Реализации объектов.
Реализация объекта обеспечивает само понятие объекта, обычно задавая данные для конкретного экземпляра объекта и код для выполнения методов объекта. Часто реализация будет использовать другие объекты или вспомогательные программы для обеспечения функционирования объектов. В некоторых случаях выполнение операции над объектом влечет некие побочные действия не над объектами.
Конкретный ORB может поддерживать широкий набор объектных реализаций: отдельные серверы, библиотеки, объектно-ориентированные системы управления базами данных и др. С помощью использования дополнительных Адаптеров Объектов теоретически можно поддерживать любую реализацию объекта.
Реализация с использованием версий
Функциональные update-выражения допускают эффективную реализацию на основе использования версий узлов XML-документа. Неформально алгоритм можно сформулировать следующим образом. Функциональные update-выражения возвращают последовательность новых узлов {N}, возможно, изменяя некоторые узлы {I}, содержащиеся внутри этих узлов.
Тогда:
для каждого из изменяемых узлов i последовательности {I} стоится узел i', соответствующий измененному состоянию, и помечается некоторым номером версии x; изменяемые узлы из последовательности {I} в исходном документе не изменяются; каждый узел из последовательности {N} помечается номером версии x и возвращается как часть результата; для каждого функционального update-выражения номер версии новых узлов больше номеров версий, использовавшхся в предшествующих update-выражениях; начальное состояние данных соответствует некоторой нулевой версии; При навигации по данным, начиная с некоторого начального узла, выбираются узлы с версией, номер которой равен или меньше номера версии начального узла.
Такой подход наименьшим образом ограничивает семантику функциональных update-выражений, но требует сложной реализации с поддержкой версий. При таком подходе в выражениях доступно как начальное, так и измененное состояние данных, и возможна произвольная композиция выражений, что обеспечивает наибольшую выразительность расширенного языка.
Регистр
В XML различаются символы верхнего и нижнего регистров. Все ключевые слова XML состоят из символов верхнего регистра. Символы в именах тегов должны набираться на том же регистре, что и в определении DTD. В предыдущем примере имена сущностей/таблиц состоят из символов верхнего регистра, а имена атрибутов/столбцов - из символов нижнего регистра. Можно было бы сделать и по-другому.
Релевантность полнотекстового поиска: подход на основе построения терминологической базы документов
С.И.Моисеенко (), А.Майстренко ()
Донской государственный технический университет
В основе предлагаемого подхода лежат две базовые идеи:
Использование возможностей SQL-запросов к реляционным базам данных при осуществлении поиска.
Любой текст можно описать посредством предметного указателя (мы избегаем здесь использовать английский аналог предметного указателя - index, чтобы это не вызывало аналогии со структурами хранения информации во внешней памяти).
Первый пункт предполагает, что необходимая для поиска информация о документе должна содержаться в базе данных. Это даст возможность использовать средства СУБД, связанные с индексированием таблиц и оптимизацией запросов, что в идеале должно обеспечить оптимальную скорость выполнения последних.
Второй пункт связан с вопросом о том, что следует хранить в базе данных, а точнее, в полях таблицы базы данных. Современные серверы БД практически не ограничивают объемы информации, которую можно записать в поле таблицы базы данных. Так, например, IBM DB2 Universal DataBase позволяет хранить неструктурированные текстовые документы объемом до 2 Гбайт [1]. Однако такими возможностями обладают далеко не все СУБД. Кроме того, для эффективного поиска в таких полях, так или иначе, необходимы некоторые вспомогательные структуры хранения данных, построение которых берет на себя СУБД. Эти структуры могут находиться как в базе данных, так и в файловой системе.
Мы исходим из того, что хранить документы в базе данных - излишняя роскошь. Достаточно хранить только ссылки (URL) на документы. Здесь, конечно, могут возникнуть непринципиальные в рассматриваемом контексте проблемы, связанные с изменением местоположения документов. Мы также считаем неэффективным сохранение в базе данных всего словарного множества документа, предлагаемого в работе [2], отдавая должное простоте реализации и быстродействию алгоритма индексирования.
Здесь дело не только в том, что в базу данных попадут одинаковые слова, имеющие разные падежные окончания и т.п.
Причем проблему "избыточности" нельзя решить с помощью уникального индекса. Помимо этого такая база данных будет содержать много излишней информации. Это глаголы, служебные слова, местоимения и т.д. В качестве подтверждения сказанного рассмотрим предметный указатель, эффективно используемый для поиска в научно-технической литературе. Предметный указатель это, по сути дела, терминологическая база данного текста. Она включает базовые термины (существительные) и уточненные термины (существительные с определяющими их прилагательными и, возможно, предлогами).
В данной статье предложен алгоритм создания поисковой базы данных документов, построенной по принципу формирования предметного указателя и содержащей как базовые термины, так и их уточнения.
Сама структура такой поисковой словарной базы должна обеспечить не только быстрый, но и релевантный поиск. Релевантность обусловлена еще и тем, что при формировании терминологической словарной базы конкретного документа сохраняется не только сам термин, но и частота его вхождения в документ. Поэтому при выполнении поиска, можно упорядочить его результаты по частоте вхождения искомого термина в документ. Кроме того, можно ввести некоторое пороговое значение f (например, f > 1), которое должно использоваться в качестве критерия отбора записей в поисковом запросе. Причем на это не потребуется дополнительных затрат времени. Основные временные затраты придутся не на поиск, а на предобработку документа (формирование предметного указателя), которая осуществляется не в реальном времени выполнения запроса, а один раз при регистрации документа в системе.
Чтобы сформировать терминологическую базу данных, требуется решить следующие задачи:
Определить часть речи слова в документе (морфологический анализ); Выяснить, что является составным термином (синтаксический анализ). Предполагается, что простым термином является существительное. С составным же термином дело обстоит сложнее, поскольку нужен достоверный критерий того, какая последовательность слов является терминологически связанной. Как хранить термин, чтобы слова с разными падежными и т.д.
окончаниями записывались в базу данных один раз. Заметим, что эта же проблема должна решаться и при поиске. Например, запрос на поиск слова "программа" должен учесть также и слова: "программе", "программы", "программах" и т.д.
Морфологический анализ можно реализовать, оценивая окончания слов в документе [3]. Для неоднозначно трактуемых слов можно использовать специальную таблицу в БД с атрибутами слово и часть речи, и при анализе просматривать сначала ее, а затем (если слова там нет) выполнять оценку по окончанию слова. В этой же таблице будут находиться и незначительное число слов, принадлежащих неизменяемым частям речи, таким как междометие, наречие и т.п.
При выявлении составных терминов мы исходим из следующих предположений:
термин должен находиться между знаками препинания; в составе термина не должно быть междометий, вводных и служебных слов, союзов и глаголов, которые исключаются на стадии формирования поискового образа документа (см. ниже). Возможно расширение списка слов-разделитетей; составной термин должен включать существительное; порядок слов составного термина может быть произвольным.
Эти предположения можно реализовать с помощью следующего алгоритма формирования терминологической базы данных.
На первом шаге выполняется создание поискового образа документа (ПОД) [3] из копии исходного. ПОД - это информационное наполнение документа, т.е. в нем уже не содержится междометий, вводных и служебных слов и т.д. (смотри выше). При этом исключаемые слова в ПОД заменяются (если они не находятся в начале или конце предложения) некоторым разделительным символом для дальнейшего выявления многословных терминов. Можно для всех исключаемых слов использовать один и тот же символ (например, запятую), чтобы упростить синтаксический анализ.
На втором шаге анализируются фрагменты текста между разделительными символами. Извлекаются любые последовательности слов, среди которых есть существительное. Именно эти последовательности заносятся в таблицу Term (термин).
Одновременно с этим можно формировать таблицу TermInDoc (термин в документе), в которой, помимо идентификатора термина (внешний ключ), в поле freq будет подсчитываться частота вхождения термина в документ (смотри рисунок). Заметим, что на основе морфологического анализа в таблицу Term заносятся лишь основы слов (PhraseBase), составляющих термин, т.е. всем терминам, отличающимся только падежными окончаниями, соответствует одна запись в этой таблице.

Рис.1. Логическая схема базы данных поисковой системы
Дадим некоторые пояснения к ER-диаграмме (в нотации IDEF1X), представленной на рис.1. Идентификатор связи Р между таблицами Document и TermInDoc означает "один или более", т.е. любой документ должен содержать термины. По сути дела это означает, что при регистрации документа в БД всегда должно выполняться построение его терминологической базы. Если, что маловероятно, при анализе документа термины обнаружены не будут, то данный документ просто не следует включать в БД.
Каждый конкретный термин из таблицы Term может содержаться в любом количестве документов. Допустимо также его отсутствие в таблице TermInDoc. Такая ситуация возможна в следующих случаях:
частота вхождения термина в документы ниже выбранного порогового значения; таблицу Term можно пополнять "вручную", т.е. не выбирая слова из документов. Это может иметь место при формировании экспертами терминологической базы некоторой предметной области или при создании словарных баз для программ-переводчиков.
Атрибут Doc_Ref в таблице Document содержит ссылку на местоположение оригинала документа в файловой системе или сети.
Наконец, из таблицы TermInDoc удаляются все записи с частотой вхождения ниже некоторого порогового значения. То есть предполагается, что термины, которые встретились в документе, скажем, один раз, неадекватно характеризуют его содержание. Пороговое значение можно подобрать эмпирически. В этом случае пороговое значение представляет собой постоянную величину (например, единица).
Недостатком постоянного порогового значения является то, что в небольших документах может вообще не оказаться терминов с частотой, выше порогового значения. Однако нельзя сказать, что такие документы вообще не несут никакой информации. Найти выход можно с помощью переменного порогового значения, принимающего некоторое значение в интервале между максимальной и минимальной частотой терминов в данном документе. Такое пороговое значение будет являться характеристикой документа. Кроме того, можно определить пороговое значение для совокупности документов [3].
При поиске будет проверяться только наличие термина (терминов) в таблице TermInDoc. Результатом выполнения запроса будет список документов, содержащих образец поиска, который действительно адекватно их характеризует, чем, как нам представляется, обеспечивается высокий уровень релевантности.
Как говорилось выше, список документов, отвечающих запросу, можно упорядочить в соответствии с частотой вхождения термина в документ или же в соответствии с весом данного термина (который можно определить, например, как отношение частоты вхождения термина в документ к числу терминов в документе).
Естественно, при данном подходе не на любые запросы будет получен ответ. Например, если образец поиска будет содержать только исключаемые из ПОД слова. Но, с другой стороны, какой смысл можно усмотреть в поиске документов по словам: "например" или "следовательно"? Кроме того, учет таких слов может привести к ошибочному выполнению запроса. В качестве примера рассмотрим поиск по словам "можно" и "термин". Ясно, что если поиск ведется по вхождению в документ, хотя бы одного из двух терминов, то возможно, что он весь будет состоять из документов, содержащих слово "можно" (причем с достаточно высокой частотой вхождения) и не содержащих слово "термин". Если же критерий поиска построен на вхождении в документ обоих слов, то релевантность такого поиска может вызвать сомнения. Не будет удивительным, если частота вхождения слова "можно" значительно превысит частоту вхождения слова "термин", в результате чего наверху списка окажутся документы, имеющие меньшую релевантность относительно слова "термин".
Следует отметить критичность данного алгоритма по отношению к точности определения части речи и правильности исключения "незначимых" слов.
В первую очередь сложность вызывает определение критерия, который позволил бы отличить существительное от прилагательного. Причем дело здесь не только в том, что существительное и прилагательное могут иметь в предложении одинаковые окончания, т.е. морфологический анализ в этом случае не сможет нам помочь, но и в том, что существительное и прилагательное могут быть представлены одним и тем же словом. Так слово "данные" в термине "экспериментальные данные" является существительным, а в словосочетании "данные нам в ощущениях" - прилагательное.
Для четкой идентификации части речи потребуется достаточно сложный синтаксический анализ. Его можно избежать, если оставлять в базе данных все отдельные слова и словосочетания в ПОД между разделяющими символами (смотри выше). По сравнению с первоначальным методом в предметный указатель попадут не только существительные, а также словосочетания, которые, возможно, будут содержать несколько терминов и то, что термином не является. Однако поставленная цель эффективного и релевантного поиска от этого не становится дальше. Мы ничего не теряем, поскольку терминологическая база может лишь незначительно увеличиться (отдельных слов станет больше, а словосочетаний - меньше).
В заключение скажем, что предложенный способ формирования поисковой базы данных документов позволит находить документы, когда поисковым образом является отдельное слово, несколько слов, словосочетание, а также слова, которые должны находиться поблизости друг от друга. В последнем случае анализируются словосочетания в терминологической базе данных.
Цитируемые источники
Игнатович Николай. DB2 Universal Database - ключевые характеристики.
Игумнов Евгений. Основные концепции и подходы при создании контекстно-поисковых систем на основе реляционных баз данных.
Корнеев В.В., Гареев А.Ф., Васютин С.В., Райх В.В.Базы данных. Интеллектуальная обработка информации. - М.: "Нолидж", 2000. - 352 с.
Реляционная и Обьектная модели - разные модели
Реляционная и объектная модели относятся к разным уровням моделирования прикладной области. Реляционная модель относится к логическому уровню моделирования, объектная модель является концептуальной. Для того чтобы более четко определить разницу между этими моделями рассмотрим системы, основанные на них.
Системой можно назвать множество закономерностей определяющих существование и взаимодействие элементов этой системы. Для того, чтобы описать некую систему, введем следующие операции.
Операция ADR(X) (где X - элемент системы) является необходимой и достаточной для однозначной идентификации элемента Х системы, т.е. ADR(Xi)

= Xj). Возвращает величину необходимую для однозначной идентификации элемента X.
Операция IS(X) возвращает тип элемента Х. Поскольку тип можно определить как множество имен атрибутов, то можно сказать, что в системе существует некое множество являщееся объединением всех множеств имен атрибутов всех типов, которое в дальнейшем будем называть пространством определения типов. Таким образом операция IS(X) проецирует элемент X на простанство определения типов.
В случае O-систем операция ADR(X) возвратит уникальное значение А ( или OID) объекта Х или, говоря по другому, спроецирует объект Х на адресное пространство ( пространство значений OID ) системы. Можно сказать, что результатом операции ADR(X) будет (А) где A - адрес. Исходя из определения операции ADR(X), действительным является выражение Аi
и Aj следует что IS(Ai) = IS(Aj). Для сохранения адресов используются элементы особого базового типа - ссылки или указатели.
Следует сказать, что в общем случае пространство определения типов О-системы является сложным и многомерным, что следует из многобразия способов типообразования в этой системе.[5,18] Одним из этих способов является наследование. Этот способ присущ только О-системам и позволяет при определении новых типов использовать уже существующие, более общие по смыслу, базовые типы.
Благодаря наследованию в О-системах один и тот же атрибут может быть определен в разных типах. На иллюстации класс В является наследником класса А и поэтому атрибут I определенный в классе А определен также и в классе-наследнике В. [1,5,16]
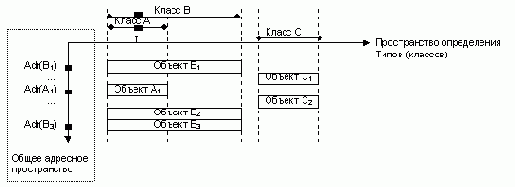
Рис 1. Простейшая реализация O-системы
Для того чтобы изобразить пространство R-системы необходимо вспомнить о ключе.Это понятие является одним из основных для R-систем и определяется следующим образом: ключом отношения называют такое подмножество внутри множества имен атрибутов отношения, что кортежи отношения могут быть однозначно определены значениями соответствующих атрибутов этого подмножества. Таким образом ключ состоит из набора значений которые однозначно определяют любую строку таблицы. Определенное значение ключевого поля (или полей), принадлежащих записи некоторой таблицы, позволяет найти эту запись внутри этой таблицы.[1,4]
Для однозначной идентификации кортежа Х некоторого отношения R операция ADR(X) должна вернуть выражение вида (R,K), которое звучит как "Ключ K кортежа X отношения R где R = IS(X)" . На этом определении основывается понятие внешнего ключа, который может быть назван R-аналогом ссылок и указателей O-систем. Определение подобного рода позволяет ввести в R-системы (рис. 2) механизм поддержки ссылочной целостности не позволяющий присвоить ссылке(внешнему ключу) значение выходящее из области значений первичного ключа соответствующего отношения.

Рис 2. R-система
Если сравнивать пространства R- и O- систем то можно отметить два различия:
в O-системе объекты существуют в едином адресном пространстве в то время как в R-системе для каждого отношения существует свое собственное пространство значений первичного ключа. Можно сказать, что в O-системе адресное пространство является характеристикой присущей системе в целом и понятие "адрес" вводится до начала описания каких-либо классов, в то время как в R-системе пространство первичного ключа отношения R является характеристикой только этого отношения и и оно не определено до описания самого этого отношения.
Данные рассуждения верны также и для элементов системы позволяющих сохранять адрес. Существующий в O-системах ссылочный тип данных определяется системой и не зависит от типа объектов на который ссылка указывает. Возможно объявить неопределенную ссылку (в C++ - это указатель void* ) или на класс, который является базовым для любого другого класса и существует в системе по умолчанию (в Java - ссылка на объект класса Object). В R-системах внешний ключ должен быть связан с первичным ключом определенного отношения, и следовательно может быть объявлен только после того как это отношение описано.
В пространстве определения типов: рис.1 иллюстрирует наследование - одно из ключевых понятий O-систем. На рисунке класс B является наследником класса А.
Основные свойства системы, объединяющей R- и O- системы, должны складываться из свойств присущих каждой из этих систем в отдельности. Следовательно
все данные, имеющиеся в такой системе должны быть представлены как объекты прозвольной структуры.
все данные, имеющиеся в такой системе должны быть представлены в виде реляционных переменных [9]
Кажется, что наиболее простым путем создания системы имеющей свойства R- и O-систем будет расширение R-системы за счет введения в нее общего адресного пространства и применения к отношениям операции наследования. Рассмотрим это подробнее.
Создание общего адресного пространства в R-системе
Расcмотрим пару (R,K) подробнее. Поскольку она описывает результат операции ADR(X), однозначно идентифицирующей кортеж Х внутри системы, можно сказать что (Ri,Ki)
поскольку в них могут существовать такие Ki
и Kj что IS(Ki)
Эти рассуждения приводят нас к введению в R-систему понятия RecID - идентификатора, позволяющего однозначно определить любой кортеж системы. Следует заметить, что поле содержащее RecID является ключевым для любой таблицы хотя может быть и не определено явно как ключ.
Введение RecID не представляет особой сложности. Смысл, однако, заключается не в самом RecID. Важным является возможность использовать его значение для инициализации ссылок (или указателей), которые позволяют другим частям системы обращаться к данному кортежу. Можно рассмотреть два случая:
ссылочный элемент, содержащий RecID, является внешним ключом (здесь RecID должен являться первичным ключом некоторого отношения R). Следовательно этот элемент может ссылаться на кортежи только одного отношения (этого отношения R). Можно сказать, что здесь теряется смысл RecID, как элемента позволяющего идентифицировать любой кортеж любого отношения;
ссылочный элемент не является внешним ключом. Конечно, этот элемент может ссылаться на любой кортеж, существующий в системе. Однако в данном случае отсутствует контроль ссылочной целостности, и возможно такая ситуация когда ссылка указывает на отсутствующий кортеж.
