; }
Листинг 8 Определение класса Temp.B
Для загрузки данных из плоского файла можно предложить следующий код:
Open AFileName Use AFileName Set i = 0 while $ZEOF'=-1 { Read result If $ZEOF>-1 { Set i = i + 1 Set ^Test.BD(i) = $ListBuild("",$Piece(result,ADelim,2),$ Piece (result,ADelim,1),$ Piece (result,ADelim,3),$ Piece (result,ADelim,4),$ Piece (result,ADelim,5)) } } Close AFileName Set ^Test.BD=I
Листинг 9 Загрузка данных из файла
Однако, в данном коде проводится довольно долгая операция разбиения строки с помощью операции $piece. В состав новой версии Caché 5.1 будет включена пара функций $listFromString и $listToString, которые сделают процесс преобразования строка «список более производительным. В среднем, в данном коде замена парсинга строки и последующей сборки списка на применение функции $listFromString может сэкономить до 10% времени выполнения.
Дополнительный прирост производительности можно достичь не построчным чтением файла, а блочным, что уменьшит количество обращений к диску.
Дополнительную оптимизацию можно провести для многопроцессорных машин. Если исходная задача позволяет провести распараллеливание, то загрузку данных можно разнести по нескольким процессам, каждый из которых будет управляться средствами операционной системы. В качестве дополнительного способа аппаратного ускорения загрузки данных можно предложить разнесение исходного файла и файла базы данных Caché на носители с разными контроллерами, что позволит обрабатывать эти файлы неконкурентно.
Выше были рассмотрены способы оптимизации массовой загрузки данных в Caché. Но возможности тонкой настройки систем при этом не исчерпываются. Можно улучшать не только процесс загрузки, но и саму обработку полученных данных.
Среди способов оптимизации на физическом уровне можно отметить дефрагментацию базы данных (утилита ^GCOMPACT), которая позволяет объединять разрозненные блоки, улучшая характеристики B *-дерева. Однако, здесь нужно помнить следующее правило: дефрагментация положительно сказывается на операциях поиска и отрицательно - на операциях добавления. Тем не менее, требуемого компромисса можно достичь благодаря тому, что утилита ^GCOMPACT позволяет «сжимать» блоки до определенного процентного соотношения (например, 80%).
В алгоритмическом плане может быть полезным использование временной базы данных («In - Memory Database») Caché TEMP. С точки зрения разработчика, эта база данных ничем не отличается от обычных баз данных, однако она полностью хранится в оперативной памяти и не журналируется, за счет чего и достигается большее быстродействие.
Для оптимизации SQL -доступа можно использовать следующие опции:
? установка параметров Selectivity и ExtentSize, которые используются Caché SQL оптимизатором при составлении планов запросов. Их можно установить либо вручную, либо автоматически с помощью утилиты $system.SQL.TuneTable().
? Директивы управления Caché SQL оптимизатором %inorder (формирование соединений JOIN именно в том порядке, как они записаны), %full (анализ всех возможных альтернативных планов запроса).
? Кэширование запросов.
? Создание хранимых процедур на Caché Object Script . В Caché существует возможность создания хранимых запросов не только на SQL , но и с использованием прямого доступа, что позволяет существенно повысить производительность хранимых процедур. При создании хранимых процедур, основанных на Caché Object Script, может быть полезным анализ сохраненных запросов, описанных в предыдущем пункте.
Итак, в этой статье мы рассмотрели набор рекомендаций для повышения производительности ваших систем на основе СУБД Caché. Безусловно, этот набор далеко неполный, но его можно считать базисом для улучшении своих систем. Необходимо помнить, что исключительно административные и технические улучшения не помогут построить действительно высокопроизводительные системы, так как в основе должна лежать именно алгоритмическая оптимизация. Использовать наилучшие алгоритмы - вот что требуется в первую очередь!
Caché и Веб-службы
Теперь перейдем непосредственно к применению технологии Веб-сервисов в Caché. Как упоминалось ранее, Caché может являться клиентом Веб-служб, т.е. обращаться к внешним по отношению к Caché сервисам. Также Caché может являться и сервером Веб-служб, т.е. предоставлять сервисы, которые будут доступны клиентским приложениям по протоколу SOAP. Для передачи сообщений по протоколу SOAP используется CSP-шлюз.