Применение наследования для отношений
Взглянем еще раз на рис.(1) описывающий пространство O-системы. Класс B является наследником класса А. Таким образом для операции IS(Bi) (где Вi - объект класса B) возможно два варианта правильного ответа - класс А и класс В. Можно сказать, что IS(Bi) = IS(Aj) в то время как IS(Ai)
Применим к отношениям наследование и определим отношение Rn+1 как наследник Rn. Из этого следует что для кортежа Х относящемуся к Rn+1 действительным будет IS(X) = IS((Rn)X) и в в то же время IS((Rn)X)
Тогда операции ADR(Х) возвратит пару (Rn+1, K) где K - ключ кортежа Х в адресном пространстве отношения Rn+1=IS(X). Соответственно ADR((Rn)Х) возвратит пару (Rn, K) где K - тот же самый (поскольку он наследуется) ключ в адресном пространстве отношения Rn=IS((Rn)X). Сравнение этих пар приведет к следующему выводу : ADR(Х) = ADR((Rn)Х) и в то же время ADR((Rn)Х)
= Xj) где Xi и Xj - элементы системы) данный вывод говорит о принципиальной невозможности применить к отношениям операцию наследования. Можно сказать, что элемент реляционной системы (кортеж) описываемый типом R, в связи с особенностями адресации (пара (R,K) ), может входят только в одно множество R которое определяется существованием данного типа (схемы отношения) R. Таким образом тип отношения и тип класса не могут быть одним же типом. Это является достаточным, для того что бы сказать, что реляционная и объектная модели являются разными моделями.
Однако, поскольку разные модели могут одновременно использоваться для описания одного и того же набора данных, можно предположить, что для этого могут использоваться реляционная и объектная модели. Для этого эти модели следуют рассматривать как ортогональные. И для того, что бы соотнести эти модели вспомним о том, что
Структуру любой сложности можно нормализовать
Блок информации любой сложности можно сохранить как набор записей различных таблиц.[2,1] Говоря по другому любой объект можно представить как набор кортежей различных отношений. Эта идея является основой проектирования реляционных БД и используется с момента их создания. По мнению автора именно эту идею нужно рассматривать как основу для создания системы объединяющей свойства объектных и реляционных систем. Причина, по которой существующие в настоящее время реляционные системы не обладают объектными свойствами заключаеться не в том, что эта идея является неверным.
Она является неполной.
Для того чтобы понять что имеется в виду, вернемся к примеру с программой сохраняющей свои данные в ОЗУ. Мы можем сказать, что в ОЗУ может быть сохранена любая информация (во всяком случае до сих пор это удавалось). Соответсвенно информация о некотором моделируемом объекте (здесь мы исходим из того, что любая программа в той или иной мере является способом моделирования некой предметной области) представляет из себя некоторое множество элементов ОЗУ. Важным является тот факт, что это верно для любой программы, будь она написана на Си, FORTRAN или ассемблере (все эти языки используют разные парадигмы программирования и не являются объектными) - в любом случае некоторому моделируемому объекту можно поставить в соответствие некоторое множество элементов ОЗУ, сохраняющие данные о этом объекте. Преимущество объектных систем заключается в том, что только они позволяют явно поставить в соответсвие объекту моделируемой области ИДЕНТИФИЦИРУЕМЫЙ и ОСМЫСЛЕННЫЙ(или, по другому, ИМЕЮЩИЙ ОПРЕДЕЛЕННУЮ СТРУКТУРУ) набор элеметов ОЗУ, который также (в терминах О-систем) называется объектом.
Аналогичные рассуждения верны и для объекта, данные о котором необходимо сохранить в реляционной базе данных. Из того факта, что информация о объекте с произвольной внутренней структурой может быть сохранена в реляционной системе, необходимо сделать следующий вывод: любому объекту можно поставить в соответствие ИДЕНТИФИЦИРУЕМЫЙ и ОСМЫСЛЕННЫЙ набор кортежей.
Рассмотрим это положение по частям:
объект есть идентифицируемый набор кортежей. Набору кортежей содержащему данные о некотором объекте можно поставить в соответствие уникальный идентификатор, который фактически является объектным идентфикатором(OID), используя который мы можем обращаться к даному набору кортежей;
объект есть осмысленный набор кортежей. Объект описывается типом, каждому атрибуту которого ставиться я в соответствие определенное семантическое значение. Это семантическое значение определяет смысл кортежа в объекте и ,кроме того, позвляет обращаться к этому кортежу как к атрибуту объекта.
Очень важно понимать, что речь здесь идет о смысле, который присущ кортежу как атрибуту обьекта. Дело в том, что любой кортеж может обладать собственным смыслом, и этот смысл определяется отношением в которое этот кортеж входят. Кортеж сам по себе является семантически значимым набором данных. И этот осмысленный набор данных осмыслен также в контексте обьекта, атрибутом которого он является. В этом нет никакого противоречия. Рассмотрим следующий пример.
Некоторая организация занимается рассылкой корреспонденции. Для каждого клиента определен адрес, по которому эту корреспонденцию нужно высылать. Клиенты могут быть как юридическими, так и физическими лицами. В контракте на обслуживание юридических лиц необходимо указывать регистационную информацию, включающую юридический адрес. В контракте для физических лиц необходимо указывать их паспорные данные. Возможная иерархия классов в О-системе моделирующей деятельность фирмы выглядит следующим образом (в скобках указана сохраняемая информация):

В каждый объект класса "Юридическое лицо" будет входит три набора данных, три поля, каждое из которых содержит определенную информацию об этом объекте: 1) фактический адрес 2) регистационная информация 3) юридический адрес. Каждый из этих наборов данных содержит информацию о их состоянии в процессе определенного взаимодействия с другими объектами окружающего мира, информацию определяющую возможность этого взаимодействия. Говоря по другому, каждый из этих наборов данных содержит информацию об одной из многих сущностей этого объекта.
Рассмотрим поля содержащие юридический и фактический адреса. В принципе, почтовая корреспонденция может быть послана по любому из этих адресов. Структура этих полей абсолютно одинакова. Эта структура определяется их собственным смыслом (т.е. их смыслом вне объекта, атрибутами которого являются эти поля), определяется их сущностью, которая может быть выражена словом "адрес". Информация содержащаяся в таких полях является достаточной для установления определенной связи (например почтовой) с содержащими их объектами.
Чтобы послать письмо важно наличие у объекта-получателя поля с сущностью "адрес", а какой объект - человек или фирма - данным адресом идентифицируется, какой текст находится в письме, что представляет данный адрес в контексте объекта - вся эта информация совершенно неважна для того чтобы письмо было послано по почте объекту, которому этот адрес принадлежит. Разница между этими полями (в одном случае адрес является юридическим, в другом - фактическим) существует только если рассматривать их в контексте объекта. Именно класс определяет по какому из этих адресов письмо должно быть послано.
Обратим особое внимание на то, что вне контекста класса все информационное содержимое полей, имеющих сущность "адрес", определяется только содержащимися в них данными. Только эти данные являются существенными.[11] Из этого следует, что в сущности адрес имеет реляционную природу и может рассматриваться как схема соответсвующего отношения. Тоже можно сказать и про сущность "регистрационная информация".
Рассмотрим наш пример более формально. Существует класс A описывающий клиентов, которым надо рассылать корреспонденцию.. Этот класс включает поле X1 содержащее фактический адрес клиента; это поле является котрежом отношения ADDR соответствующего сущности "адрес". Существует производный класс В (фирма) включающий поле X2 (юридический адрес) являющееся кортежом того же отношения ADDR и поле Y1 являющегося кортежом другого отношения LegIn соответствующего сущности "регистрационная информация". Создадим объект ОА класса А идентифицируемый OID1
и объект ОВ класса В идентифицируемый OID2.
В нашем примере мы имеем дело и с классами (объектная модель) и с отношениями (реляционная модель). Поскольку объектная и реляционная модели могут рассмариваться только как ортогональные, этот пример может быть проиллюстрирован следующим образом (рис. 4)
Реляционная модель выдержит испытание временем
The relational model will stand the test of time
C.J. Date
()
Я посвятил несколько заметок историческому обзору и анализу нескольких статей Кодда о реляционном подходе (по крайней мере, наиболее важных статей). Более конкретно, обсуждались следующие статьи:
"Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks" "A Relational Model of Data for Large Shared Data Banks" "Relational Completeness of Data Base Sublanguages" "A Data Base Sublanguage Founded on the Relational Calculus" "Further Normalization of the Data Base Relational Model" "Interactive Support for Nonprogrammers: The Relational and Network Approaches" Extending the Relational Data Base Model to Capture More Meaning"
Время от времени я касался и других статей.
Пришло время завершить эту серию. В заключительной заметке я хотел бы сформулировать основные цели, которые ставились при создании реляционной модели, и обсудить, насколько хорошо она удовлетворяет этим целям (или не удовлетворяет). Кроме того, я хотел бы коротко обсудить, что в точности представляет собой реляционная модель и в каком направлении она могла бы развиваться. Мне хочется, чтобы серия целиком рассматривалась как дань уважения огромным достижениям Кодда в создании, больше частью, в одиночку практически всей области современного управления базами данных - области, в которой все мы напряженно трудимся и из которой черпаем средства для существования. Спасибо, Тед!
Reminiscences on Influential Papers
Richard Snodgrass, editor
Я попросил нескольких известных и представительных людей из сообщества баз данных выбрать одну статью, которая оказала основное влияние на их исследования, и описать, что в этой статье понравилось и как она на них подействовала. Эти отзывы подчеркивают, что исследования включают сильный эмоциональный компонент, включающий радость, красоту, изумление и дружественные чувства, иногда все это сразу.
Serge Abitboul, INRIA,
[A.K. Chandra and D. Harel, "Computable Queries for Relational Data Bases", Journal of Computer and System Sciences 21(2):156-178, 1980]
Статьи Чандры и Харела 1980-го и 1982-го годов являются очень важными. В то время у нас было очень ограниченное представление о языках запросов. Оно главным образом происходило от начальных статей Кодда. Кодд неявно наложил некоторые ограничения на языки запросов - "полноту запросов по Кодду". Поскольку его работа являлась математически обоснованной, имелось некоторое нежелание ее оспаривать. Та идея, что можно определить класс запросов независимо от конкретного языка, была чем-то новым. Выдвинув ее, Чандра и Харел открыли простор для большого числа работ по выразительности и сложности. Некоторые из введенных ими методов оказалось возможно применить в большом разнообразии контекстов.
Sophie Cluet, INRIA,
[B.P. Jenq, D. Woelk, W.Kim and W-L. Lee, "Query Processing in Distributed ORION", in Proceedings of the Conference on Extending Data Base Technology, pp. 169-187, Venice, Italia, 1990
Некоторые люди говорят, что в модели ODMG не поддерживается декларативный язык запросов (но на самом деле поддерживает: OQL), в то время как в объектно-реляционном подходе такая поддержка имеется (будет иметься в будущем: SQL3). Другие распространяют слухи о том, что объектно-ориентированные запросы невозможно оптимизировать. В этой статье, явившейся поворотным пунктом, доказывается, что это утверждение истинно настолько же, что и то, которое часто приходилось слышать в 70-х про невозможность эффективной реализации SQL.
Дженк, Воулк, Ким и Ли были первыми, кто установил важный и часто игнорируемый факт: навигационные запросы и запросы с соединениями эквивалентны. Другими словами, методы реляционной оптимизации могут быть применены к OQL. В действительности, поддержка как ассоциативного, так и навигационного доступа - это источник дополнительной оптимизации. Объекты можно хранить на дисках многими разными способами. Если некоторые объекты кластеризованы вместе со своими компонентами, навигационные запросы наболее более эффективны, чем любые запросы с соединениями, которые можно было бы выполнить над двумя отношениями, хранящими ту же самую информацию. И наоборот, если они хранятся на разных страницах, то можно полагаться на соединения, чтобы получить та же эффективность, которой обладают реляционные системы. Следовательно, можно обладать лучшим из двух миров. Разве это не прекрасно?
Michael Franklin, University of Maryland,
[G. Copeland and D. Maier, "Making Smalltalk a Database System", In Processing of the ACM SIGMOD Conference on Management of Data, pp. 316-325, 1984]
Я впервые увидел эту статью в 1985-м или 1986-м году будучи студентом Wang Institute. Я тратил много времени на два прекрасных курса: Первый читался Филом Бернстайном (Phil Berstein) и посвящался обработки транзакций; курс основывался на только что завершенной книге, написанной совместно с Хадзилакосом (Hadzilacos) и Гудманом (Goodman). Вторым был семинар по объектно-ориентированным языкам программирования. В это время эти две темы казались совершенно несвязанными -- курс по базам данных ориентировался на пуленепробиваемые приложения в стиле COBOL, которые казалось более естественно писать ЗАГЛАВНЫМИ БУКВАМИ, в то время как у системы Smalltalk имелся удобный графический интерфейс и естественный способ моделирования данных, но можно было пропускать только игрушечные программы. Когда я впервые увидел статью Коупленда и Майера, я был поражен, обнаружив, что они пытаются соединить эти два мира. Однако в статье содержались убедительные аргументы в пользу того, что это естественное и важное дело.
После окончания учебы я охотно принял предложение работать над развитием этих идей в MCC с Джорджем и группой Bubba.
Эта статья является одной из классических работ, которые побуждают многих людей переоценить свои базовые предположения. В добавлению к выявлению проблемы "потери соответствия" (impedance mismatch) между процедурными языками и системами баз данных и предложению устранить эту проблему в статье также описываются языковые конструкции и архитектура, позволяющие добиться этой цели. Результирующая система включала определяемые пользователем расширения типов с методами, иерархией типов, доступом к историческим данным, а также единообразный язык для запросов к базе данных, навигации и программирования в целом. Хотя имелись предшествовавшие работы по развитию реляционной модели и добавлению долговременного хранения (persistence) в языки программирования, эта статья была потрясающей основы в своей попытке гладко объединить идеи из баз данных, языков программирования и операционных систем таким способом, чтобы можно было поддерживать широкий спектр приложений. Сегодняшние системы баз данных, вообще говоря, не прошли весь путь к уменьшению потери соответствия, но идеи статьи явно повлияли на направление развития области исследований и индустрии. Статья напоминает, что для достижения прогресса мы должны постоянно иметь в виду ограничения, порождаемые текущими технологией и образом мышления.
Guy Lohman, IBM Almaden Research Center,
[P.G. Selinger, M. Astrahan, D. Chamberlin, R. Lorie, and T. Price, "Access Path Selection in a Relational Database Management System", In Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 23-34, Boston, 1979]
В этой статье обобщается то, как в System R оптимизировались SQL-запросы, и теперь это, вероятно, наиболее часто цитируемая статья в области оптимизации реляционных запросов. Поэтому не удивительно, что она оказала очень значительное влияние на мою карьеру, даже несмотря на то, что в то время я не работал в IBM и даже не начал заниматься оптимизацией запросов.
Лично на меня громадное впечателение произвела презентация статьи, сделанная Пат (Патрицией Селинджер); наш диалог в результате привел к тому, что Пат стала моим менеджером, когда я включился в ее проект R* в IBM в 1982 г. Наше сотрудничество, уважение и дружба растут до сих пор.
Но важность этой статьи для всей области исследований существенно затмевает ее влияние на меня лично. В процессе тщательного изучения мой экземпляр истрепался и покрылся незначительными комментариями. После многократного перечитывания я продолжаю поражаться тому, как удалось поместить в эту статью глубокие и правильно обдуманные решения, как много идей, впервые отчетливо выраженных в статье, выдержало испытание временем и конкуренцией. Теперь у каждого крупного поставщика СУБД имеется оптимизатор запросов, в котором применяется большинство фундаментальных концепций, введенных в этой статье: использование статистической информации базы данных и моделирование стоимости выполнения -- а не упрощающих правил -- чтобы устранить большую часть стратегий доступа; избежание Декартовых произведений и применение динамического программирования и повторного использование подпланов для сокращения экспоненциального пространства поиска альтернативных порядков соединения; оценка мощности промежуточных результатов на основе вероятностных "показателей фильтрации"; распознавание планов, имеющих различные "интересные" порядки; выявление того, как предикаты могут быть применены наиболее эффективно (и создание памятного термина SARG; от "Search ARGument"); конвейеризация промежуточных результатов для избежания материализации; вычисление вложенных подзапросов; и много других деталей, которые невозможно здесь перечислить. Хотя за последние двадцать лет каждое из этих новшеств было усовершенствовано, выносливость исходных идей, по-моему мнению, является просто замечательной. Это поистине плодотворная работа.
David Lomet, Microsoft Research,
[J. Cray, "Notes on Database Operating Systems", IBM Technical Report RJ2188, 1978.
Also published in Operating Systems: An Advanced Course. Springer-Verlag Lecture Notes in Computer Science. Vol. 60. New York.]
К концу 70-х - началу 80-х существовала горсточка успешных транзакционных систем баз данных - IMS, System R, Ingres, Oracle. Однако магика того, как в этих системах реализовывались транзакции, была, за исключением одной статьи, глубоко запрятана в недра реализаций систем. Этим исключением была статья "Notes", написанная Джимом Греем. Здесь впервые были собраны в одном месте протоколы фиксации, управление параллельным доступом и восстановление. Действительно, до этой статьи в литературе содержалось исключительно мало информации о восстановлении. По одной этой статье можно было образоваться по поводу журнализации с упреждающей записью, протокола журнализации DO-REDO-UNDO, установки контрольных точек для восстановления, рестартов, нескольких видов двухфазной фиксации, мультигранулированных блокировок, строгой двухфазной фиксации и т.д. Можно было также узнать про восстанавливаемые сообщения, управление записями и про множество системных деталей. В статье не только описывались решения трудных проблем, но объяснялось что и почему является важным.
Я жадно читал статью "Notes", когда она появилась (и, конечно, не один я) и возвращался потом к ней снова и снова. Сейчас статья немного устарела, ее частично потеснила статья про восстановление в System R, книга Бернстайна, Хадзилакоса и Гудмена и полностью затмила фундаментальная книга книга самого Джима (написанная совместно с Андеусом Рейтером [Andreas reuter]). Но статья "Notes", которая не появилась на конференции или в журнале, была единственной наиболее полезной статье в литературе по базам данных для целого поколения исследователей систем транзакций и разработчиков, среди которых и я. Действительно, мой интерес к проблемам восстановления зародился при чтении этой статьи, так что она продолжает влиять на направления моих исследований до сегодняшнего дня.
Gultekin Ozsoyoglu, Case Western Reverse University,
[J.M. Smith, and D.C.P. Smith, "Database Abstractions: Aggregation and Generalization", ACM Transactions on Database Systems 2(2):105-133, June 1977]
Я читал статью Смита и Смита, когда искал тему своей диссертации на степень PhD в 1977 г. Эта статья производила исключительное впечатление своей глубиной, завершенностью и оригинальностью рассуждений при введении "иерархии абстракций агрегации и обобщения объектов" в моделировании данных. Хотя в статье эти иерархии применялись к реляционной модели и вводились "реляционные инварианты", на самом деле речь шла о семантическом моделировании данных на основе объектов, т.е. об объектно-ориентированных базах данных! Я помню, что тем летом читал статью несколько раз. В следующие годы я постоянно возвращался к этой статье, и в обязательном порядке заставлял читать ее студентов.
Статья Смита и Смита оказала существенное воздействие на мои исследования в период PhD и позже. В конце концов моя диссертация PhD оказалась связанной с безопасностью статистических баз данных. В то время из-за потребности в формальном анализе управления выводом в большинстве исследований безопасности статистических баз данных использовались простые модели данных статистических баз данных. Выбранное мной направление исследований основывалось на использовании более развитых моделей данных с привлечением, в частности, родовых иерархий статьи Смита и Смита, причем гарантировалось управление выводом. Для меня с этого началась длинная полоса исследований безопасности статистических баз данных, которая продолжалась до середины 80-х.
Raghu Ramakrishnan, University of Wisconsin,
[F. Bancilhon, D. Maier, Y. Sagiv, J.D. Ullman, "Magic Sets and Other Strange Ways to Implement Logic Programs", In Proceedings of the ACM Principles of Database Systems Symposium, pp. 1-16, 1986]
Я присоединился к группе LDL компании MCC в Остине (Austin) в 1985 г., будучи студентом старших курсов UT-Austin. Конечно, я искал тему для дипломной работы и кое-что делал как в области баз данных, так и в области логического программирования.
Поэтому я был подготовлен к восприятию идей этой изящной статьи. В статье показывалось, что распространение связывания, достигаемое в Прологе, может поддерживаться путем простых преобразований программ для некоторого класса программ и утверждалось, что методы реализации баз данных (например, методы эффективных соединений) могут быть применены для рекурсивных запросов.
Впоследствии я снова и снова возвращался к этому вопросу, пытаясь обобщить подход для более широких классов программ и понять его последствия в более общем контексте управляемых стратегий поиска. Эта статья оказала влияние и на ряд других исследователей, и сегодня во многих коммерческих системах применяются варианты идеи магических наборов. Для меня эта статья всегда будет помниться как научившая меня тому, что исследовательская работа может быть приятной, а простые идеи могут иметь глубокие последствия.
Ken Ross, Columbia University,
[C. Nyberg, T. Barclay, Z. Cvetanovic. J. Gray, D. Lomet, "AlphaSort: A Cache Sensative Parallel External Sort", In Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 603-627, 1994, and later in the VLDB Journal 4(4):603-627 (1995)]
Лично для меня основным воздействием статьи про AlphaSort явилось понимание того, что поведение кэша существенно влияет на эффективность операций с массивными данными. Меня особенно впечатлил ясный способ управления поведением кэша, при котором достигается высокий процент попадания в кэше на требуемые данные. Я могу предвидеть наступление времени, когда для многих разумных приложений вся база данных сможет располагаться в основной памяти. В этом контексте поведение кэша было бы критическим фактором производительности, поскольку разница в скорости процессора и основной памяти увеличивается (за последние 12 лет на два порядка). Это наблюдение относится не только к сортировке, но ко всем операциям над базой данных. Эффективность кэша сейчас является центральной темой моего нового проекта баз данных в основной памяти в Коламбии.
Timos Sellis, National University of Athens,
[A. Guttman, "R-trees: a dynamic index structure for spatial searching", In Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 47-57, 1984]
Понятно, что в течение академической карьеры на каждого из нас оказывало влияние множество статей. Когда Рик попросил меня выделить только одну из них, я выбрал именно ту, которая повлияла на большую часть моих исследований, а именно, на мою работу в области методов пространственного доступа. Я имел счастье познакомиться с Антонином Гуттманом при подготовке моей диссертации PhD в Беркли, и у меня были хорошие возможности обсудить с ним свойства R-деревьев. Причиной того, что мне с первого чтения понравилась эта статья, состоит в том, что она посвящена очень важной и трудной проблеме - индексированию многомерных простанств, в которых невозможно определить очевидный порядок сортировки - и в ней предлагается изящный, понятный и элегантный метод решения проблемы. С моей точки зрения, эта работа открыла целую новую область исследований, которые привели к появлению известных удобных структур данных и алгоритмов, которые применяются даже в коммерческих системах. 15 лет спустя можно видеть, что продолжают появляться статьи, посвященные усовершествованиям и приложениям R-деревьев (в картинно-графических, пространственных, темпоральных базах данных, а также и более "экзотических" областях, таких, как хранилища данных), продолжая очень интересную линию исследований, начатую Антонином в его статье 1984-го г.
Patrick Valduriez, INRIA,
[M.M. Zloof, "Query-By-Example: Operations on the Transitive Closure", IBM Research Report RC 5526, Yorktown heights, New York, October, 1976, and in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 47-57, 1984]
Как и многие французы, по своему воспитанию я ценю изящество и простоту, что, например, выражается в приверженности к изысканному сыру, хлебу и вину. Я думаю, что это помогло мне в исследовательской карьере при изобретении просто реализуемых структур данных и алгоритмов.Статья Злуфа является хорошим примером научного изящества и простоты. Я прочитал ее в 1985 г. в MCC, стараясь определить практические аспекты дедуктивных баз данных, которые являлись тогда горячей темой. Во-первых, дедуктивные базы казались мне сложными и непрактичными. Написанная за много лет до появления моды на рекурсивные запросы, статья Злуфа показывала, что мощные, хотя и простые, формы рекурсии могут быть естественным образом добавлены в реляционный язык, основанные на исчислении доменов. Тогда можно расширить реляционную алгебру операцией транзитивного замыкания и разработать соответствующие структуры данных и алгоритмы. Это сильно повлияло на мою работу в области алгоритмов транзитивного замыкания, индексов соединения и языка программирования баз данных Faq. Доказательство практической значимости работы является недавнее добавление транзитивного замыкания к SQL в качестве стандартной конструкции.
Решение проблемы комплексного оперативного анализаинформации хранилищ данных
С. Д. Коровкин, И. А. Левенец, И. Д. Ратманова,
В. А. Старых, Л. В. Щавелёв
Управление любой сложной социально-экономической системой - от предприятия до региона или отрасли - весьма затруднительно без обратной связи, которая заключается в отслеживании и анализе данных, отражающих состояние этой системы и ситуацию вокруг нее. Постоянная доступность актуальной информации дает возможность оценить текущее положение дел, а обзор изменения конкретных характеристик во времени позволяет обнаружить тенденции развития системы и сделать выводы о том, что ожидает ее в будущем. Таким образом, обладая всей полнотой сведений о состоянии системы и ее элементов в статике и динамике, управляющий персонал может принимать грамотные решения по применению мер регулирования. Такое управление основано на знании и потому более эффективно, чем принятие важных решений вслепую.
На современном этапе проблемы ведения баз данных (БД) оперативной информации на разных уровнях управления перестали быть непреодолимыми. Более того, разработана концепция Хранилищ Данных - архитектура построения корпоративных информационных систем, получившая развитие вследствие желания конечных пользователей иметь непосредственный единообразный доступ к необходимым им данным, источники происхождения которых организационно и территориально распределены, а анализ которых может способствовать принятию решений [10]. Билл Инмон, автор концепции Хранилищ Данных, определил их как "предметно ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные с целью поддержки управления", призванные выступать в роли "единого и единственного источника истины", обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений [8]. Ричард Хакаторн, другой основоположник этой концепции, писал, что цель Хранилищ Данных - обеспечить для организации "единый образ существующей реальности" [7].
В этом контексте наиболее актуальной проблемой является обеспечение интегрированного взгляда на сложный объект управления в целом, комплексного анализа собранных о нем сведений и извлечения из огромного объема детализированных данных некоторой полезной информации - знаний о закономерностях его развития.
Поддержка принятия управленческих решений на основе накопленной информации может осуществляться в трех основных областях [9].
Область детализированных данных. Это сфера действия большинства транзакционных систем (OLTP), нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами.
Область агрегированных показателей. Комплексный взгляд на собранную в Хранилище Данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP) [5, 4]. Здесь можно или ориентироваться на специальные многомерные СУБД, или (что, как правило, предпочтительнее) оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной БД.
Область закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining) [3], главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или (с определенной вероятностью) прогнозируют развитие рассматриваемых процессов.
Программный комплекс ИнфоВизор является инструментальной оболочкой для создания информационно-аналитических систем (ИАС), покрывающих все перечисленные типы обработки данных. Основой представления информации о структуре используемых совместно с инструментарием ИнфоВизора реляционных БД являются метаданные - навигационные (предназначенные для задач поиска и модификации данных), аналитические (созданные для реализации многомерного анализа накопленных сведений) и операционные (обеспечивающие наполнение хранилища данных из внешних информационных источников в автоматическом режиме по заранее утвержденным сценариям). Благодаря наличию таких метаданных практически любая непротиворечиво спроектированная БД может быть адаптирована к использованию в качестве содержательного наполнения ИАС на основе этого инструментария.
Таким образом достигается инвариантность программного обеспечения по отношению к структуре представления исходной информации.
Являясь большим программным комплексом, ИнфоВизор состоит из ряда программных продуктов, которые могут использоваться автономно или совместно, взаимодействуя и дополняя друг друга.
ИнфоВизор-Загрузка. Для наполнения централизованного хранилища данных и постоянного поддержания его в актуальном состоянии почти всегда требуется регулярно обновлять его содержание свежей информацией из информационных источников - баз данных уровня подразделения или проблемно-ориентированных баз. Данный продукт позволяет создавать и автоматически выполнять сценарии обновления информации хранилища. Администратор базы данных формирует регламент загрузки новой информации из источников (операционные метаданные), после чего запланированные действия автоматически выполняются в нужные моменты времени. Таким образом, предлагаемый инструмент дает возможность решить задачу интеграции и согласования разрозненных данных.
ИнфоВизор-Реестр. Этот продукт предназначен для обслуживания и использования корпоративных информационно-поисковых систем в рамках хранилища данных. По мнению авторов, наиболее адекватно информационные сущности описываются с помощью иерархии объектов. Не случайно именно иерархическое представление принято в моделировании для анализа структуры сложных систем. В свое время такой подход был успешно реализован в отечественной СУБД ИНЕС [2], а сегодня используется в СУБД Datacom/DB компании Applied Data Research, Inc. (ADR) и Adabas компании Software AG [1], а также в некоторых постреляционных СУБД. В данных системах логическое представление информации в виде иерархической модели соответствует физическому методу хранения данных. Однако, по многим причинам, практически всегда кажется более предпочтительным вести Хранилище Данных с помощью серверов реляционных СУБД: во-первых, в настоящее время ряд ведущих производителей этих серверов (Informix, Oracle, Sybase и др.) значительно вырвались вперед по сравнению со своими конкурентами по уровню производительности машин баз данных; во-вторых, Хранилища Данных практически всегда создаются в качестве настройки над множеством существующих систем обработки данных (СОД) [4], которые производят обслуживание проблемно-ориентированных (ведомственных) реляционных баз данных с помощью унаследованных систем (legacy systems); наконец, язык SQL для реляционной модели является единственным языком манипулирования данными, имеющим общепринятый мировой стандарт.
Поэтому было принято решение, оставаясь на реляционной платформе, воспользоваться преимуществами иерархического и сетевого подхода в процессах семантического моделирования структуры хранилища данных и навигации по находящимся там информационным объектам.
Решение данной проблемы может быть получено путем введения слоя навигационных метаданных между физическим хранилищем и программными приложениями его обработки, который обеспечивал бы оперативную трансляцию реляционных данных в термины более естественной семантической модели. Вид этой семантической модели наиболее адекватно отражается метафорой дерева смысловых атрибутов, то есть аналогом традиционной иерархической модели хранения данных. Можно сказать, что на новом витке спирали исторического развития мы в некоторой степени возвращаемся к незаслуженно забытым идеям иерархического и сетевого подхода к построению информационных систем.
Поскольку практически любая реляционная база данных может быть описана слоем навигационных метаданных и представлена как иерархия связанных друг с другом атрибутов информационных объектов, подсистемы ввода данных, корректировки и поиска информации не должны изменяться при модификации структуры базы данных или при изменении потребностей пользователей в подробностях получаемой информации.
ИнфоВизор-Аналитик. Если предыдущие инструменты имели дело с детализированными данными, то ИнфоВизор-Аналитик в первую очередь предназначен для комплексного многомерного анализа численной агрегированной информации, то есть является системой класса ROLAP - оперативной аналитической обработки реляционных данных.
Авторами разработан оригинальный механизм извлечения агрегированной многомерной информации любой степени обобщения из реляционных БД произвольной структуры. Идея системы ИнфоВизор-Аналитик заключается во введении в Хранилище Данных аналитических метаданных, которые содержат набор информационных моделей ("виртуальных звезд"), позволяющих извлекать из него обобщенную численную информацию в многомерном базисе измерений.
За основу аналитических метаданных взято понятие многомерного гиперкуба. Осями гиперкуба (атрибутами информационной модели) могут быть любые способы консолидации данных [5], представляемые справочниками экземпляров некоторых объектов (множеством точек оси). Одной из осей гиперкуба может являться время, что позволяет анализировать динамические процессы. Совокупность выбранных экземпляров от каждой оси однозначно характеризует ячейку гиперкуба в пространстве объявленных атрибутов. Каждая ячейка гиперкуба может содержать численное значение - показатель, - смысл которого определяется координатами ячейки - набором экземпляров, по одному от каждого атрибута.
Получение значений показателей производится по результатам SQL-запросов к реляционной БД, которые автоматически генерируются ядром системы, исходя из диалогового запроса пользователя-аналитика к информационной модели. При этом результирующими значениями показателей информационной модели могут быть:
значения полей численного типа БД (предварительно агрегированные значения);
функции агрегирования SQL (avg, count, max, min, sum, а также другие функции агрегирования, поддерживаемые SQL-сервером [6]);
формулы (SQL-выражения, имеющие на выходе одно численное значение).
Атрибут - это один из признаков показателя, который может быть представлен в виде оси информационной модели. В литературе его часто называют измерением. Но в предлагаемой нами концепции понятие измерения более сложно: на этапе обработки ранее извлеченной информации и формирования отчетов измерения могут быть не только получены непосредственно из атрибутов, но и являться группировками нескольких независимых осей - атрибутов. Это делается для снижения общего количества измерений гиперкуба ради удобства конечного пользователя (довольно трудно манипулировать абстрактными пространствами с высокой мерностью).
Для обеспечения возможности рассматривать показатели с разными степенями агрегации реализация каждого атрибута, в общем случае, может быть выполнена с помощью нескольких конкретных справочников экземпляров - различных уровней обобщения атрибута.
Так, атрибуту "Местоположение" можно поставить в соответствие несколько реализаций - уровень детализированного справочника СОАТО, уровень городов и районов, уровень субъектов Российской Федерации и так далее. Атрибут "Время" может иметь уровни обобщения с точностью до года, квартала, месяца и так далее.
Результаты серии SQL-запросов, сформированной по каждому конкретному оперативному заказу аналитика (диалоговому запросу), имеют совершенно идентичный формат (набор полей идентификаторов экземпляров справочников выбранных уровней обобщения выбранных атрибутов плюс целевое поле показателя), поэтому могут быть составлены в одну временную таблицу (например, оператором UNION), которая в совокупности со справочниками уровней обобщения атрибутов может рассматриваться как самостоятельная база данных, имеющая схему звезды (Star Scheme) [4, 5]. Тот факт, что центральная таблица этой БД является временной, то есть оперативно создается и заполняется по требованию аналитика в ответ на его нерегламентированный запрос, является основанием наименования описанного метода - "Концепция виртуальной звезды". Таким образом, предлагаемая концепция является целостным законченным оригинальным способом реализации гибких информационно-аналитических систем класса OLAP. Система ИнфоВизор-Аналитик основывается именно на этой концепции.
Новизна предлагаемого подхода "виртуальной звезды" по сравнению с существующими механизмами, реализованными в продуктах OLAP, заключается в следующем.
Введение понятий группируемого справочника уровня обобщения атрибута и области однородности извлечения значений позволяет в рамках одной информационной модели обращаться к значениям трех типов: 1) предварительно агрегированным в полях численного типа, 2) полученным в результате оперативной агрегации в процессе выполнения запроса и 3) являющимся результатами расчета заданных формул. Таким образом, построенный пользователем диалоговый запрос может возвратить значения, принадлежащие ко всем этим типам, в рамках одного гиперкуба.
При этом в процессе построения информационной модели можно достичь допустимого компромисса между быстротой доступа к заранее агрегированным значениям и актуальностью значений, агрегируемых оперативно. Даже для разных экземпляров одного справочника одной оси могут быть заданы различные методы доступа, исходя, например, из частоты обращения к соответствующим значениям.
Реализация гибкого механизма группировки атрибутов - элементарных измерений - в процессе рассмотрения сформированного гиперкуба в укрупненные измерения позволяет существенно понизить его мерность и облегчить восприятие конечным пользователем содержащейся в нем информации.
Разработанная авторами система ИнфоВизор-Аналитик реализует клиентскую часть описанной OLAP-системы и позволяет производить оперативный многомерный анализ численных данных реляционных БД произвольной структуры. Этот продукт доступен в варианте двухзвенной архитектуры "клиент-сервер" и в варианте для архитектуры . Установка intranet-версии продукта на web-сервере - может одновременно обслуживать большое количество удаленных пользователей, которым необходим лишь сетевой навигатор на рабочем месте.
Ядро ROLAP-системы обеспечивает извлечение агрегированных показателей в многомерном базисе измерений. В таком виде численная информация удобна для просмотра и построения отчетов, но в том, что касается собственно аналитической обработки, продукты ROLAP сами по себе могут выполнять только простейшие действия. Для сложных способов анализа информации инструментарий ROLAP может рассматриваться исключительно как средство подготовки исходного материала. Поэтому ядро системы ИнфоВизор-Аналитик реализовано таким образом, что к нему могут обращаться внешние модули интеллектуального и проблемно-ориентированного анализа. Дополнение системы такими модулями в каждом конкретном случае ее применения позволяет перейти в область закономерностей и решать задачи из сферы Data Mining.
ИнфоВизор-Администратор. Этот продукт является основным инструментом администратора хранилища данных.
С его помощью могут создаваться и редактироваться информационные модели, составляющие навигационные и аналитические метаданные, а также сценарии загрузки информации из внешних источников - операционные метаданные.
Список литературы
Л. Л. Винокуров, Д. В. Леонтьев, А. Ф. Гершельман. СУБД ADABAS - основа универсального сервера баз данных // . - 1997. - №2. - С. 36-40.
Н. Е. Емельянов. Введение в СУБД ИНЕС. - М.: Наука, 1988.
Н. Кречетов, П. Иванов. Продукты для интеллектуального анализа данных // . - 1997. - N 14-15. - С. 32-39.
А. А. Сахаров. Концепции построения и реализации информационных систем, ориентированных на анализ данных // . - 1996.- N 4. - С. 55-70.
E. F. Codd, S. B. Codd, C. T. Salley. Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate. - E. F. Codd & Associates, 1993.
J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, F. Pellow, H. Pirahesh. Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals // . - 1997. - N 1. - P. 29-53.
D. Hackathorn. Reinventing Enterprise Systems Via Data Warehousing. - Washington, DC: The Data Warehousing Institute Annual Conference, 1995.
W. H. Inmon. Building The Data Warehouse (Second Edition). - NY, NY: John Wiley. - 1993.
K. Parsaye. New Realms of Analysis: Surveying Decision Support // . - 1996. - N 4. - P. 26-33.
N. Raden. Данные, Данные и только данные // . - 1996. - №8. - С. 28.
Революция
По отношению к технологии процессоров считалось, что будущее за RISC-технологией. Ожидалось, что к 1991 году компьютер с производительностью в 50 MIPS и основной памятью размером с гигабайт будет стоить меньше 100000 долларов.
Как мы видим, этот прогноз не сбылся. Во-первых, большая часть рынка процессоров занята суперскалярными микропроцессорами Intel. Во-вторых, уменьшение соотношения цена-производительность происходило гораздо быстрее, и по моим понятиям сегодня машину с такими показателями можно купить раз в десять дешевле.
Общим мнением было то, что потребности приложений будут возрастать не медленнее снижения цены аппаратуры, и поэтому потребуется соответствующая исследовательская работа в области баз данных.
Да, и это привело к появлению таких промышленных технологий, как параллельные sharing-nothing системы баз данных.
Отмечалась возможность широкого внедрения систем поддержки принятия решений по мере снижения цен аппаратуры.
Действительно, это произошло. Достаточно заметить то, что все ведущие производители СУБД предлагают свои решения для реализации хранилищ данных.