Реализация клиента и сервера Веб-служб в Caché построена с использованием объектной технологии. Каждому клиенту (серверу) Веб-служб в Caché соответствует специальный класс. Этот класс может содержать несколько методов, обозначенных ключевым словом WebMethod. Каждой операции, предоставляемой Веб-сервисом, соответствует свой собственный WebMethod. Таким образом, работа с классами, соответствующими клиенту и серверу Веб-служб в Caché, аналогична работе с остальными классами Caché.
Caché как клиент Веб-служб
Клиент Веб-служб в Caché представляет собой класс, наследуемый от системного класса %SOAP.WebClient и содержащий набор методов, отмеченных ключевым словом WebMethod. Каждый такой метод соответствует определенному методу Веб-сервиса на удаленной машине.
Для создания SOAP-клиента в Caché встроен специальный мастер. Мастер доступен из меню Caché Studio Инструменты->Расширения->1 SOAP Client Wizard. На первом шаге мастера указывается URL-адрес WSDL-документа соответствующего выбранному Веб-сервису. На основании WSDL-документа мастер создает класс с необходимыми Веб-методами, а также автоматически устанавливает значения параметров, определяющих имя удаленного Веб-сервиса, его расположение и пространство имен. Также может быть автоматически сгенерирован дополнительный класс (классы), если, например, при вызове метода Веб-сервиса необходимо передавать параметры определенного формата (например, строку определенного вида или значения из некоторого набора).
Ниже приведен пример класса, созданного мастером на основании WSDL-документа для Веб-сервиса, предоставляющего только одну операцию Sum, которая выполняет сложение двух целых чисел. Class.ArithmeticSOAP Extends %SOAP.WebClient
{/// URL-адрес для доступа к Веб-сервису.
Parameter LOCATION = "HTTP://MASHA:1972/csp/www/Web.cls";/// Пространство имен Веб-сервиса
Parameter NAMESPACE = "HTTP://tempuri.org"; /// Имя сервиса
Parameter SERVICENAME = ""; /// Метод, обращение к которому вызывает выполнение /// соответствующего метода Веб-сервиса
Method Sum(val1 As %Integer, val2 As %Integer)As %Integer
[ Final, ProcedureBlock = 1, SoapBindingStyle = document,
SoapBodyUse = literal, WebMethod ]
{
Quit ..WebMethod("Sum").
Invoke(##this,
"http://tempuri.org/Web.Arithmetic.Sum",.val1,.val2)
}
}
Вы можете создавать экземпляры созданного класса и вызывать методы класса-клиента. Например: WWW>Set client = ##class(Arithmetic.ArithmeticSoap).%New()WWW>Write client
1@Arithmetic.ArithmeticSOAP
WWW>Set result = client.Sum(1,-3)WWW>Write result -2
Caché как сервер Веб-службы
Сервер Веб-служб в Caché представляет собой класс, наследуемый от системного класса %SOAP.WebService и содержащий набор методов, отмеченных ключевым словом WebMethod. Каждый такой метод соответствует определенному методу Веб-сервиса. Целесообразно для каждого набора логически связанных методов создавать отдельный Веб-сервис (соответствующий класс).
Поскольку SOAP-протокол является “stateless”, т.е. не поддерживает состояния и не позволяет вызывать методы объекта, то WebMethod’ами могут быть только методы класса. Тем не менее, внутри WebMethod’а вы можете выполнять различные действия, в том числе создавать объекты, обращаться к БД, в том числе удаленной и т.д.
Для каждого класса, унаследованного от системного класса %SOAP.WebService, Caché автоматически создает WSDL-документ, определяющий список доступных внешним программам методов и формат их вызова.
На Рис.2 иллюстрируется механизм взаимодействия Веб-сервиса Caché и клиента.
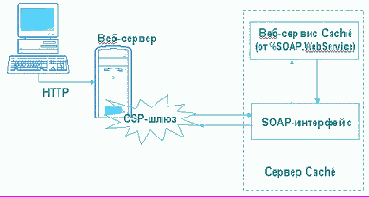
Рис.2. Принципы работы Веб-служб в Caché
Клиент запрашивает WSDL-документ с Веб-сервера, который, в свою очередь, запрашивает этот документ у сервера Caché. Используя информацию, предоставленную WSDL-документом, клиент вызывает нужный ему метод. Для вызова метода клиент создает XML-сообщение (SOAP-запрос), в котором указывается вызываемый метод и переданные этому методу параметры. Далее это сообщение отправляется серверу Caché по протоколу HTTP.