Считалось, что объемы требуемых баз данных будут возрастать быстрее снижения цен на дисковую и основную память и поэтому по-прежнему потребуются исследования, направленные на повышение эффективности баз данных.
Так оно и есть. Большая часть исследовательских работ компаний-производителей СУБД связана с повышением производительности.
Должность администратора БД бесспорно может
Должность администратора БД бесспорно может считаться одной из самых недооцениваемых на предприятии. Этот человек в ответе практически за все, что только может пойти не так. Довольно неблагодарно считать устойчивое функционирование системы само собой разумеющимся фактом, а противоположную ситуацию - исключительно виной администратора БД. АБД нуждается в разнообразии средств, способных сделать его работу более продуктивной и избавить от авралов по вечерам и выходным. Кроме того, инструментальные средства позволяют АБД сосредоточится на выполнении своих непосредственных обязанностей вместо того, чтобы заниматься “пожаротушением”, решением неотложных проблем и выполнением рутинных, но от этого не менее подверженных ошибкам, процедур, таких как резервное копирование и реорганизации.
Роль администратора базы данных (АБД)
Дэн Хотка
(The DBA Role, by Dan Hotka)
Источник: сайт pinnaclepublishing.com, журнал Oracle Professional, October 2001
В этот раз Дэн Хотка окинет свом пристальным взглядом администраторов баз данных, предложив Вашему вниманию краткий обзор специализаций, обязанностей и должностей, характерных для данной профессии.
Среди моих работ есть доклад, называющийся "Роль администратора БД", который я иногда читаю, если ко мне обращаются с просьбой провести презентацию тематического характера. Мне кажется, что предлагаемый материал может оказаться довольно полезным для членов сообщества Oracle Professional . Статья дает общее представление о том, чем занимается администратор БД, его обязанностях и специализации относительно реляционных БД Oracle. По окончании доклада многие слушатели подходят ко мне со словами: "Как жаль что здесь нет моего начальника, чтобы он мог это услышать". Так вот теперь он сможет это прочитать!
Роль администратора в управлении БД Oracle
Существует множество спецализаций, связанных с Oracle-приложениями, начиная, в первую очередь, непосредственно с самих конечных пользователей. Вот кто настоящие клиенты администратора. Если Вы имеете дело с Интернет-системой, то иногда прямая связь с пользователями просто невозможна. Предполагается, что все люди, о которых идет речь в этой статье, работают в одной компании. Так вот, пользователям необходим доступ к отдельным объектам базы данных, составляющим их приложение. Обязанность администратора обеспечить им необходимые права для выполнения соответствующих операций. Кроме того, администратор может взаимодействовать с пользователями по вопросам, касающимся функционирования БД и уж тем более когда он выполняет мероприятия по настройке системы.
В крупных вычислительных центрах имеется "справочный стол", своего рода "передовая линия" в борьбе с неисправностями. В такой системе поддержки пользователей занята группа специалистов-разработчиков, либо прикладной администратор БД. Если "справочному столу" удается решить возникшую проблему, то АБД может никогда и не узнать о том, что она вообще возникала.
Вместе с администратором БД должен работать информационный аналитик, чье присутствие гарантирует, что все создаваемое с точки приложения программное обеспечение эффективно использует имеющиеся аппаратные возможности и учитывает нынешнее и будущее окружение СУРБД Oracle.
Программисту могут быть переданы некоторые полномочия администратора БД, касающиеся тестового экземпляра БД. Программист должен обладать, но не должен пользоваться, правом осуществлять миграцию или установку программ из тестовой конфигурации БД в рабочую. Это одна из прерогатив АБД, он отвечает за то, чтобы внедряемые в систему объекты не конфликтовали с уже функционирующими. Кроме того, он несет ответственность за то, чтобы эти объекты поддавались восстановлению в случае отказа системы, либо в случае непреднамеренной или умышленной порчи информации.
Прикладной администратор БД вплотную работает с разработчиками, включая и информационного аналитика, с тем, чтобы удостоверится, что все, что делается с точки зрения программного окружения, реализовывалось и эксплуатировалось наилучшим образом в зависимости от потребностей бизнеса.
Прикладной администратор БД обязательно принимает участие в любых мероприятиях по настройке приложения и, как правило, тесно контактирует с конечными пользователями в процессе выявления и исправления шероховатостей системы.
Системный АБД больше заботится о программной среде Oracle в целом, нежели об ее отдельных элементах. В его обязанности входит поддержка аппаратно-программной вычислительной среды в оптимальном состоянии, обеспечивающем максимальную производительность для приложений, использующих среду в своих нуждах. Кроме того, к ним относится выработка соответствующих рекомендаций и принятие решений относительно резервирования/восстановления файлов. Системный администратор БД занимается всем, что касается вопросов производительности и проблем, способных оказать влияние на среду СУРБД Oracle. Он также ответственен за реализацию любых репликаций (replication) и параллельного функционирования, если эти механизмы задействованы в его системе . Обслуживание SQL*Net и Net8 тоже возлагается на системного АБД. В добавок ко всему вышеперечисленному, системный АБД отвечает за любой Web-сервер, с которого осуществляется доступ к базе данных, особенно если этот сервер на платформе Oracle.
Системный администратор занимается установкой и поддержкой аппаратных средств, включая доступ к ним конечных пользователей. В небольших центрах обязанности системного АБД и системного администратора могут исполняться одним и тем же человеком. Системный АБД должен координировать свои усилия с системным администратором, разрабатывая структуру хранения и дублирования информации и планируя будущие запросы СУРБД Oracle.
Сетевой администратор обеспечивает связность элементов вычислительной сети. Без сомнения, под этим подразумеваются пользовательские АРМ, организация и администрирование внутренней и внешней сетей, а также информирование руководства о текущем состоянии системы и рекомендации относительно ее перспектив. Совместно с системным АБД, сетевой администратор осуществляет управление вспомогательными файлами SQL * Net или Net8, необходимыми конечным пользователям для подсоединения к среде Oracle.
ROLLUP
ROLLUP можно использовать каждый раз, когда требуется анализ коллекции данных в одном измерении, но более, чем на одном уровне детальности. Можно включить ROLLUP в раздел GROUP BY с указанием списка выражений группировки. DB2 UDB сначала группирует данные по всем выражениям группировки, потом по всем выражениям, кроме последнего, потом по всем, кроме двух последних, и т.д. После группировки по только первому выражению система выполняет последнюю группировку, в которой образуется одна группа, включающая всю таблицу целиком. (Это звучит похоже на повторяющийся процесс, но реально все группировки выполняются одновременно за один проход по таблице.)
В следующем примере иллюстрируется мощность ROLLUP. Систему просят найти число людей и среднюю сумму дохода в каждом городе, графстве и штате, а также аналогичные показатели для всей таблицы переписи:
SELECT state, county, city, count (*) AS population, avg (income) AS avg_income FROM census GROUP BY ROLLUP (state, county, city);
Поскольку этот запрос не включает раздел ORDER BY, в результирующем наборе не гарантируется какая-либо упорядоченность строк. Однако, чтобы проиллюстрировать, каким образом вычислялся результат, в таблице 2 строки приведены в соответствующем порядке. Во-первых, имеются девять строк для групп, образованных группировкой по state, county и city; затем идут четыре строки для группировки по state и county с неопределенными значениями для city; затем - две строки для группировки по state с неопределенными значениями для county и city; и, наконец, одна завершающая строка для всей таблицы Census с неопределенными значениями для state, county и city.
Напомним, что порядок выражений в списке ROLLUP является существенным. Если одна разновидность группы логически содержится внутри другой (как county содержится внутри state), следует убедиться, что первой указывается самая включающая группа (state до county).
| FL | Dada | Hialeah | 2 | 38700 |
| FL | Dade | Miami | 2 | 36150 |
| *FL | Dade | (null) | 2 | 32950 |
| FL | Orange | Orlando | 2 | 42350 |
| FL | Orange | Taft | 2 | 29550 |
| TX | Harris | Baytown | 2 | 30650 |
| TX | Harris | Houston | 3 | 37800 |
| TX | Travis | Austin | 2 | 40450 |
| TX | Travis | (null) | 1 | 34800 |
| *FL | Dade | (null) | 6 | 35933 |
| FL | Orange | (null) | 4 | 35950 |
| TX | Harris | (null) | 5 | 34225 |
| TX | Travis | (null) | 3 | 38566 |
| FL | (null) | (null) | 10 | 35940 |
| TX | (null) | (null) | 8 | 36085 |
| (null) | (null) | (null) | 18 | 36000 |
Таблица 2. Результаты запроса с ROLLUP
Как показывает таблица 2, один запрос вычислил четыре разных уровня группировки, для чего потребовалось бы четыре запроса без ROLLUP. Поэтому возможность ROLLUP обеспечивает большие преимущества в отношение и удобства, и эффективности. Однако, если внимательно посмотреть на результаты запроса, можно заметить наличие некоторого беспорядка. Результат содержит две строки (помеченные звездочками) для графства Dade, штат Florida с неопределенным значением city. В одной из этих строк значение population равно двум, в другой - шести.
Первая из этих строк представляет группу на уровне state, county, city, включающую людей, проживающих в графстве Dade, Florida в сельской местности вне какого-либо города. (Из таблицы Census видно, что таких людей двое - Jim и Joan.) С другой стороны, вторая строка представляет группу уровня state, county, включающую всех людей, проживающих в графстве Dade. (В таблице Census представлено шесть таких человек.) Поэтому можно сказать, что неопределенное значение в первой строке означает "нет города", а неопределенное значение во второй строке означает "все города". Понятно, что требуется какой-то способ различать эти случаи путем указания уровня группировки, относящегося к каждой строке. DB2 UDB обеспечивает функцию, называемую grouping и служащую в точности для этих целей.
Функция grouping предназначена для использования в запросах, производящих более одного типа группировки. Аргументом функции является один из столбцов группировки, и функция возвращает значение "1", если указанный столбец слит с группой более высокого уровня. Таким образом, для тех специальных строк, в которых неопределенное значение city означает "все города", значение grouping(city) есть "1"; для обычных строк значение grouping(city) есть "0".
Функцию grouping можно использовать несколькими способами. Когда запрос с ROLLUP выполняется из прикладной программы, следует применять функцию grouping к каждому столбцу списка ROLLUP и считывать результаты в переменные основной программы для использования при интерпретации строк результата запроса.
Когда функция grouping возвращает "1", ее столбец- аргумент содержит неопределенное значение, которое следует интерпретировать как "все значения".
Если запрос выбирает значения для их непосредственного отображения на экране, можно использовать функцию grouping в выражении CASE, в котором указана специальная строка для представления "всех значений". Для этой цели можно использовать любую строку, но, конечно, стоит выбрать строку, которую легко отличить от допустимого значения данных. В следующем запросе выражения CASE используются для отображения строки "(-all-)" вместо неопределенного значения, когда функция grouping показывает, что неопределенное значение представляет "все значения":
SELECT CASE grouping(state) WHEN 1 THEN '(-all)' ELSE state END AS state, CASE grouping (county) WHEN 1 THEN '(-all-)' ELSE county END AS county, CASE grouping (city) WHEN 1 THEN '(-all-)' ELSE city END AS city, count(*) AS pop, avg(income) AS avg_income FROM census GROUP BY ROLLUP(state, county, city);
В таблице 3 показаны результата запроса. Как видно, легко отличить строку, которая представляет людей в графстве Dade с неопределенными городами от строки, представляющей группу всех людей в графстве Dade независимо от города.
| FL | Dade | Hialeah | 2 | 38700 |
| FL | Dade | Miami | 2 | 36150 |
| FL | Dade | (null) | 2 | 32950 |
| FL | Orange | Orlando | 2 | 42350 |
| FL | Orange | Taft | 2 | 29550 |
| TX | Harris | Baytown | 2 | 30650 |
| TX | Harris | Houston | 3 | 37800 |
| TX | Travis | Austin | 2 | 40450 |
| TX | Travis | (null) | 1 | 34800 |
| FL | Dade | (-all-) | 6 | 35933 |
| FL | Orange | (-all-) | 4 | 35950 |
| TX | Harris | (-all-) | 5 | 34225 |
| TX | Travis | (-all-) | 3 | 38566 |
| FL | (-all-) | (-all-) | 10 | 35940 |
| TX | (-all-) | (-all-) | 8 | 36085 |
| (-all-) | (-all-) | (-all-) | 18 | 36000 |
В запросе с ROLLUP можно также использовать разделы WHERE и HAVING. Например, следующий запрос позволяет найти число женщин и среднюю величину их дохода для каждого города, графства и штата, для которых в переписи зарегистрировано не меньше двух женщин:
SELECT CASE grouping(state) WHEN 1 THEN '(-all)' ELSE state END AS state, CASE grouping (county) WHEN 1 THEN '(-all-)' ELSE county END AS county, CASE grouping (city) WHEN 1 THEN '(-all-)' ELSE city END AS city, count(*) AS f_pop, avg(income) AS avg_f_income FROM census WHERE sex = 'F' GROUP BY ROLLUP(state, county, city) HAVING count(*) >= 2;
Результаты, приведенные в таблице 4, показывают, что данные переписи содержат двух или более женщин в одном городе (Houston), в трех графствах (Dade, Orange и Harris); в двух штатах (Florida и Texas) и во всей таблице целиком.
| TX | Harris | Houston | 2 | 44700 |
| FL | Dade | (-all-) | 2 | 40100 |
| FL | Orange | (-all-) | 2 | 36600 |
| TX | Harris | (-all-) | 2 | 44700 |
| FL | (-all-) | (-all-) | 4 | 38350 |
| TX | (-all-) | (-all-) | 3 | 39750 |
| (-all-) | (-all-) | (-all-) | 7 | 38816 |
С. Д. Кузнецов
Реляционная модель данных в подавляющем большинстве случаев вполне достаточна для моделирования любых данных. Однако проектирование базы данных в терминах схемы отношений на практике может вызвать большие затруднения, т.к. в этой модели изначально не предусмотрены механизмы описания семантики предметной области. С этим связано появление семантических моделей данных, которые позволяют описать конкретную предметную область гораздо ближе к интуитивному пониманию и, в то же время, достаточно формальным образом.
Часто семантическое моделирование используется только на первой стадии проектирования базы данных. Концептуальная схема будущей БД строится на основе некоторой семантической модели, а затем вручную преобразуется к реляционной схеме.
Существуют методики, четко описывающие все этапы такого преобразования.
При таком подходе отсутствует потребность в дополнительных программных средствах, поддерживающих семантическое моделирование. Требуется только владение основами выбранной семантической модели и правилами преобразования концептуальной схемы в реляционную.
Следует заметить, что многие начинающие проектировщики баз данных недооценивают важность семантического моделирования вручную. Зачастую это воспринимается как дополнительная и излишняя работа. Эта точка зрения является абсолютно неверной. Во-первых, построение мощной и наглядной концептуальной схемы БД позволяет более полно оценить специфику моделируемой предметной области и избежать возможных ошибок на стадии проектирования схемы реляционной БД. Во-вторых, на этапе семантического моделирования производится очень важная документация (хотя бы в виде вручную нарисованных диаграмм и комментариев к ним), которая может оказаться полезной не только при проектировании схемы реляционной БД, но и при эксплуатации, сопровождении и развитии уже заполненной БД.
Мне неоднократно приходилось наблюдать жизненные ситуации, когда отсутствие такого рода документации существенно затрудняло выполнение даже небольших изменений в схеме существующей реляционной БД.
Конечно, это относится к случаям, когда проектируемая БД содержит не слишком малое число таблиц. Скорее всего, можно обойтись без семантического моделирования, если число таблиц не превышает десяти, но оно становится совершенно необходимым, если БД включает более сотни таблиц. Для справедливости заметим, что ручная процедура создания концептуальной схемы с ее последующим преобразованием к реляционной схеме БД в случае больших БД (несколько сотен таблиц) затруднительна. Причины, по всей видимости, не требуют пояснений.
История систем автоматизации проектирования баз данных (CASE-средств) начиналась с автоматизации процесса рисования диаграмм, проверки их формальной корректности, обеспечения средств долговременного хранения диаграмм и другой проектной документации. Конечно, компьютерная поддержка работы с диаграммами очень полезна для проектировщика БД. Наличие электронного архива проектной документации помогает при эксплуатации, администрировании и сопровождении базы данных. Но система, которая ограничивается поддержкой рисования диаграмм, проверкой их корректности и хранением, напоминает текстовый редактор, поддерживающий ввод, редактирование и проверку синтаксической корректности конструкций некоторого языка программирования, но существующий отдельно от компилятора. Кажется естественным желание расширить такой редактор функциями компилятора, и это действительно возможно, поскольку известна техника компиляции конструкций языка программирования в коды целевого компьютера. Но коль скоро имеется четкая методика преобразования концептуальной схемы БД в реляционную схему, то почему бы ни выполнить программную реализацию соответствующего “компилятора” и ни включить ее в состав системы проектирования баз данных?
Эта простая мысль, естественно, не могла не придти в головы производителей CASE-средств проектирования БД. Подавляющее большинство подобных систем, представленных на рынке, обеспечивает автоматизированное преобразование диаграммных концептуальных схем баз данных, представленных в той или иной семантической модели данных, в реляционные схемы, представленные чаще всего на языке SQL.
У читателя может возникнуть вопрос, почему в предыдущем предложении говорится про “автоматизированное”, а не про “автоматическое” преобразование? Все дело в том, что в типичной схеме SQL-ориентированной БД могут содержаться определения многих объектов (ограничений целостности общего вида, триггеров и хранимых процедур и т.д.), которые невозможно сгенерировать автоматически на основе концептуальной схемы. Поэтому на завершающем этапе проектирования реляционной схемы снова требуется ручная работа проектировщика.
Еще раз обратите внимание на то, какой ход рассуждений привел нас к выводу о возможности автоматизации процесса преобразования концептуальной схемы БД в реляционную. Если создатели семантической модели данных предоставляют методику преобразования концептуальных схем в реляционные, достаточную для ее применения человеком, то почему бы ни реализовать программу, которая производит те же преобразования, следуя той же методике? Зададимся теперь другим, но, по существу, похожим вопросом. Если создатели семантической модели данных предоставляют язык (например, диаграммный), используя который проектировщики БД могут на основе исходной информации о предметной области сформировать концептуальную схему БД, то почему бы ни реализовать программу, которая сама генерирует концептуальную схему БД в соответствующей семантической модели, используя исходную информацию о предметной области? Хотя мне неизвестны коммерческие CASE-средства проектирования БД, поддерживающие такой подход, экспериментальные системы успешно существовали. Они представляли собой интегрированные системы проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области и последующим преобразованием концептуальной схемы в реляционную.
Существует много разных подходов к семантическому моделированию баз данных. В последние 10 лет одним из наиболее популярных языков семантического моделирования является UML. Проектирование реляционных БД – только одна и не слишком большая область применения этого языка, его возможности гораздо шире, однако подмножество UML (диаграммы классов) успешно применяется именно для таких целей.
По моему мнению, языковой механизм диаграмм классов по своей сути не отличается от существенно ранее внедренного в практику языкового механизма ER-диаграмм. Тем не менее, проектирование реляционных баз данных в среде UML дает одно существенное преимущество: можно выполнить весь проект создания информационной системы на основе одного общего инструмента (предвижу возражения сторонников ER-диаграмм).
Языку объектно-ориентированного моделирования UML (Unified Modeling Language) посвящено великое множество книг, многие из которых переведены на русский язык (а некоторые и написаны российскими авторами). UML разработан и развивается консорциумом OMG (Object Management Group) и имеет много общего с объектными моделями, на которых основана технология распределенных объектных систем CORBA, и объектной моделью ODMG (Object Data Management Group).
Семантика функциональных update-выражений вида TRANSFORM REPLACE
Функциональное update-выражение вида transform replace возвращает модифицированную копию последовательности узлов, возвращаемую XPath-выражения locpath1, в которой каждый узел из последовательности, являющейся результатом вычисления XPath-выражением locpath2, заменяется на последовательность узлов, возвращаемую выражением expr.
Тонкости определения семантики связаны с вычислением выражения expr. Пусть результатом вычисления выражения locpath2 является последовательность узлов L2. В случае, когда вычисление выражения expr зависит от узлов из последовательности L2, возникают следующие альтернативы:
вычислять выражение expr на узлах исходного документа; вычислять выражение expr на модифицированных копиях узлов документа.
Чтобы проиллюстрировать различия, рассмотрим следующий абстрактный пример. Пусть необходимо трансформировать XML-данные следующего вида:.
<root> <a> <a>text1</a> <b>text2</b> <a>text3</a> </a> </root>
Рассмотрим функциональное update-выражение, описывающее трансформацию данных, заключающуюся в переименовании всех XML-элементов a на b:
for $r in doc("some.xml")/root transform replace $a in $r//a with <b> { ($a/@*,$a/*) } </b>
В этом выражении expr($var2) представляет собой конструктор <b>{($a/@*, $a/*)}</b>. Если вычислять выражение на узлах оригинального документа, то представленное функциональное update-выражение вернет следующий результат:
<root> <b> <a>text1</a> <b>text2</b> <a>text3</a> </b> </root>
Если же вычислять выражение на модифицированных копиях узлов документа, то результат будет отражать рекурсивную семантику трансформации:
<root> <b> <b>text1</b> <b>text2</b> <b>text3</b> </b> </root>
Будем называть семантику вычисление функционального update-выражения с вычислением выражения expr на узлах оригинального документа прямой, а семантику с вычислением выражения expr на модифицированных копиях узлов документа - рекурсивной.
Для определения семантики функциональных update-выражений вида TRANSFORM INSERT и TRANSFORM DELETE выразим их через функциональные update-выражения вида TRANSFORM REPLACE, для которых семантика была определена выше.
В синтаксисе функциональных update-выражений вида TRANSFORM INSERT выражение expr($var1,$var2) определяет упорядоченную последовательность узлов, которые необходимо вставить. Для каждого целевого узла последовательности, возвращаемой выражением locpath2, результат вычисления выражения expr($var1,$var2) вставляется на позицию, определяемую ключевыми словами into, preceding и following. Если указано ключевое слово into, то узлы вставляются в начало последовательности дочерних узлов целевого узла. Если указано ключевое слово preceding, то узлы вставляются непосредственно перед каждым целевым узлом. В случае, если позиция определяется ключевым словом following, узлы вставляются после каждого целевого узла.
В синтаксисе функциональных update-выражений вида TRANSFORM DELETE выражение locpath2($var1) определяет последовательность узлов, которые подлежат удалению из результата. Узлы удаляются вместе со всем их содержимым.
Ниже приводится формальное определение функциональных update-выражений вида TRANSFORM INSERT и TRANSFORM DELETE через выражения вида TRANSFORM REPLACE.
1) INSERT INTO
for $var1 in locpath1 transform insert into $var2 in locpath2($var1) value expr($var1,$var2)
определяется, как
for $var1 in locpath1 transform replace $var2 in locpath2($var1) with element {node-name($var2)} {($var2/@*,expr($var1,$var2),$var2/*)}
2) INSERT PRECEDING
for $var1 in locpath1 transform insert preceding $var2 in locpath2($var1) value expr($var1,$var2)
определяется, как
for $var1 in locpath1 transform replace $var2 in locpath2($var1) with (expr($var1,$var2),$var2)
3) INSERT FOLLOWING
for $var1 in locpath1 transform insert following $var2 in locpath2($var1) value expr($var1,$var2)
определяется, как
for $var1 in locpath1 transform replace $var2 in locpath2($var1) with ($var2, expr($var1,$var2))
4) DELETE
for $var1 in locpath1 transform delete locpath2($var1)
определяется, как
for $var1 in locpath1 transform replace $var2 in locpath2($var1) with ()
Далее мы рассмотрим некоторые подходы к реализации функциональных update-выражений. Будут выделены возможные ограничения семантики таких выражений, которые позволяют упростить реализацию и сделать ее более эффективной.
Выбор семантики функциональных update- выражений зависит от того, какие запросы к XML-данным являются более востребованными. Функциональные update-выражения с прямой семантикой соответствуют логике трансформации данных, когда необходимо трансформировать элементы без учета возможной их вложенности, то есть только XML-элементы, самые близкие к вершине XML-дерева, которые соответствуют критерию выборки. В отличие от этого, функциональные update-выражения с рекурсивной семантикой соответствуют логике обработки данных, когда необходимо выполнить рекурсивную трансформацию данных, то есть, при измении некоторым образом XML-элемента, удовлетворяющего критерию выборки, требуется выполнить трансформацию и его содержимого, если оно также удовлетворяет критерию выборки.
Нам представляется целесообразным расширять язык XQuery функциональными update-выражениями с рекурсивной семантикой, так как запросы, соответствующие такой семантике, более характерны для обработки иерархической структуры XML-данных.
Для более точного определения рекурсивной семантики функциональных update-выражений, мы приведем его 'эталонную' интерпретацию, в которой не учитываются вопросы эффективного вычисления, а лишь определяется результат вычисления функционального update-выражения.
Пусть даны дерево XML-документа T и функциональное update-выражение вида
for $var1 in locpath1 transform replace $var2 in locpath2($var1) with expr($var2)
1-ый шаг интерпретации:
Построить T' - полную копию исходного дерева документа T. Построение означает, что уникальные идентификаторы узлов дерева T' будут отличаться от уникальных идентификаторов соответствующих узлов дерева T. Все остальные элементы модели данных языка XQuery для деревьев T и T' будут совпадать. Поскольку построена полная копия, то результаты вычисления XPath-выражений locpath1 и locpath2 на деревьях T и T' будут совпадать.
2-ой шаг интерпретации:
Вычислить XPath-выражение locpath1 над XML-деревом T', получив последовательность узлов L1'. Для каждого узла из последовательности L1' получить последовательность узлов L2', являющуюся результатом вычисления выражения locpath2 над деревом T'.
3-ий шаг интерпретации:
Представить последовательность L2' в обратном порядке документа, получая последовательность L2''.
4-ый шаг интерпретации:
Каждый узел из последовательности L2'', начиная с первого, заменить последовательностью узлов, являющихся результатом вычисления выражения expr на дереве T'.
5-ый шаг интерпретации:
Вернуть последовательность XML-узлов L1'. Если в результате выполнения 4-го шага интерпретации, какой-либо из узлов последовательности L1' был заменен последовательностью узлов, то в результат добавляется вся эта последовательность узлов.
Семантика объектных атрибутов.
Информация о качестве есть семантически значимая информация. Проще говоря, она имеет смысл. Этот смысл определяется именем качества (типа). "Вес", "адрес", "цвет" и т.п. - все эти слова являются семантически значимыми именами соответствующих типов. Они позволяют ассоциировать значения качеств с полученными ранее знаниями (информацией) об устройстве материального мира. Употребляя их мы их понимаем, какое именно взаимодействие этими значениями описывается.
Однако имя качества - это не единственное имя, которое может быть связано со значением качества. Поскольку речь идет о качестве объектов, то значение этого качества является также значением некоторого объектного атрибута и, соответственно, с ним также ассоциируется другое имя - имя атрибута объекта.
Таким образом, любому атрибута объекта ставиться в соответствие два имени, которые можно обозначить как "качественное" и "структурное". "Качественное" имя - имя качественного типа (Q) - показывают, как вещи могут взаимодействовать с окружающим миром. "Структурные" имя - имя атрибута объекта (S) - объясняет (в той или иной степени), почему и как конкретная вещь обладает этими способностями к взаимодействию. "Качественные" и "структурные" имена определенны в ортогональных компонентах системы описания данных.
Последнее замечание является важным, поскольку очень часто имя качества может быть абсолютно созвучно имени атрибута. Например, может существовать объект с атрибутом "адрес" имеющим качественный тип "адрес". Однако, несмотря на возможную семантическую идентичность, эти имена определены в ортогональных компонентах и, следовательно, являются разными.
Необходимость такой "двусмысленности" можно объяснить на следующем примере. Существует некий груз. Описывая этот груз мы может использовать информацию о "нетто-весе" (значение веса без упаковки) и о "брутто-весе" (значение веса вместе с упаковкой).
Эти разные по смыслу атрибуты объекта имеют один и того же качественный тип - "вес", то есть фактически определяют, что груз (единая сущность) может вступать в одно и то же взаимодействие с другими вещами (весить, давить на основание), однако это взаимодействие может осуществляться по-разному. Эта разница определяется именами атрибутов "брутто-вес" и "нетто-вес", которые подразумевают, что описываемый груз состоит из многих вещей, в том числе упаковки. Однако мы не моделируем эти вещи, что позволяет представить описываемый груз как единую сущность.
Обобщим этот пример. Как мы уже говорили, качество, описывая вещь как единую сущность, не может описывать реальную структуру этой вещи. Однако часто бывает необходимым показать, что вещь может участвовать в одном и том же взаимодействии по-разному. Этот факт может быть объяснен только существование такой сложной структуры, то есть какая-то информация об этой структуре все же должна присутствовать. Именно для этого и служат имена атрибутов - они позволяют подразумевать наличие сложной структуры, не описывая ее.
Серия интервью в ACM SIGMOD Record
Сергей Кузнецов
С сентября 2001 г. в журнале ACM SIGMOD Record существует раздел , в котором публикуются интервью с наиболее известными и заслуженными членами мирового сообщества баз данных. Постоянной ведущей этого раздела является Мэрианн Винслетт (Marianne Winslett). За прошедшие годы были опубликованы интервью (в хронологическом порядке) с Джеффри Ульманом (Jeffrey D. Ullman), Гио Вайдерхолдом (Gio Wiederhold), Ави Зильбершацем (Avi Silberschatz), Дэвидом Девиттом (David DeWitt), Гектором Гарсиа-Молина (Hector Garcia-Molina), Дэвидом Майером (David Maier), Джимом Греем (Jim Gray), Майклом Стоунбрейкером (Michael Stonebraker), Ракешем Агравалом (Rakesh Agrawal), Патрицией Селинджер (Pat Selinger), Питером Ченом (Peter Chen), Джеффри Нотоном (Jeffrey Naughton), Филиппом Бернштейном (Phil Bernstein), К. Моханом (C. Mohan) и Брюсом Линдсеем (Bruce Lindsay). Кроме того, в первом номере журнала за 2005 г. появилось тематическое коллективное интервью группы исследователей, посвященное виртуальным организациям.
Журнал ACM SIGMOD Record свободно доступен в Internet. В частности, можно прочитать и все эти интервью, которые не только помогают ближе познакомиться с исследователями, широко известными по многочисленным научным публикациям, но и дают возможность узнать, какие направления исследователей они считают наиболее важными и перспективными. В течение пяти лет я считал, что возможность читать эти материалы в оригинале достаточна для любого отечественного специалиста в области баз данных. Но когда в июньском (2005 г.) номере журнала появилось интервью Брюса Линдсея, я не выдержал и решил перевести и это интервью, а в придачу к нему и , которое в оригинале появилось полтора года назад.
Основная причина моего решения состоит в том, что Брюс и Пат - это основные разработчики любимой мной System R, всю свою жизнь посвятившие развитию технологии баз данных в IBM. Для тех, кто знаком с историей System R (те же, кто с ней не знаком, могут почитать ), эти интервью позволяют узнать массу интересных подробностей и о том, как выполнялся этот проект, и о том, к каким он привел последствиям, и о том, как сложилась дальнейшая жизнь его участников. Мне было очень интересно переводить эти интервью. Надеюсь, что вы получите такое же удовольствие от их чтения.
Вообще-то перевода заслуживает и ряд других интервью (в частности, интервью Стоунбрейкера, Грея, Девитта, Бернштейна и др.). Если этот жанр покажется вам интересным и полезным, редакции CITForum, и я продолжу работу.
Итак,
о System R; об оценочных испытаниях; о жизни почетного сотрудника IBM; о могуществе DBA в прошлом; о том, почему вопросы производительности остаются на повестке дня; о Гейзенбагах; о том, почему он все еще пишет программы; о поющих поросятах и о многом другом
о том, почему проект System R был таким успешным; о взаимосвязи с группами INGRES и QBE; о том, как убыстрять разработку технологий, как управлять трудными людьми, как наставлять сразу 3000 человек и многом другом
Сервер Cache' Objects
Объектная модель Cache' соответствует объектной модели стандарта ODMG (Object Data Management Group). В соответствии с ODMG каждый объект Cache' имеет определенный, единственный тип. Поведение объекта определяется операциями (методами), а состояние объекта - значениями его свойств. Свойства и операции составляют характеристики типа. Тип определяется одним интерфейсом, которому может соответствовать одна или большее число реализаций [2]. Объектная модель Cache' представлена на рис. 2.
В соответствии со стандартом в Cache' реализовано два типа классов:
Классы типов данных (литералы). Классы объектов (объекты).
Классы типов данных определяют допустимые значения констант (литералов) и позволяют их контролировать. Литерал не может существовать независимо от своего значения, в то время как объекты имеют уникальную идентификацию.
Классы типов данных подразделяется на два подкласса типов:
Атомарные Структурированные.
Атомарными литеральными типами в Cache' являются традиционные скалярные типы данных (%String, %Integer, %Float, %Date и др.). В Cache' реализованы две структуры классов типов данных - список и массив. Каждый литерал уникально идентифицируется индексом в массиве и порядковым номером в списке.

Рис.2. Объектная модель Cache'
Различают два подтипа классов объектов - зарегистрированные и незарегистрированные. Зарегистрированные классы обладают предопределенным поведением, т.е. набором методов, наследуемых из системного класса %RegisteredObject и отвечающих за создание новых объектов и за управление размещением объектов в памяти. Незарегистрированные классы не обладают предопределенным поведением, разработка функций (методов) класса целиком и полностью возлагается на разработчика.
Зарегистрированные классы могут быть двух типов - встраиваемые и хранимые. Встраиваемые классы наследуют свое поведение от системного класса %SerialObject. Основной особенностью хранения встраиваемого класса является то, что объекты встраиваемых классов существуют в памяти как независимые экземпляры, однако могут быть сохранены в базе данных, только будучи встроены в другой класс.
Основным преимуществом использования встроенных классов является минимум издержек, связанных с возможным в будущем изменением набора одинаковых свойств классов, представленных в виде встраиваемого объекта.
Хранимые классы наследуют свое поведение от системного класса %Persistent. %Persistent предоставляет обширный набор функций своим наследникам, включающий: создание объекта, подкачку объекта из БД в память, удаление объекта и т.п. Каждый экземпляр хранимого класса имеет 2 уникальных идентификатора - OID и OREF. OID (object ID) характеризует объект, записанный в БД, т.е. на физическом носителе, а OREF (object reference) характеризует объект, который был подкачен из БД и находится в памяти.
Объектная модель Cache' в полном объеме поддерживает все основные концепции объектной технологии:
Наследование. Объектная модель Cache' позволяет наследовать классы от произвольного количества родительских классов. Полиморфизм. Объектная модель Cache' позволяет создавать приложения целиком и полностью независимыми от внутренней реализации методов объекта. Инкапсуляция. Объектная модель Cache' обеспечивает сокрытие отдельных деталей внутреннего устройства классов от внешних по отношению к нему объектов или пользователей. Разделяют интерфейсную часть класса и конкретную реализацию. Интерфейсная часть необходима для взаимодействия с любыми другими объектами. Реализация же скрывает особенности реализации класса, т.е. все, что не относиться к интерфейсной части. Хранимость. Система Cache' поддерживает несколько видов хранения объектов: автоматическое хранение в многомерной базе данных Cache'; хранение в любых структурах, определенных пользователем; хранение в таблицах внешних реляционных баз данных, доступных через шлюз Cache' SQL Gateway.
Класс объектов в Cache' хранится в двух формах:
Описательная форма. Поддерживается развитый язык описания классов объектов - CDL (class definition language). В версии Cache' 4.2. планируется обеспечить поддержку языков UDL (unified definition language) и XML (extensible markup language). Объектная run-time форма.Использование класса возможно только после его компиляции в объектный код.
Сервер Cache' SQL

СУБД Cache' является уникальной системой. Наряду с реализацией в полном объеме основных принципов объектной технологии в СУБД Cache' поддерживается также структурированный язык запросов SQL для обеспечения выполнения запросов по стандарту, поддерживаемому многими инструментальными средствами. Кроме этого, с помощью единой архитектуры данных Cache' возможно автоматическое преобразование реляционных таблиц в классы объектов. При этом, при поступлении на сервер Cache' SQL DDL-описания реляционной таблицы Cache' автоматически преобразует DDL-описание во внутреннюю структуру хранения данных и сохраняет полученную структуру в словаре данных. Затем с помощью поставляемых в стандартной комплектации Java- или ODBC- драйверов производится импорт данных из реляционных таблиц в многомерные структуры ядра Cache'. После чего Cache' предоставляет возможность работы с данными, как в виде реляционных таблиц, так и в виде классов объектов. Таким образом, при переходе с реляционной технологии на объектную технологию разработка не начинается с "нуля" - многое уже сделано Cache' автоматически.
Классы Cache' также могут быть представлены в виде реляционных таблиц, причем соотношение между разнообразными понятиями объектного и реляционного подходов представлены ниже:
| Класс | Таблица |
| Экземпляр | Строка |
| Идентификатор объекта (OID) | ID-столбец в виде первичного ключа |
| Свойство-константа | Столбец |
| Ссылка на хранимый объект | Внешний ключ |
| Встраиваемый объект | Индивидуальные столбцы |
| Коллекция-список | Столбец с полем-списком |
| Коллекция-массив | Подтаблица |
| Поток данных | BLOB |
| Индекс | Индекс |
| Запрос | Хранимая процедура или представление |
| Метод класса | Хранимая процедура |
Отметим, что в таблице не обозначены понятия параметров класса, многомерных свойств и методов объекта, так как в реляционной технологии им нет аналогов. Дополнительно к объектным понятиям в Cache' поддерживаются еще и триггеры, присутствующие в реляционном представлении.
Доступ к данным с использованием языка SQL продолжает играть важную роль, т.к.
многие существующие приложения и инструменты используют SQL в качестве языка запросов. СУБД Cache' поддерживает все элементы ANSI-стандартов, реализованных для SQL и SQL-92.
Для облегчения разработки прикладных систем баз данных, Cache' поддерживает встраивание SQL в методы и программы. Встроенный SQL может быть использован для решения следующих задач:
Реализации сложных запросов к базам данных Представления полученных результатов запросов в качестве значений переменных встроенного языка разработки приложений Cache' Object Script (COS).
Пример использования встроенного SQL запроса:
new id, Surname set Surname="Ivanov" &sql(SELECT Id into :id FROM Person where Surname=:Surname)
Приведенный код ищет по полю Surname таблицы Person поле со значением Ivanov и сохраняет найденный OID объекта в локальной переменной id. Пример демонстрирует случай использования встроенного SQL-запроса, не основанного на курсоре. В данном случае запрос всегда возвращает только одну строку.
Если же необходимо получить несколько строк из результирующей выборки запроса необходимо использовать SQL, основанный на курсоре. Курсор в данном случае является указателем на одну строку и при проведении операции FETCH курсор передвигается к следующей строке.
Использование курсора предполагает выполнение следующей последовательности операций:
Объявление курсора; Открытие курсора; Проведение серий операций чтения (FETCH) для курсора; Закрытие курсора.