Сначала запрос передается на Веб-сервер, затем его перехватывает CSP-шлюз и перенаправляет на сервер Caché, где SOAP-запрос конвертируется в специальный вызов метода Веб-сервиса. Выполняется вызванный метод. В качестве значения, возвращаемого методом, может быть некоторое простое значение (например, число или строка символов) или набор объектов, представленный в виде XML. Для того, чтобы метод Веб-сервиса в качестве возвращаемого значения, возвращал экземпляр какого-либо класса, соответствующий класс должен быть унаследован от класса %XML.Adaptor.
Результат работы Веб-метода возвращается в виде XML-документа.
Основные параметры Веб-сервиса Caché:
LOCATION – URL, с которого Веб- сервис доступен клиенту. Значение параметра LOCATION включено в WSDL-документ. ("конверт"), который определяет содержание послания; NAMESPACE– определяет пространство имен Веб-сервиса. Используется для избежания конфликта имен с другими Веб-сервисами. SERVICENAME– определяет имя Веб-сервиса и должен являться “правильным” идентификатором Веб-сервиса, т.е. имя Веб-сервиса должно начинаться с буквы и состоять только из символов алфавита и цифр.
Ниже приведен пример класса, унаследованного от %SOAP.WebService, содержащего WebMethod Sum(), которому в качестве аргументов передаются два целых числа. Метод выполняет сложение этих чисел и возвращает полученный результат. Class Web.Arithmetic Extends %SOAP.WebService[ProcedureBlock]
{
/// SERVICENAME - Should be the name of the service for
which this is a proxy.
/// Override this parameter in the subclass.
Parameter SERVICENAME = "Arithmetic";/// сложение двух чисел
ClassMethod Sum(val1 As %Integer, val2 As %Integer)
As %Integer [ WebMethod ]
{{
s res="val1" + val2
q res
}}
}
Для того, чтобы протестировать работу созданного Веб-сервиса, откройте соответствующий класс в браузере (Рис. 3) (например, из меню Caché Studio View->Web Page). Для проверки работы нужного WebMethod’а воспользуйтесь ссылкой, соответствующей имени метода (Рис. 4). Как упоминалось ранее, при компиляции класса, соответствующего Веб-сервису, Caché автоматически создает для него WSDL-документ. Просмотреть содержимое WSDL-документа можно по ссылке Service Description. URL-адрес созданного WSDL-документа будет использоваться внешними приложениями для получения информации о вашем Веб-сервисе.

Рис. 3. Страница проверки Веб-сервиса

Рис. 4.
Проверка метода Sum()
В качестве результата выполнения метода Веб-сервис возвращает XML-документ, содержащий значение, возвращаемое вызванным методом, например:
<?xml version="1.0" encoding="UTF-8"?>
<SOAP-ENV:Envelope xmlns:SOAP-
ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:s="http://www.w3.org/2001/XMLSchema"> <SOAP-ENV:Body> <SumResponse xmlns="http://tempuri.org"> <SumResult>11</SumResult> </SumResponse> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
URL-адрес WSDL-документа формируется следующим образом: <URL-адрес страницы, соответствующей открытому в браузере
классу (Веб-сервису)>?W=1
Например:
http://127.0.0.1:1972/csp/web/Service.Arithmetic.CLS?WSDL=1
Для того, чтобы работать с созданным Веб-сервисом Caché из внешнего приложения, необходимо этому приложению указать адрес WSDL-документа вашего Веб-сервиса, что является стандартной процедурой для работы с Веб-сервисом независимо от технологии, используемой для его реализации. Например, вы можете обращаться к созданному Веб-сервису из .Net. Для этого в меню Visual Studio.NET выберите Project->Add Web Reference… В строку Address открывшегося окна скопируйте адрес Вашего WSDL-документа. Перейдите по введенному Вами адресу. В случае успеха в левой части окна у Вас откроется содержимое указанного WSDL-документа. А в правой части в списке доступных ссылок (Available references) отобразится введенная. Добавьте данную ссылку (кнопка Add Reference). После этого в вашем клиентском приложении будет создан класс, соответствующий Веб-сервису Caché. Таким образом в .NET создан SOAP-клиент для работы с сервисом Caché. Вы можете из вашего приложения вызывать методы созданного класса, которые, в свою очередь, будут вызывать методы Веб-сервиса Caché.
document.write('');
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
Использование Веб-сервисов в Caché
Гришина Мария,
Веб-сервис представляет собой набор логически связанных функций (методов), которые могут быть программно вызваны через Internet (или Intranet). Таким образом, программы, написанные на различных языках программирования, функционирующие на различных серверах под управлением различных платформ могут обращаться к какой-нибудь программе, работающей на другом сервере (т.е. к Веб-свервису), и использовать ответ, полученный от нее на своем Веб-сайте, или приложении.