Пример использование курсора в SQL-запросах:
&sql(DECLARE PersCur CURSOR FOR SELECT Surname, DateOfBirth FROM Person, WHERE Surname="Ivanov") &sql(OPEN PersCur) &sql(FETCH PersCur INTO :surname, :DateOB) &sql(CLOSE PersCur)
В приведенном примере создается курсор PersCur на SQL-запрос SELECT, после чего определенный курсор открывается, а затем с помощью команды FETCH производится последовательное сканирование результатов выборки и в локальных переменных surname и DateOB сохраняются соответствующие значения полей Surname и DateOfBirth таблицы Person.После этого курсор закрывается.
Сервер прямого доступа к данным Cache' Direct.
С помощью сервера Cache' Direct разработчик получает доступ к многомерным структурам ядра системы. Встроенный в СУБД Cache' язык программирования COS предоставляет ряд функций для работы с массивами данных или глобалями, составляющими ядро системы. Использование прямого доступа к данным позволяет оптимизировать время доступа к данным. Для прямого доступа и работы с многомерными структурами ядра системы можно воспользоваться утилитой эмуляции ASCII-терминала Cache' Terminal, которая обычно используется для целей обучения языку COS и тестирования работы терминального приложения (рис.3).

Рис.3. Cache' Terminal
ШЛЮЗ WINDOWS-NETWARE
Пользуясь Windows NT и
другими продуктами Microsoft на ее основе, администратор может выбрать для работы с
"чужеродными" сетями решение без использования мультиплексоров протоколов на
клиентских компьютерах, а именно шлюз. В Windows NT Server есть один встроенный шлюз
Gateway Service for NetWare, естественно, для доступа к серверам NetWare; другие шлюзы
нужно приобретать как отдельные продукты.
Шлюз Gateway Service for NetWare
обеспечивает клиентам сети WindowsNT (а в их число входят компьютеры Windows NT
Workstation, Windows for Workgroups, Windows 95 и другие) прозрачный доступ к томам и
каталогам серверов NetWare 3.x и 4.x. При этом клиенты Windows NT не должны устанавливать
редиректоры Net-Ware (клиентские части протокола NCP).
Для доступа к файлам
NetWare клиенты, используя свой "родной" протокол SMB, обращаются к серверу
Windows NT, на котором работает шлюз GatewayService for NetWare. Разделяемые каталоги
серверов NetWare выглядят для пользователей точно так же, как и разделяемые каталоги
сервера, на котором расположен шлюз. Для того чтобы эти виртуальные каталоги выглядели как
реальные, шлюз совместно с администраторами двух сетей выполняет некоторую
предварительную работу.
Шлюз Gateway Service for
NetWare.
Администратор сети NetWare заводит фиктивного
пользователя, который отныне будет представлять в этой сети шлюз. Имя его выбирается
произвольно, но он обязательно должен быть членом группы NTGATEWAY. Далее
администратор NetWare определяет все ресурсы своей сети, к которым будет разрешен доступ
клиентам сети Microsoft, и задает права доступа к этим ресурсам для пользователя-шлюза.
Заметим, что так как все клиенты сети Windows NT для администратора NetWare выступают в
виде одного пользователя, то он не может дифференцировать этих клиентов по правам доступа.
Такая возможность делегируется администратору сети Microsoft.
Этот администратор
при конфигурации шлюза дает свои имена разделяемым каталогам NetWare и, используя
стандартные наборы прав доступа WindowsNT, может более тонко определить привилегии
каждого пользователя по отношению к этим виртуальным разделяемым каталогам. Очевидно,
что для свободного управления правами клиентов шлюза сам шлюз должен иметь максимальные
права доступа к каталогам серверов NetWare. Следовательно, администратор сети NetWare
должен полностью доверять администратору сети Microsoft. На практике это не всегда
приемлемо, за что Novell и критикует разработчиков шлюза Gateway Service for
NetWare.
Синтаксис функциональных update-выражений
Для удобства выражения логики обработки данных мы предлагаем расширить язык XQuery функциональными update-выражениями трех видов. Выражения первого вида описывают логику "найти и заменить" (TRANSFORM REPLACE). Выражения второго вида описывают логику "вставить новый элемент" (TRANSFORM INSERT). Выражения третьего вида описывают логику "найти и удалить элемент" (TRANSFORM DELETE). Синтаксис этих видов выражений выглядит следующим образом.
1) TRANSFORM REPLACE
for $var1 in locpath1 transform replace $var2 in locpath2($var1) with expr($var1,$var2)
2) TRANSFORM INSERT
for $var1 in locpath1 transform insert [into|preceding|following] $var2 in locpath2($var1) value expr($var1,$var2)
3) TRANSFORM DELETE
for $var1 in locpath1 transform delete locpath2($var1)
В приведенных синтаксических конструкциях слова, выделенные курсивом, означают следующее:
var1, var2 - т переменные языка XQuery;
locpath1 - XPath выражение;
locpath2($var1) - XPath выражение, записанное относительно переменной $var1;
expr($var1,$var2) - выражение расширенного языка XQuery, возможно зависящее от XQuery-переменных $var1 и $var2.
Следует обратить внимание, что XPath-выражение locpath2 ограничено тем, что оно должно быть записано относительно переменной var1. Узлы, соответствующие переменной var1, являются корневыми, то есть XPath-выражение locpath2 вида var1/. вернет пустую последовательность элементов.
Далее приводится описание семантики функциональных update-выражений вида transform replace. Семантика выражений вида transform insert и transform delete будет определена путем явного представления этих выражений через выражения вида transform replace.
Синтаксис и семантика расширенного языка
Программы на языке, тесно связывающем языковые средств выборки и модификации XML-данных, могут быть записаны следующим образом:
Expr1 UPDATE Expr2
В такой записи Expr1 и Expr2 - это выражения на языке XQuery, расширенном функциональными update-выражениями. Первое выражение содержит всю логику обработки данных и его результат представляет результат вычисления всей программы. Второе выражение определяет последовательность узлов, версию которых нужно сделать актуальной в базе данных, включая все вложенные элементы. Рассмотрим простой пример такой программы.
Пример. Приостановить все заказы, содержащие товар tires. Изменить статус заказа и вставить соответствующие комментарии.
let $order-status:= for $order in doc("orders")//order[status="ready and OrderLine/ItemName="tire"] transform replace $s in $order/status with <status>suspended</status> let $order-comment:= for $order in $order-status transform insert <comment>suspended</comment> into $order/OrderLine[ItemName="tire"] return $order-comment UPDATE $order-comment
Выражение до ключевого слова UPDATE представляет собой выражение на языке XQuery, расширенном функциональными update-выражениями. Переменная XQuery $order-status связывается с версией данных, модифицированных таким образом, что в элементах order, удовлетворяющих заданному предикату, изменен элемент status. Переменная XQuery $order-comment связывается с версией данных, в которой в каждый элемент order вставляется необходимый комментарий. Все выражение до ключевого слова UPDATE возвращает XML-данные - последовательность узлов, связанную с переменной $order-comment.
Выражение после ключевого слова UPDATE возвращает последовательность узлов, состояние которых надо сделать актуальным в базе данных, то есть зафиксировать как текущее. Для реализации такого подход требуются поддержка версий в реализации функциональных update-выражений и коррекция их семантики. В частности, необходима информация о соответствии между узлами в оригинальном документе и соответствующими новыми версиями узлов.
Можно заметить, что предлагаемый подход реализует отложенную семантику отражения изменений в базе данных. Однако это свойство не влияет на выразительность запросов и удобство программирования, поскольку разработчику доступно модифицированное состояние данных до его отражения в базе данных. Более того, доступны и начальное, и все модифицированные состояния данных.
Таким образом, такой подход обеспечивает естественную интеграцию языковых средств выборки и модификации XML-данных, предоставляя единую платформу для разработки XML-приложений на расширенном языке XQuery. Основные преимущества предложенного подхода состоят в следующем:
возможность композиции выражений языка XQuery и выражений языка модификации XML-данных; доступность при выражении логики обработки данных исходного и модифицированного состояний данных;
Синтаксис Общего Представления Данных - CDR.
CDR - это способ представления всех типов данных, определенных в OMG IDL в виде последовательности восьмиразрядных величин, далее называемых байтами.
Поток байт представляет из себя некоторую абстракцию обычно соответствующую буферу данных, который передается между процессами или машинами с помощью средств IPC или сетевого транспорта. Далее считается, что поток байт или просто поток - это последовательность переменной (но конечной) длины величин, состоящих из 8 бит (байт) с четко определенным заголовком. Байты в потоке нумеруются от 0 до n-1, где n
- это длина потока. Индекс каждого байта используется для вычисления границ выравнивания, как это описано далее.
Протокол GIOP определяет два вида потоков - сообщение и инкапсуляция. Сообщение - это основная единица обмена информацией в протоколе GIOP. Инкапсуляция - это поток, внутри которого любая структура данных, имеющаяся в OMG IDL может быть декодирована независимо от остального контекста сообщения. Инкапсуляция позволяет осуществлять предварительное кодирование сложных типов данных (таких как TypeCode) или обрабатывать части сообщений без требования полного его декодирования.
Системы управления базами данных в стиле "plug and play"
Мы используем фразу Plug and Play в двух смыслах. Во-первых, поскольку у баз данных "умных устройств" будут отсутствовать администраторы, эти базы данных должны быть самонастраиваемыми. Мы называем это безголовым использованием. Исследовательское сообщество баз данных должно разобраться, как сделать системы баз данных не требующими дополнительных мозгов. Краеугольным камнем этой работы является обеспечение самонастраиваемости систем баз данных, т.е. удаление мириадов параметров настройки производительности, которые должны определять пользователи в текущих продуктах. Следующая часть этой работы относится к физическому проектированию баз данных, например, методам автоматического выбора индексов; этим методам уделяется некоторое внимание в современных исследованиях и продуктах. В более общей постановке системы должны помогать и при логическом проектировании баз данных (например, таблиц и ограничений целостности) и при проектировании приложений, автоматически предоставляя полезные отчеты и утилиты. Для гарантирования хорошего поведения со временем безголовые системы должны приспосабливаться к изменению условий.
Хотя мы не хотим предлагать конкретное решение, обнадеживающим подходом является сохранение в системе базе данных всей информации относительно того, что происходило раньше. Тогда встроенный в систему баз данных мастер, обладающий детальными сведениями о настройке, анализирует эту информацию и производит автонастройку системы. Побочным эффектом этого подхода является то, что традиционные коммерческие системы баз данных становятся значительно проще администрируемыми. Поскольку большинство организаций страдает от отсутствия достаточного числа талантливых администраторов, безголовое использование систем баз данных чрезвычайно им поможет.
Второй аспект Plug and Play систем баз данных относится к обнаружению информации. Как отмечалось ранее, Web является громадной базой данных. Более того, большинство коммерческих предприятий имеет затруднения при интеграции "островков информации", присутствующих в их различных системах. Должно быть возможно подключить систему баз данных к сети компании или Internet и автоматически обеспечить раскрытие информации для всех других систем баз данных, доступных в сети, и взаимодействие с этими системами. Это является аналогом той поддержки, которую операционные системы выполняют по отношению к аппаратуре, раскрывая и опознавая все доступные устройства.
Это процесс раскрытия информации потребует от систем баз данных обеспечения существенно большего объема метаданных, описывающих смысл управляемых объектов. В добавок к этому, системы баз данных должны иметь богатые наборы функций преобразования данных от одного типы к другому. Разумно ожидать, что имеются и другие подходы к раскрытию информации.
Скелет реализации.
Для конкретного отображения и, возможно, используемого адаптера объектов определяется свой порядок вызова методов каждого объекта. Этот интерфейс в общем случае является интерфейсов обратных вызовов. При необходимости ORB вызывает требуемые процедуры.
Сколько нужно администраторов БД?
У каждой компании свои потребности, основанные на характере используемых приложений. Не существует двух контор с абсолютно одинаковыми запросами, тем не менее Gartner предлагает по этому поводу несколько рекомендаций:
оцените сложность и изменчивость БД по пятибальной шкале добавьте по два очка за каждую дополнительную БД учтите доходность системы расставьте приоритеты на основе следующей таблицы:
всего занятость администратора < 5 20% 5 или 6 25% 7 или 8 50% > 8 полная
Следствия
Что все это означает? Ответ на этот вопрос неочевиден. Понятно, что XML позволяет разрабатывать Web-экраны, отображающие данные из базы данных более простым и более управляемым образом. Однако язык не содержит механизм для реальной выборки данных из базы данных и их отображения. При желании создать Web-страницы, содержащие данные из базы данных требуется написать или купить программное обеспечение для выборки этих данных и создания страниц. Предположительно, код будет включать некоторую комбинацию Java и SQL.
В добавок к этому, по определению стандартный браузер не может должным образом интерпретировать определенные пользователем теги. Эту проблему можно решать тремя способами:
Написать апплеты, поодключаемые к странице. Эти апплеты должны понимать структуру данных и соответствующим образом отвечать за каждый тег. Использовать обобщенное программное обеспечение, читающее DTD и соответствующим образом реагирующее на теги. В этом случае точность интерпретации будет ограничена тем, что можно получить из DTD. Присоединиться к сообществу с целью совместного определения набора тегов, отвечающего задачам этого сообщества, а также разработки соответствующего проограммного обеспечения.
По-видимому, первые два подхода будут основываться на программном обеспечении, написанном на Java или аналогичном языке, но стандартные средства для того, чтобы это сделать, пока недоступны. Третий подход уже применяется. Например, химики создали на основе XML Химический язык разметки (Chemical Markup Language); то же относится к математикам, астрономам и т.д., у которых имеются наборы определенных тегов для описания данных, присущих их областям.
События объекта Database Container
События объекта Database Container (DBC) предоставляют связь между событиями, написанными разработчиком, и активностью базы данных во время работы пользователя, такой как открытие таблицы, добавление или удаление таблицы или изменение свойств. DBC события могут быть созданы как программно, так и в Database Designer.
DBC события имеет следующие способы использования:
Шифрование и дешифрование данных во время открытия или закрытия таблицы. Проверка прав доступа пользователя при открытии таблицы Предоставление сторонним производителям инструментов возможности перехватывать события в DBC для своей работы

Рисунок 4. События DBC
Совместное использование различных моделей данных
Средства OLAP часто реализуются в виде набора многопользовательских приложений с Web-поддержкой, дают быстрый доступ к любому элементу базы вне зависимости от объема и сложности данных. Часто это достигается за счет использования OLAP-сервера - мощного многопользовательского инструмента для работы с многомерными структурами данных. Конструкция сервера и структура данных оптимизируются таким образом, чтобы можно было выполнять нерегламентированные запросы, а также быстрые, гибкие вычисления и преобразования исходных данных.
С помощью OLAP сервера может быть организовано физическое хранение обработанной многомерной информации, что позволяет быстро выдавать ответы на запросы пользователя. Кроме того, предусматривается преобразование данных из реляционных и других баз в многомерные структуры в режиме реального времени.
Каким образом реляционные и многомерные средства работают совместно? OLAP продукты вливаются в существующую корпоративную инфраструктуру путем интегрирования с реляционными системами. Администраторы баз данных либо загружают реляционные данные в многомерный кэш, либо настраивают кэш для доступа к SQL данным.
В таблице 3 приведены сравнительные характеристики различных моделей управления данными:
| Таблица 3. |
| Характеристики | Реляционные СУБД OLTP | Реляционные СУБД СППР/Хранилища данных | Многомерные СУБД OLAP | |||
| Типовая операция | Обновление | Отчет | Анализ | |||
| Уровень аналитических требований | Низкий | Средний | Высокий | |||
| Экраны | Неизменяемые | Определяемые пользователем | Определяемые пользователем | |||
| Объем данных на транзакцию | Небольшой | От малого до большого | Большой | |||
| Уровень данных | Детальные | Детальные и суммарные | В основном суммарные | |||
| Сроки хранения данных | Только текущие | Исторические и текущие | Исторические, текущие и прогнозируемые | |||
| Структурные элементы | Записи | Записи | Массивы |
В архитектуре, одновременно использующей реляционные и многомерные системы, данные хранятся на OLAP-сервере или OLAP-структуры используются в качестве кэша для реляционных данных.
Можно использовать комбинацию двух этих подходов, минимизируя объем данных, перемещаемых из реляционной среды в многомерную и обратно.
Обычно в реляционной системе хранятся более детализированные данные, чем в многомерной. OLAP позволяет пользователю переходить от сводной информации к более подробной.
Реляционная и многомерная модели математически очень похожи, поэтому отображение из одной архитектуры в другую выполняется легко. Например, переменные OLAP можно получить из столбцов реляционной базы. Измерения многомерного куба связаны напрямую с ключами, идентифицирующими строки реляционной базы.
Модель определят, что видит пользователь, какие вычислительные функции доступны, как быстро выполняются вычисления, каковы задачи технического персонала.
Обе модели дают возможности анализа, но использование, написание и поддержка сложного аналитического кода в многомерной модели требует меньшего времени и усилий, чем в реляционной.
Совместное использование учетных систем и технологии OLAP
В наше время без систем управления базами данных не обходится практически ни одна организация, особенно среди тех, которые традиционно ориентированы на взаимодействие с клиентами. Банки, страховые компании, авиа- и прочие транспортные компании, сети супермаркетов, телекоммуникационные и маркетинговые фирмы, организации, занятые в сфере услуг и другие - все они собирают и хранят в своих базах гигабайты данных о клиентах, продуктах и сервисах. Ценность подобных сведений несомненна. Они применяются для различных целей, например для управления материально-техническими запасами, управления отношениями с клиентами (CRM - customer relationship management), биллинга (формирования счетов) и т.п.
Такие базы данных называют операционными или транзакционными, поскольку они характеризуются огромным количеством небольших транзакций, или операций записи-чтения. Компьютерные системы, осуществляющие учет операций и собственно доступ к базам транзакций, принято называть системами оперативной обработки транзакций (OLTP - On-Line Transactional Processing) или учетными системами.
Учетные системы настраиваются и оптимизируются для выполнения максимального количества транзакций за короткие промежутки времени. Как правило, большой гибкости здесь не требуется, и чаще всего используется фиксированный набор надежных и безопасных методов сбора данных и отчетности. Показателем эффективности является количество транзакций, выполняемых за секунду. Обычно отдельные операции очень малы и не связаны друг с другом. Однако каждую запись данных, характеризующую взаимодействие с клиентом (звонок в службу поддержки, кассовую операцию, заказ по каталогу, посещение Web-сайта компании и т.п.) можно использовать для получения качественно новой информации, а именно для создания отчетов и анализа деятельности фирмы.
Создание нового наблюдения
Достаточно рассмотреть только операции, связанные с созданием нового наблюдения, поскольку удаление и изменение выражается через создание новых наблюдений.
Наблюдение возникает в силу самого факта измерения или другой оценки характеристик "объектов реального мира" и поэтому операция удаления к наблюдениям и объектам применяться не должна. Если какое-либо наблюдение признано недействительным, то этот факт просто отражается в системе без реального уничтожения этого наблюдения - начиная с некоторого момента времени объект не будет иметь актуального состояния (точнее он будет находиться в специальном состоянии Т). Точно также изменение каких-либо характеристик означает, что было произведено новое наблюдение, и оно становится "текущим". Будучи зафиксированным в проекте, наблюдение не может быть удалено или изменено. В некотором смысле так в модели автоматически реализуется процедура ведения логического протокола событий. Возможность отката состояния системы на какой-либо момент может быть реализована через создание множества новых наблюдений, повторяющих нужное состояние. В тоже время должна существовать возможность "физически" откатить систему на момент начала транзакции, если эта транзакция завершается аварийно.