Веб-сервисы представляют собой особый вид Веб-приложений для создания уровня бизнес-логики и связи разнородных приложений на основе использования общих стандартов, а также открытых протоколов обмена и передачи данных. В основе технологии Веб-сервисов лежит язык XML eXtensible Markup Language – расширяемый язык разметки. Обмен данными между приложениями осуществляется с помощью стандартного протокола HTTP и некоторых других Internet протоколов.
Например, если вам необходимо встроить в свое приложение переводчик слов на различные иностранные языки (или прогноз погоды, гороскоп и т.п.), вы можете решать задачу различными способами. Можете, например, самостоятельно реализовать такую функциональность, а можете воспользоваться услугами Веб-сервиса, к которому Ваше приложение будет обращаться через Internet. Передавая такому Веб-сервису запрос с параметрами, например, слово для перевода и интересующий иностранный язык, получаете ответ, в котором будет содержаться результат выполнения вашего запроса. Далее вам остается только “красиво” отобразить этот ответ в своем приложении. При этом вам совершенно не обязательно знать детали внутренней реализации используемого Веб-сервиса (под управлением какой платформы функционирует, на каком языке программирования написан и т.п.), достаточно только знать какой метод вам нужен и формат вызова этого метода.
Можно выделить следующие варианты использования Веб-сервисов:
a) Реализация сервисов и предоставление их “внешним” потребителям за определенную плату;
b) Построение распределенных систем (чтобы не дублировать службу на нескольких серверах, а обращаться к ней через сеть);
c) Интеграция приложений, созданных на различных технологиях, использующих для обмена информацией механизм Веб-сервисов.
В рамках данной статьи будут рассмотрены основные принципы функционирования Веб-сервисов (Веб-служб). А также рассмотрена возможность использования технологии Веб-служб в Caché. Caché может обращаться к внешним Веб-службам, опубликованным в сети Internet/Intranet, отправлять запросы, получать результаты, т.е. являться клиентом Веб-служб. При этом, приложение на Caché может предоставлять определенную функциональность (набор методов), доступную внешним программам через Internet/Intranet, т.е. являться сервером Веб-служб. Далее будут рассмотрены оба этих механизма.
Рис. 1 иллюстрирует общие принципы работы механизма Веб-сервисов.
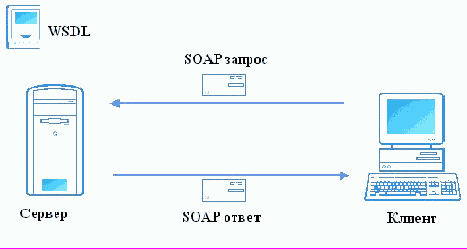
Рис. 1. Общие принципы работы Веб-служб
Итак, есть определенный сервер Веб-сервисов, реализующий некоторую функциональность (содержащий набор методов) и доступный в сети Internet/Intranet.
Для описания методов, опубликованных на данном сервере, а также формата их вызова используется специальный язык WSDL (Web Services Description Language). В основе языка WSDL лежит XML. Каждому серверу Веб-служб соответствует свой собственный WSDL-документ, на основании которого клиент формирует запросы к данному сервису.
Клиент (любой компьютер в сети) формирует запрос и отправляет его серверу Веб-служб. Для передачи запросов используется SOAP-протокол (Simple Object Access Protocol) – простой протокол доступа к объектам. Сообщение SOAP является обычным XML-документом, следовательно, не зависит ни от языка ни от платформы.
Веб-сервис обрабатывает запрос, выполняет заданную последовательность действий (например, проверку номера кредитной карточки, перевод текста с одного языка на другой, конвертацию арабских цифр в римские и т.п.), формирует ответ и отправляет обратно клиенту. Для отправки ответа также используется SOAP-протокол.
В основе механизма Веб-сервисов лежат три основные понятия: XML (eXtensible Markup Language), WSDL (Web Services Description Language) и SOAP (Simple Object Access Protocol).Рассмотрим их основные характеристики.
SOAP (Simple Object Access Protocol)
SOAP - это основанный на XML протокол, который позволяет взаимодействовать различным приложениям на основе стандарта HTTP.
объектам” (Simple Object Access Protocol) и предназначен для коммуникациями (передачи информации) между удаленными объектами. Использование HTTP является наиболее удобным способом коммуникации между приложениями, поскольку протокол HTTP поддерживается всеми Веб-браузерами и серверами. SOAP представляет собой способ коммуникации между приложениями на базе протокола HTTP и некоторых других Internet-протоколов, а использование XML в качестве основы SOAP позволяет ему работать под управлением различных операционных систем, на основе различных технологий и языков программирования.
Таким образом, протокол SOAP позволяет обмениваться сообщениями между клиентом и сервером. Сообщение SOAP является обычным XML-документом. Этот документ состоит из следующих XML-элементов:
SOAP header ("заголовок", не обязательный элемент), в нем содержится заголовочная информация; SOAP envelope ("конверт"), который определяет содержание послания; SOAP body ("тело"), в нем содержится информация вызовов и ответов на вызовы.
Сообщения между сервером Веб-служб и клиентом пакуются в SOAP-конверты (SOAP envelopes). Сообщения содержат либо запрос на осуществление какого-либо действия, либо ответ - результат выполнения этого действия. Конверт и его содержимое закодировано языком XML. Ниже приведен простой пример SOAP-запроса GetTranslation, который отправляется через HTTP к Веб-сервису. Здесь запрашивается перевод слова помидор с русского языка на английский. <soap:Envelope>
<soap:Body>
<xmlns:m="http://www.somesite.org/translation" />
<m:GetTranslation>
<m:Word>помидор</m:Word>
<m:Language>RussianTOEnglish</m:Language>
</m:GetTranslation>
</soap:Body>
</soap:Envelope> Также приведен пример SOAP-ответа на данный запрос. <soap:Envelope>
<soap:Body>
<xmlns:m="http://www.somesite.org/translation" />
<m:GetTranslationResponse>
<m:Translation>tomato</m:Translation>
</m:GetTranslationResponse>
</soap:Body>
</soap:Envelope>
Элемент <m:GetTranslation> в запросе поменялся на элемент <m:GetTranslationResponse> в ответе на запрос. В этом элементе содержится только один элемент <m:Translation>, значение которого и обозначает запрашиваемый перевод слова помидор с русского языка на английский. Таким образом, с помощью SOAP мы сформировали запрос в виде XML, передали его серверу Веб-служб и получили определенного вида ответ на языке XML. При этом, наша программа должна была только сформировать запрос и передать его серверу, никаких обращений, например, к БД наша программа не производила, а получила сразу готовый, структурированный специальным образом, результат.
WSDL (Web Services Description Language))
WSDL расшифровывается как Язык Описания Веб-сервисов (Web Services Description Language).
Документ WSDL является XML-документом, описывающим Веб-сервис, т.е. содержит набор выражений, определяющих Веб-сервис. Он определяет расположение сервиса и операции (или методы), предоставляемые им, а также формат их вызова. На основании WSDL-документа клиентом осуществляется выбор необходимого метода, из предоставленных сервером Веб-служб, и формируются запросы к данному Веб-сервису.
Общая структура WSDL-документа может быть представлена следующим образом:
<definitions>
<types>
Описание типов данных, используемых Веб-сервисом.
</types>
<message>
Описание сообщений, используемых Веб-сервисом.
</message>
<portType>
Описание операций (методов), предоставляемых Веб-сервисом
</portType>
<binding>
Описание протоколов связи, используемых Веб-сервисом
</binding>
</definitions> WSDL-документ может также содержать и некоторые другие элементы.
Ниже приведен пример WSDL-документа, описывающего Веб-сервис, предоставляющий всего одну операцию Sum (сложение двух целых чисел).