Регистрация параметров представляет собой протяженный во времени процесс, поэтому требуются операции обозначающие его начало и конец. Начало и конец наблюдения образуют операторные скобки, соответствующие началу и концу транзакции.
В операцию начала наблюдения может подаваться тип наблюдения - тогда будет создано наблюдение этого типа. Если тип наблюдения не используется, то в наблюдении может участвовать любое количество глобально определенных параметров, в частности, ни одного. Если в операцию подается указатель объекта, то новое наблюдение будет относиться к этому объекту. Если объект в операцию не подан, то он будет создан и ему будет назначен идентификатор. В операции начала наблюдения могут также устанавливаться другие свойства наблюдения, такие как права доступа, ограничения и т.д.
Операция начала наблюдения фиксирует момент, определяющий время проведения данного наблюдения, который далее будет использоваться во всех вычислениях параметров, зависящих от времени.
Наблюдение представляет собой аналог транзакции для последовательности действий, связанной с регистрацией параметров. Действительно, наблюдение соответствует основным характеристикам транзакции - либо фиксируются все параметры, описывающие новое состояние, либо ни один из них. Если какая-то совокупность параметров имеет самостоятельное значение, то она может быть выделена в самостоятельное наблюдение. Одно наблюдение может быть разбито на несколько из соображений удобства или в соответствии с природой объектов. Кроме того, одно наблюдение может потребовать проведения ряда других наблюдений, над другими объектами. Такая ситуация соответствует модели вложенных транзакций, зависимых или независимых.
Операция "Конец наблюдения" определяет момент времени, когда зафиксированы все параметры, которые поставляет в наблюдение пользователь, и начинают исполняться процедуры для статических вычисляемых параметров. Затем происходит запуск системных процедур, устанавливающих триггеры, после чего инициируются наблюдения, непосредственно обусловленные данным наблюдением, причем последнее происходит уже вне рамок транзакции.
Проведение наблюдения состоит из нескольких фаз:
Проведение всех предварительных наблюдений Инициализация Установка значений параметров Вычисление статических параметров Установка триггеров, определенных в проекте Проведение (как последействие) наблюдений, непосредственно инициированных данным наблюдением
Конечно, тот факт, что в системе в явном виде хранится вся история жизни объектов, несколько осложняет жизнь пользователю, если он хочет видеть только "текущее состояние" предметной области, однако это резко повышает аналитические возможности модели. Кроме того, удобство работы определяется правильно выбранными интерфейсными операциями для навигации во множестве наблюдений и можно организовать интерфейс системы таким образом, что обычному пользователю будет доступно только текущее состояние.
Спецификация курсора
Наиболее общей является конструкция "спецификация курсора". Курсор - это средство языка SQL, позволяющее с помощью набора специальных операторов получить построчный доступ к результату запроса к БД. К табличным выражениям, участвующим в спецификации курсора, не предъявляются какие-либо ограничения. Как видно из сводки синтаксических правил, при определении спецификации курсора используются три дополнительных конструкции: спецификация запроса, выражение запросов и раздел ORDER BY.
Список задач (Task List)
Чтобы следить за работой и вовремя исполнять поставленные задачи, разработчику нужен способ записывать и позднее просматривать свой список задач. Для этого Foxpro предоствляет Task List-диалоговое окно, которое предлагает легкий способ для записи и управления задачами в проекте.
Во время разработки проекта вы можете создать пустую процедуру, а код добавить позже. И вам нужно, чтобы эта задача была добавлена в Task List для напоминания того, что нужно добавить код в процедуру. Используя shortcut-меню вы можете добавить задачу в Task List.
Позже вы можете вернуться к незаконченой процедуре двойным нажатием на записть в Task List.

Рисунок 5. Список задач
Сравнение технологий
Как правило, учетные системы работают с реляционными базами данных. Для OLAP-приложений же разработана специальная многомерная модель, которая позволяет более эффективно использовать данные, накопленные в оперативных системах. Технология оперативной аналитической обработки ориентирована на представление данных в виде массивов. Под массивом понимается последовательность элементов, например продажи продукта по рынкам/временным периодам, или доход по времени/региону.
В концепции и терминологии OLAP есть много аналогий с реляционной моделью. В таблице 1 приведено сравнение реляционных терминов и понятий и соответствующих эквивалентов в OLAP.
| Таблица 1. |
| Реляционная технология | OLAP Технология | |
| База данных | База данных | |
| Таблица | Куб | |
| Представление (Выборка) | Формула | |
| Первичный ключ | Измерения | |
| Внешний ключ, не являющийся частью первичного ключа | Отношение | |
| Столбец, не являющийся частью первичного или внешнего ключа | Переменная | |
| Строка | Экземпляр нескольких переменных | |
| Декларативная целостность ссылочных данных | Косвенно задается при определении измерений | |
| Процедурная целостность ссылочных данных (триггеры) | Отсутствует | |
| Индексы | Отсутствует | |
| Системный каталог | Метаданные | |
| Оператор JOIN | Отсутствует (косвенно задается общими измерениями) | |
| Оператор WHERE | Команда LIMIT | |
| Оператор GROUP BY | Команда GROUP | |
| Оператор ORDER BY | Команда SORT | |
| Директива GRANT | PERMIT | |
| Хранимые процедуры, сценарии, хранимый SQL | Программы и пользовательские функции | |
| Null-столбцы | Null-значения | |
| Null-строки - не могут быть в таблице или в результирующем множестве | Null-значения всегда в явном виде | |
| Управление потоковым языком (PL/SQL, Transact-SQL и др.) | Язык хранимых процедур | |
| Агрегирование (SUM, AVG, COUNT, MIN, MAX) | Функции и формулы | |
| Операторы вычисления (+, -, /, *) и два-три десятка математических, строковых и временных функций | Формулы (+, -, /, *, **) более 100 математических, финансовых, статистических, прогнозирующих, моделирующих, строковых и временных функций | |
| Оператор SELECT | REPORT | |
| Оператор INSERT | MAINTAIN ADD | |
| Оператор DELETE | MAINTAIN DELETE | |
| Оператор UPDATE | SET | |
| Оператор COMMIT | UPDATE |
Необходимо отметить, что различия этих технологий существенны. В таблице 2 приведено сравнение системных характеристик OLTP и OLAP.
| Таблица 2. |
| Системная характеристика |
Учетная система (OLTP) |
OLAP |
| Взаимодействие с пользователем |
На уровне транзакции |
На уровне всей базы данных |
| Данные, используемые при обращении пользователя к системе |
Отдельные записи |
Группы записей |
| Время отклика |
Секунды |
От нескольких секунд до нескольких минут |
| Использование аппаратных ресурсов |
Стабильное |
Динамическое |
| Характер данных |
Главным образом первичные (самый низкий уровень детализации) |
В основном производные (сводные значения) |
| Характер доступа к базе данных |
Предопределенные или статические пути доступа и отношения данных |
Неопределенные или динамические пути доступа и отношения данных |
| Изменчивость данных |
Высокая (данные обновляются с каждой транзакцией) |
Низкая (во время запроса данные обновляются редко) |
| Приоритеты |
Высокая производительность Высокая доступность |
Гибкость Автономность пользователя |
OLAP запросы к базам данных чаще всего бывают сложными и требуют много времени. Прямой доступ к OLTP-базе существенно снижает общую производительность оперативной системы. Разнообразные учетные системы неоднородны по типу используемых синтаксических соглашений и концептуальных допущений (единицы измерений, онтологии, наименование, кодирование и т.п.), поэтому их интеграция затруднена. Данные в учетных системах часто "зашумленные", неполные и несогласованные. Как правило, нет единой модели данных масштаба предприятия. Кроме того, при проектировании баз учетной системы могут использоваться разные модели данных (иерархическая, реляционная, объектно-ориентированная, плоские файлы, "фирменные" модели). В оперативных системах отсутствует метод предоставления данных для конкретных групп пользователей в нужной для них форме. Информация за прошлые периоды теряется при обновлении OLTP- базы (при записи в нее новых, актуальных данных).Это препятствует выполнению анализа временных тенденций, который так важен для многих сфер бизнеса. В OLTP-базе не хранятся данные в агрегированном, денормализованном, виде, что необходимо для оперативной аналитической обработки. А преобразование данных в процессе выполнения запросов оказывается слишком трудоемким.
Кроме всех перечисленных выше концептуальных различий, существуют еще и технологические проблемы, которые необходимо преодолеть для внедрения аналитических возможностей в учетные системы. Среди них можно назвать следующие сложности: различие в аппаратных платформах (компьютерах, сетях и периферийных устройствах), использование разного программного обеспечения (разнообразных операционных систем, СУБД, языков программирования, протоколов, связующего ПО и т.п.), а также географическое распределение баз данных по всей организации и вне ее.
Средства администрирования Cache'.
В стандартной поставке системы разработчику предлагается два средства администрирования Cache':
Configuration Manager Control Panel.
С помощью Configuration Manager можно выполнить следующие функции администрирования:
Создать новую БД, удалить или изменить настройки существующей БД. С точки зрения физического хранения, БД Cache' - это бинарный файл Cache'.DAT. Для каждой БД создается свой файл Cache'.DAT в отдельной директории. Определить область (Namespace) для существующей БД, под которой в Cache' понимается логическая карта, на которой указаны имена многомерных массивов - глобалей и программ файла Cache'.DAT, включая имена каталога-директории и сервера данных для этого файла. При обращении к глобалям используется имя области. Определить CSP-приложение. Для использования CSP-приложений необходимо определить виртуальную директорию на web-сервере, физическую директорию хранения CSP-приложений, а также несколько специфических для CSP настроек, таких как, к примеру, класс-предок для CSP приложений (по умолчанию принимается системный класс %CSP.Page). Определить сетевое окружение Cache'. В Cache' реализован собственный протокол работы с сетью распределенного окружения БД, носящий название DCP (Distributed Cache' Protocol). С помощью интерфейсов Configuration Manager можно определить источники данных в сети, а также определить связи между различными компонентами сети. Настройка системы Cache'. Разработчику предоставляется возможность конфигурирования различных компонент Cache', таких как параметры журналирования, настройки теневых серверов, параметры сервера лицензий, параметры Cache'-процессов и другие.
Утилита Control Panel предоставляет схожий набор функций администрирования и добавляет следующие новые:
Управление процессами Cache'. Настройка параметров защиты глобалей, таких как разрешение на редактирование/создание/чтение глобалей различными группами пользователей. Определение пользователей системы с присваиванием им имени пользователя, пароля и определение параметров доступа. Просмотр файлов журнала. Журналирование в Cache' выполняется на уровне глобалей. Определение теневых серверов системы. Создание резервных копий баз данных.
Средства проектирования
Средства проектирования в то время представляли собой всего лишь графические рисовальные системы. Некоторые участники считали, что требуется их развитие, хотя и не знали, в каком направлении.
Конечно же, ситуация значительно изменилась.
Статья про RM/T: основные идеи
Обратимся к некоторым интересным истинным расширениям модели. В 1979 г. Кодд опубликовал еще одну важную статью под названием "Extending the Relational Database Model to Capture More Meaning" [3]. Я буду называть эту статью статьей про RM/T по причинам, которые скоро станут понятны. Как следует из названия статьи, ее основной задачей является введение набора "семантических" расширений исходной модели. Однако статья начинается с обзора базовой модели (по состоянию на 1979 г.), и мне хотелось бы сделать по этому поводу несколько замечаний, прежде чем переходить к деталям предложенных расширений.
Прежде всего, думаю, что не ошибусь, утверждая, что статья про RM/T была первой статьей Кодда, где было введено явное определения термина реляционная модель! Вот это определение:
Реляционная модель состоит из:
Коллекции изменяемых во времени табличных отношений (с отмеченными выше свойствами - особо отметим ключи и домены) Правил вставки-обновления-удаления (Правила 1 и 2, упомянутых выше) Реляционной алгебры, описываемой ... ниже.
Отклоняясь от основной темы, я хочу привести несколько комментариев по поводу этого определения:
Может быть, это не столь важно, но мне кажется немного странным, когда говорят, что реляционная модель включает "коллекцию ... отношений" (разве коллекция отношений это не база данных?). Мне кажется более правильным говорить, что модель включает генератор типов RELATION, который дает пользователям возможность определения значений и переменных отношений (конечно, я предпочитаю термин "переменная отношения" термину Кодда "изменяемое во времени табличное отношение". "Правила 1 и 2, умомянутые выше" - это правила целостности сущности и ссылочной целостности. В более ранних статьях эти правила использовались более или менее неявно, не формулировались и не получали названий. Замечание: В действительности, формулировка правила ссылочной целостности была несколько дефектной, поскольку в ней не упоминалась возможность вхождения в состав внешнего ключа неопределенных значений.
Но конечно, это не является важным для вас, как и для меня, если мы не считаем появление понятия первичного ключа событием первостепенной важности. Реляционная алгебра, "описываемая ниже", включает обычные операции, а также дополнительные операции для работы с "неопределенными значениями" [sic]. В статье определяются следующие дополнительные операции: MAYBE O-JOIN, MAYBE DIVIDE, OUTER O-JOIN, NATURAL O-JOIN, OUTER NATURAL JOIN и OUTER UNION ("аналогичным образом можно было бы определить также OUTER-версии для INTERSECTION и DIFFERENCE"). Этот список операций порождает много вопросов - например, вопросы, связанные с ортогональностью и полнотой - но опять же, я не думаю, что это очень важно, поскольку считаю неопределенные значения и все, что с ними связано, ошибкой (по моему мнению, единственной большой ошибкой Кодда за все время его работы).
Также в статье про RM/T Кодд впервые явно упоминает идею реляционного присваивания. Однако это делается только в связи с предлагаемыми семантическими расширениями: присваивание не является частью приведенного определения "базовой реляционной модели", хотя, конечно, это часть базовой модели в ее современном понимании. Более того, не обсуждается тот факт, что операции INSERT, UPDATE и DELETE представляют собой лишь сокращенную форму записи некоторых реляционных присваиваний.
В третьих, в статье говорится следующее: "С реляционной моделью тесно связаны различные [семантические понятия]... Примерами являются ... (естественные) соединения без потерь и функциональные зависимости, многозначные зависимости и нормальные формы". Здесь мы имеем явное утверждение о той позиции Кодда, что эти понятия следует рассматривать в отрыве от модели как таковой (хотя я думаю, что впоследствии он изменил свою точку зрения по этому вопросу [4]).
В четвертых, в статье про RM/T Кодд также впервые использует идею суррогатов - т.е. определяемых системой идентификаторов. (Снова эта идея подается только в связи с предлагаемыми семантическими расширениями, хотя нет никаких оснований не использовать ее в базовой модели, и в пользу этого имеется много веских аргументов.) Однако, к сожалению, в статье утверждается, что суррогаты должны быть скрыты от пользователей - очевидное нарушение приведенного ранее в этой статье определения реляционной базы данных, в котором говорится, что все данные в базе данных должны быть доступны (авторизованным) пользователям.
На самом деле, можно было привести тот аргумент, что сокрытие суррогатов нарушает собственный Информационный Принцип Кодда, который устанавливает, что вся информация в базе данных должна явно представляться в терминах отношений и никак иначе.
(Отклоняясь от темы, позволю себе напомнить, что - как мы видели в моей заметке прошлого месяца - отношения являются единственными существенными конструкциями данных, допустимыми в реляционной базе данных. И я добавлю теперь, что отношения являются также единственными несущественными конструкциями, и тогда мы, в сущности, приходим к Информационному Принципу.)
Наконец, в статье про RM/T отведен один краткий (слишком краткий) раздел связи между реляционной моделью и логикой предикатов: "База данных [представляет собой] набор [высказываний] логики предикатов первого порядка... [Мы можем] вынести за скобки предикат, общий для набора простых высказываний, и затем трактовать [высказывания] как n-арное отношение, а этот предикат - как имя отношения". Кодд далее называет "пропозициональную" часть базы данных экстенсиональной, а предикатную часть - интенсиональной (оба эти слова являются техническими терминами логики). "Можно ... представлять интесиональную часть как набор ограничений целостности." И далее кратко сравниваются интерпретации замкнутого и открытого миров. (В интерпретации замкнутого мира отсутствие данной строки в данном отношении означает, что соответствующее высказывание ложно; в интерпретации открытого мира это означает, что мы не знаем, истинно высказывание или ложно.)
Статья про RM/T: Расширения
Как уже отмечалось, основная часть [3] посвящена расширенной версии реляционной модели, названной RM/T ("T - в честь Тасмании, где эти идеи были впервые представлены"). Статья начинается несколькими интересными предварительными замечаниями по поводу семантических расширений и "семантического моделирования данных" вообще:
"В действительности, задача поддержания смысла данных бесконечна. Поэтому термин "семантический" не должен интерпретироваться в каком-либо абсолютном смысле. Более того, модели баз данных, разработанные ранее (и иногда подвергаемые критике как "синтаксические"), не лишены семантических черт (возьмите, например, домены, ключи и функциональные зависимости). Цель [семантического моделирования], тем не менее, исключительно важна, поскольку даже незначительный успех может способствовать пониманию и порядку в области проектирования баз данных."
(Как приятно это отличается от преувеличенных заявлений, так часто встречаемых в области семантического моделирования!)
Далее Кодд делает другое хорошее замечание:
"В современных статьях о семантическом моделировании данных основной упор делается на структурные аспекты, иногда в ущерб манипуляционным аспектам. Структура без соответствующих операций и методов вывода - это что-то вроде анатомии без физиологии."
Хорошая аналогия!
Вернемся конкретно к RM/T. RM/T в целом относится к той же широкой категории, что и более хорошо известная "модель сущность/связь" (для краткости - E/R модель) [5]. Хотя и не реализованная в свое время (и, насколько мне известно, никогда позже), модель RM/T может служить - как и модель E/R - основой систематизированной методологии проектирования баз данных; на самом деле, лично я для использования в этих целях предпочитаю ее модели E/R, поскольку считаю, что она более точно определена. Некоторые очевидные различия между двумя этими моделями состоят в следующем:
В RM/T не проводится излишнее различие между сущностями и связями - связь рассматривается как специальный тип сущности. Структурные и целостные аспекты RM/T являются более мощными и более точно определенными, чем в модели E/R. RM/T включает собственные специальные операции, дополняющие набор операций базовой реляционной модели (хотя в этой области требуется дополнительная работа).
Коротко говоря, RM/T работает следующим образом:
Сущности (включая "связи") представляются E-отношениями и P-отношениями, которые являются специальными формами n-арных отношений общего вида. E- отношения используются для регистрации того факта, что некоторая сущность существует, P-отношения используются для регистрации свойств этих сущностей (все E-отношения имеют степень один, степень P-отношений не меньше двух). Между сущностями может существовать множество связей; например, типы сущностей A и B могут быть связаны в ассоциацию (термин RM/T для обозначения связи многие-ко-многим), или тип сущности Y может быть подтипом типа сущности X. RM/T включает формальную структуру каталога, с помощью которого такие связи могут быть сделаны известными системе. Тем самым система получает возможность поддержки различных ограничений целостности, порождаемых существованием таких связей. Как уже отмечалось, обеспечивается ряд операций высокого уровня для манипулирования различными объектами RM/T (E-отношениями, P-отношениями, отношениями-каталогами и т.д.).
В RM/T также обеспечивается схема классификации сущностей, которая во многих отношениях представляет собой наиболее значительный аспект - или, по крайней мере, наиболее видимый аспект - всей модели. Более конкретно, сущности классифицируются (хотя, заметьте, только неформально) в три категории, называемые ядрами, характеристиками и ассоциациями:
Ядра: Ядерные сущности - это сущности, обладающие независимым существованием; они говорят о том, "что это за база данных". Другими словами, ядра - это сущности, не являющиеся ни характеристикой, ни ассоциацией (см. ниже). Примерами являются поставщики и детали (но не поставки) в обычной базе данных поставщики-и-детали. Характеристики: Характеристическая сущность - это сущность, основное назначение которой состоит в описании или "характеризации" некоторой другой сущности. Примером могут служить отдельные пункты заказа в заказе клиента. Существование характеристик зависит от описываемой ими сущности.