<?xml version="1.0"encoding="UTF-8" ?>
<definitions xmlns:http=
"http://schemas.xmlsoap.org/wsdl/http/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/" xmlns:s="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:s0="http://tempuri.org"
xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/" xmlns:mime="http://schemas.xmlsoap.org/wsdl/mime/"
targetNamespace="http://tempuri.org" xmlns="http://schemas.xmlsoap.org/wsdl/">
//Описание типов данных аргументов метода и возвращаемого
//значения
<types>
<s:schema elementFormDefault="qualified"
targetNamespace="http://tempuri.org">
// Методу Sum передаются два аргумента val1 и val2 с
//указанными типами данных
<s:element name="Sum">
<s:complexType><s:sequence>
<s:element name="val1" type="s:long"
minOccurs="0" />
<s:element name="val2" type="s:long"
minOccurs="0" />
</s:sequence>
</s:complexType>
</s:element>
// Описание типа данных возвращаемого методом значения
<s:element name="SumResponse">
<s:complexType>
<s:sequence>
<s:element name="SumResult" type="s:long"
minOccurs="0" />
</s:sequence> </s:complexType>
</s:element>
</schema>
</types>
// Описание входящего сообщения метода Sum
// С входящим сообщением ассоциирован тип данных Sum
<message name="SumSoapIn">
<part name="parameters" element="s0:Sum" />
</message>
// Описание исходящего сообщения метода Sum
// С исходящим сообщением ассоциирован тип данных SumResponse
<message name="SumSoapOut">
<part name="parameters" element="s0:SumResponse" />
</message>
// Описание операций (методов), предоставляемых Веб-сервисом
<portType name="ArithmeticSoap">
// Данный Веб-сервис предоставляет операцию Sum
// Операция имеет входящее сообщение SumSoapIn
// И исходящее сообщение SumSoapOut
<operation name="Sum">
<input message="s0:SumSoapIn" />
<output message="s0:SumSoapOut" />
</operation>
</portType>
// Определение формата сообщения и деталей протокола для
//каждого порта
<binding name="ArithmeticSoap" type="s0:ArithmeticSoap">
<soap:binding transport="http://schemas.xmlsoap.org/soap/http"
style="document" />
<operation name="Sum">
<soap:operation soapAction="http://tempuri.org/Web.Arithmetic.Sum"
style="document" />
<input>
<soap:body use="literal" />
</input>
<output>
<soap:body use="literal" />
</output>
</operation>
</binding>
// Определяет имя сервера Веб-служб, позволяет объединить
//внутри себя несколько портов (наборов методов), определяет
//расположение сервиса
<service name="Arithmetic">
<port name="ArithmeticSoap" binding="s0:ArithmeticSoap">
<soap:address
location="http://MASHA:1972/csp/www/Web.Arithmetic.cls" />
</port>
</service> </definitions>
XML (eXtensible Markup Language)
XML - это eXtensible Markup Language, в переводе “расширяемый язык разметки”. XML создан для описания данных и фокусируется на том, что именно эти данные из себя представляют.
Внешне XML-документ напоминает HTML-документ. XML-документ, также как и HTML-документ, является обычным текстовым файлом, в котором содержится набор тегов и данные, заключенные между этими тегами.
При этом, если в HTML набор тегов фиксирован, то в языке XML теги не заданы с самого начала. Разработчик XML-документа должен определить свои собственные теги, необходимые для описания заключенной в документе информации.
Язык XML был создан для структурирования, хранения и передачи информации. Больше XML не выполняет никаких функций, в частности, XML не является, например, языком программирования, и только с его помощью не возможно производить операции над данными, заключенными в XML-документе.
XML можно считать неким промежуточным звеном между форматом представления данных, предназначенным для восприятия человеком (например, текстовым документом), и неким бинарным кодом, используемым для представления встроенных типов данных языков программирования.
Ниже представлен пример записки (note) от Алексея к Наталье, сохраненной в виде XML-документа. У записки есть заголовок (heading) и содержательная часть (body). Кроме того, в ней содержится информация об отправителе (from) и получателе (to). Такой XML-документ просто структурирует определенную информацию (данные упакованы в XML-теги) и больше ничего не делает. Для того, чтобы такую записку отправить, получить или “красиво” отобразить на экране нужно написать специальное программное обеспечение.
<?xml version="1.0"?>
<note>
<to>Алексей</to>
<from>Наталья</from>
<heading>Напоминание</heading>
<body>Истекает срок арендной платы!</body>
</note>
Одним из преимуществ языка XML является возможность его использования различными программами независимо от используемого языка программирования и платформы, под управлением которой эти программы функционируют. И еще одним несомненным преимуществом XML является гарантированная доставка XML-документа методами Сети, в частности HTTP.