Описываемая сущность может быть ядром, характеристикой или ассоциацией. Ассоциации: Ассоциативная сущность - это сущность, функция которой состоит в представлении связи многие-ко-многим (или многие-ко-многим-ко-многим...) между двумя или более другими сущностями. Примером являются поставки в знакомой базе данных поставщики-и-детали. Ассоциируемые сущности могут быть ядрами, характеристиками или ассоциациями.
Кроме того:
Сущности (все зависимости от их категории) могут обладать свойствами; например, детали имеют цвет, пункты заказа - стоимость, у поставок имеется объем поставки. В частности, любая сущность (снова вне зависимости от категории) может иметь свойство, указывающие на некоторую другую связанную сущность; например, заказы указывают на клиентов. Указание представляет связь многие-к-одному между двумя сущностями. Замечание: В действительности, идея указаний была добавлена позже [6] - ее не было в первой статье про RM/T. Поддерживаются супертипы и подтипы сущностей. Если B является подтипом A, то B - это ядро, характеристика или ассоциация в зависимости от того, представляет ли собой A ядро, характеристику или ассоциацию. Замечание: Однако в статье про RM/T абсолютно ничего не говорится по поводу связанного (и важного!) понятия наследования. Понятие супертипов и подтипов в RM/T больше похоже на понятие "супертаблиц и подтаблиц", предлагаемое в SQL3, чем на истинное наследование типов, обсуждаемое, например, в Третьем Манифесте.
Упомянутые понятия можно связать (не слишком точно) с их аналогами в E/R следующим образом: Ядро соответствует "регулярной сущности" E/R; характеристика - "слабой сущности" E/R; ассоциация - "связи" E/R (только для связей многие-ко-многим).
Замечание: В дополнение к аспектам, кратко обсужденным выше, RM/T также включает поддержку (а) временного измерения и (b) различных видов агрегации данных. Более подробное обсуждение можно найти в статье Кодда [3] или во вводном описании RM/T [6].
Стереотип администратора
В большинстве случаев не составит большого труда распознать среди сотрудников фирмы людей, отвечающих за БД. Их можно увидеть в конторе поздним вечером или в выходной день. Они преданы свему делу, заняты работой даже в нерабочие дни и у каждого из них есть сотовый телефон или пейджер. Некоторые из их задач, например, таких как обслуживание схемы , отнимают много времени и подвержены ошибкам. Без участия администратора не обходится решение ни одной мало-мальски серьезной проблемы, связанной с базой данных.
Стержневое отношение RO.
В выражении (4) случай, когда i = 2, определяет существование особого отношения RO со схемой [DOID:OID, S]. Обратим особое внимание на то, что, поскольку в этом отношении отсутствует Q-часть, его существование не может быть определено путем явного задания на уровне представления какого-либо качества Q и, следовательно, должно поддерживаться системой по умолчанию. Поскольку на уровне представления отношение R0 никак не представлено, то атрибут S отношения R0 не играет никакой роли и, в принципе, может отсутствовать. Следовательно, единственная информация содержащаяся в этом отношении - это информация об OID объектов. Это отношение соответствует вышеописанному качеству "уникальный объект" которое присуще любому объекту существующему в системе. На уровне представления качество "уникальный объект" является неявным а его значения - скрытыми. Логично предположить, что стержневое отношение R0 может содержать другую существенную для описания любого объекта системную информацию; в том числе оно должно содержать информацию, определяющую класс объекта (к этому мы вернемся позже).
В связи с отсутствием Q-части и неопределенностью атрибута S в качестве первичного ключа отношения R0 может использоваться только атрибут OID. Для всех остальных отношений Ri (i > 0) множества R атрибут OID должен рассматриваться как внешний ключ, связанный с первичным ключом отношения R0. Следствием этого является то, что каждому существующему в системе объекту будет обязательно будет соответствовать один и только один кортеж этого отношения. Таким образом, отношение R0 связывает кортежи всех остальных отношений по атрибуту OID, перечисляя OID всех существующих в системе объектов (по этим причинам оно может быть названо стержневым). Стержневое отношение является важнейшим компонентом модели "объект-качество", позволяющим представить множество кортежей различных отношений в виде единого объекта.
Стратегия распределенных вычислений. Краткий экскурс в историю.
Идея повторного использования кода не является чем-то принципиально новым в мире разработки программного обеспечения. Как известно, лень - двигатель прогресса (J). Если смотреть на вещи с несколько философской точки зрения, то все развитие человеческой цивилизации обусловлено возможностью основываться на результатах труда предшествующих поколений, расширяя и совершенствуя эту базу, в свою очередь, для наших потомков. Нет ничего удивительного поэтому, что попытки внедрения подобного подхода в области программных технологий предпринимались, наверное, еще на заре развития программирования. (Мы заведомо абстрагируемся от тех вырожденных случаев, когда условия оплаты заведомо подталкивали программистов к изобретению велосипеда и проч.) Сначала это, вероятно, был примитивный перенос кусков кода, который упростила директива #include, затем с появлением процедурных языков это стали библиотеки процедур, наконец, по мере того, как объектная парадигма овладела умами и чаяниями разработчиков средств разработки, их место в значительной степени заняли классы и библиотеки классов. Собственно говоря, перенесение основных свойств объектов окружающего нас мира в ту его прекрасную часть, которая относится к разработке софта,- возьмем хотя бы наследование- уже было подчинено идее переиспользуемости. Однако ни процедуры, ни классы не позволяли в полной мере воспользоваться преимуществами наследования от уже разработанных независимых модулей при создании достаточно сложного проекта, в особенности, если его предполагалось растиражировать для большого числа заказчиков. Основным препятствием была практическая невозможность установить новую версию библиотеки без ущерба для приложений, написанным с учетом предыдущих версий API. В общем случае это влекло за собой повторную компоновку, а то и компиляцию проекта, что вынуждало поставщика программного решения передавать клиенту не только исполняемые или (в крайнем случае) объектные модули, но и исходные тексты программ. Во-первых, очевидно, что это отнюдь не способствовало охране интеллектуальной собственности авторов, а во-вторых, даже эти жертвы становились напрасны, если клиент вдруг решал использовать средства разработки иного производителя.
Благим намерениям создателей С как некоего не зависящего от платформы стандарта языка программирования не суждено было сбыться, и со временем рынок ПО захлестнула волна компиляторов С/С++, для каждого из которых, как водится, немедленно возникли толпы поклонников, готовых истово отстаивать, что их любимый компилятор именно этой фирмы является самым компилятором в мире. На сегодня это число заметно уменьшилось, и страсти сами собой улеглись- речь не об этом. К несчастью, С++ не является единственным объектно-ориентированным языком, и если не столь долгое время назад заказчик желал, чтобы приобретенные у вас компоненты, написанные на том же , интегрировались в среду его "домашних" разработок, скажем, на Pascal'e, то это была далеко не тривиальная задача, где не спасали ни исходники, ни их косметическая правка. Таковы примерно были факторы, которые в конце концов привели к идее создания новой технологии и выработке стандартов, позволяющих избежать зависимости от конкретного средства разработки компонент и проводить эффективное обновление версий без негативных последствий для связанных с ними модулей. Реализация этой технологии, выполненная корпорацией Microsoft, получила название модели компонентных объектов (COM).
Структура стандарта и его характеристика
Стандарт SQL/89 состоит из 9 глав и 6 приложений. Первые три главы ("Назначениеи область применения", "Ссылки" и "Обзор") содержат достаточно формальную информацию, не существенную для пользователей.
В четвертой главе ("Понятия") на неформальном уровне описываются основные концепции языка, в том числе типы данных, столбцы, таблицы, ограничения целостности, схемы, привилегии, транзакции и т.д.
Пятая глава ("Общие элементы") содержит формальные определения(описание синтаксиса и семантики) элементов языка. К наиболее важным разделам этой главы относятся определения типов данных языка SQL/89; предикатов, которые допускается использовать в условиях выборки; общей структуры запросов.
Шестая глава ("Язык определения схем") посвящается средствам определения схемы БД в SQL/89.
В седьмой главе ("Язык модулей") описывается один из видов сопряжения SQL с традиционными языками программирования, наиболее близкий к так называемым хранимым процедурам (термин, широко используемый в большинстве современных коммерческих СУБД, но не определенный в стандарте).
Восьмая глава ("Язык манипулирования данными") содержит формальное описание синтаксиса и семантики наиболее важной для прикладного программирования части языка SQL - набора операторов непосредственного манипулирования хранимыми в БД данными.
Наконец, в девятой главе ("Уровни") специфицируются два уровня языка SQL/89. В основном это сделано для того, чтобы можно было объявить соответствующей стандарту какую-либо более старую реализацию, в которой не поддерживаются все свойства стандарта.
В приложениях (формально не являющихся частью стандарта) определяются общие правила встраивания конструкций языка SQL в программу, написанную на традиционном языке программирования, а также конкретные правила встраивания для языков программирования Кобол, Фортран, Паскаль и ПЛ/1.
Если характеризовать текст стандарта с точки зрения практически заинтересованного читателя, нужно заметить, что читать его (даже в переводе на русский язык)- это трудная и неприятная задача. Стремление добиться точных и недвусмысленных формулировок часто приводит к появлению совершенно неудобочитаемых предложений. Из имеющихся более просто читаемых толкований стандарта SQL/89 следует отметить одно из первых изданий книги Дейта "Стандарт SQL" (в последнем издании описан стандарт SQL/92). Лучшим способом изучения стандарта было бы чтение этой книги с параллельным заглядыванием в текст стандарта по мере необходимости. К сожалению, на русском языке эти книги не изданы(и, насколько мне известно, даже не переведены).
Структура запросов
Для того чтобы было можно более или менее точно рассказать про структуру запросов в стандарте SQL/89, необходимо начать со сводки синтаксических правил:
<cursor specification> ::=<query expression> [<order by clause><query expression> ::=<query term>| <query expression> UNION [ALL] <query term><query term> ::=<query specification>| (<query expression>)<query specification> ::=(SELECT [ALL | DISTINCT] <select list><table expression>)<select statement> ::=SELECT [ALL | DISTINCT] <select list>INTO <select target list><table expression><subquery> ::=(SELECT [ALL | DISTINCT] <result specification><table expression><table expression> ::=<from clause>[<where clause>][<group by clause>][<having clause>]
Язык допускает три типа синтаксических конструкций, начинающихся с ключевого слова SELECT: спецификация курсора (cursor specification), оператор выборки(select statement) и подзапрос (subquery). В основе каждой из них лежит синтаксическая конструкция "табличное выражение (table expression)".Семантика табличного выражения состоит в том, что на основе последовательного применения разделов from, where, group by и having из заданных в разделе from-таблиц строится некоторая новая результирующая таблица, порядок следования строк которой не определен и среди строк которой могут находиться дубликаты(т.е. в общем случае таблица-результат табличного выражения является мультимножеством строк). На самом деле именно структура табличного выражения в наибольшей степени характеризует структуру запросов языка SQL/89. Мы рассмотрим структуру и смысл разделов табличного выражения ниже, но до этого немного подробнее обсудим три упомянутые конструкции, включающие табличные выражения.
Структурированный язык запросов
Производя мониторинг запросов при их выполнении, самонастраивающийся оптимизатор сравнивает свои оценки с реальной мощностью результата на каждом шаге QEP и вычисляет поправки для оценок. Эти поправки могут использоваться для оптимизации аналогичных запросов в будущем. Более того, обнаружение погрешностей оценок может инициировать повторную оптимизацию запроса в середине его выполнения.
В оптимизаторе запросов используется математическая модель выполнения запросов для автоматического определения наилучшего способа доступа к данным и обработки любого заданного SQL-запроса. Эта модель существенно зависит от того, как оптимизатор оценивает число строк, которые будут получены на каждом из шагов плана выполнения запроса (query execution plan, QEP), особенно для сложных запросов, включающих много предикатов и/или операций. Такие оценки опираются на статистику базы данных и допущения модели, которые для конкретной базы данных могут оказаться как верными, так и неверными. В статье обсуждается самонастраивающийся оптимизатор запросов LEO (LEarning Optimizer for DB2), который автоматически проверяет достоверность своей модели, не требуя какого-либо вмешательства пользователя для изменения некорректной статистики или оценок мощности результатов запросов. Производя мониторинг запросов при их выполнении, самонастраивающийся оптимизатор сравнивает свои оценки с реальной мощностью результата на каждом шаге QEP и вычисляет поправки для оценок. Эти поправки могут использоваться для оптимизации аналогичных запросов в будущем. Более того, обнаружение погрешностей оценок может инициировать повторную оптимизацию запроса в середине его выполнения. Автоматическое совершенствование модели оптимизатора может привести к уменьшению времени выполнения запроса на несколько порядков при незначительном увеличении затрат времени исполнения. LEO собирает данные о мощности результатов, получаемых при доступе к таблицам, и корректирует погрешность оценки для простых предикатов путем согласования статистики базы данных DB2 в расчете на будущие запросы.
Поразительный рост индустрии реляционных систем управления базами данных (РСУБД) за последние два десятилетия во многом объясняется стандартизацией структурированного языка запросов. SQL — декларативный язык, т. е. при его использовании требуется, чтобы пользователь указал только то, какие данные ему желательно получить, оставляя на долю оптимизатора запросов РСУБД принятие трудного решения о том, как лучше всего получить доступ к данным и обработать их. Для данного SQL-запроса может иметься много разных способов доступа к каждой из таблиц, к которой адресован запрос, способов соединения этих таблиц и, поскольку операция слияния коммутативна, способов упорядочения этих слияний и выполнения других операций, требуемых для окончательной обработки запроса. Тем самым, могут существовать сотни или даже тысячи возможных способов корректной обработки данного запроса. Например, пусть имеется следующий SQL-запрос:
SELECT name, age, salary
FROM employees
WHERE age > 60 AND city = ‘SAN JOSE ‘ AND salary < 60,000
В этом запросе ищутся имя, возраст и зарплата каждого служащего старше 60 лет, проживающего в Сан-Хосе и получающего менее 60 тыс. долл. в год. Каждое фильтрующее условие в разделе WHERE, соединенное с другими с помощью AND, называется предикатом. Поскольку этот запрос обращен только к одной таблице, не встает вопрос о выборе порядка соединений или методе их выполнения, но все равно оптимизатор может принимать во внимание много разных способов выполнения этого простого запроса в РСУБД. Всегда можно последовательно сканировать все строки в таблице, применяя каждый предикат к каждой строке. Либо, если существуют подходящие индексы, можно использовать один или несколько индексов для доступа только к тем строкам, которые удовлетворяют одному или нескольким предикатам. Так, индекс на столбце age позволил бы обращаться только к тем строкам, в которых значение возраста больше 60, а затем применять другие предикаты (касающиеся города и зарплаты). Наличие индекса на столбце city позволил бы ограничиться доступом только к тем строкам, в которых значение столбца городов равно «Сан-Хосе», а затем последовательно применять к извлекаемым строкам другие предикаты (касающиеся возраста и зарплаты).
Или же могут быть использованы индексы на нескольких столбцах таблицы, например, комбинированный индекс по городу и возрасту или комбинированный индекс по городу и зарплате, если такие индексы существуют, либо стратегии, комбинирующие индексы (так называемая «конъюнкция индексов» — index ANDing). Какая стратегия окажется предпочтительней, зависит от характеристик базы данных, наличия различных индексов и того, насколько селективен каждый предикат, т.е. сколько строк удовлетворяют каждому из условий.
В большей части современных оптимизаторов запросов наилучший план выполнения запроса (QEP, или просто план) определяется путем математического моделирования затрат на выполнение каждого плана из набора альтернативных QEP и выбора плана с самой низкой оцененной стоимостью. Стоимость выполнения существенно зависит от числа строк, которые будут обработаны каждой операцией в QEP, поэтому оптимизатор оценивает стоимость главным образом инкрементально, по мере применения каждого из предикатов. Методы оценки мощности (т.е. числа строк) результата после того, как были применены один или несколько предикатов, являлись предметом многих исследований, проводившихся в последние 20 лет [1-5]. Чтобы избежать обращений к базе данных при оптимизации запросов, эта оценка обычно опирается, прежде всего, на статистику характеристик базы данных, в частности, число строк в каждой таблице. Мощность каждого из промежуточных результатов выводится инкрементальным образом, путем умножения числа строк в базовой таблице на коэффициент фильтрации, или селективности, для каждого предиката в запросе. Этот коэффициент вычисляется на основе статистических параметров столбцов, к которым применяется данный предикат, таких как число различных значений или гистограмма их распределения. Селективность предиката P, по существу, представляет собой вероятность того, что некоторая строка в таблице будет удовлетворять условию предиката P, и эта селективность зависит от характеристик базы данных. Например, в приведенном выше запросе предикат на столбце city мог бы быть достаточно селективным, если бы база данных была всемирной базой данных крупной международной компании, но мог бы оказаться значительно менее селективным, если бы база данных содержала сведения обо всех служащих небольшой начинающей компании, базирующейся в Сан-Хосе.
В последнем случае предикаты на age и/или salary были бы более селективными. Оптимизатор отдал бы предпочтение тем QEP, в которых могли бы использоваться индексы для применения наиболее селективных предикатов, и тем QEP, в которых используется простое сканирование таблиц, если индексов не существует или если, по оценкам оптимизатора, большинство записей о служащих удовлетворяет всем предикатам. В DB2 выбор QEP опирается исключительно на детализированные оценки стоимости каждого из конкурирующих планов, а не на такую упрощенную эвристику.
Если в разделе FROM запроса указано несколько таблиц, число альтернативных стратегий, учитываемых оптимизатором, растет экспоненциально, поскольку помимо множества возможностей выбора, упомянутых выше, приходится принимать дополнительные решения о том, в каком порядке и на основе какого метода соединяются таблицы. В DB2, к примеру, поддерживаются три основных типа методов соединения, причем для каждого из них существует несколько вариантов. Для соединения двух таблиц с небольшим числом предикатов оптимизатор DB2 может учитывать свыше сотни различных планов; для шести таблиц планов может быть больше тысячи! Оптимизатор DB2 анализирует все эти альтернативы автоматически, причем пользователь даже не знает об этом!
Хотя оптимизаторы запросов достаточно хорошо оценивают стоимость и мощность результата для большинства запросов, в основе этой математической модели лежат определенные допущения. К подобным допущениям относятся срок действия информации, равномерность, независимость предикатов и принцип включения.
Срок действия информации. Обновление статистики при каждом изменении или удалении строки привело бы к появлению блокирующего узкого места в системных каталогах, в которых хранится статистика. Некоторые статистические параметры трудно и даже невозможно подсчитывать инкрементально, например, число различных значений в каждом столбце. Поэтому принято пересчитывать статистику периодически с помощью вызываемой пользователем пакетной операции (в DB2 она называется RUNSTATS).
Несмотря на это, оптимизатор предполагает, что статистика отражает текущее состояние базы данных, т. е., что характеристики базы данных относительно стабильны. Считается, что пользователь знает, когда какая-то таблица меняется настолько существенно, что выполнение дорогостоящей операции пересчета статистики становится оправданным.
Равномерность. Хотя во многих продуктах используются гистограммы для преодоления трудностей со скошенными распределениями значений для «локальных» предикатов выборки (по столбцам одной таблицы), мы не знаем каких-либо доступных продуктов, в которых использовались бы гистограммы для предикатов соединения, т. е. предикатов, связывающих столбцы нескольких таблиц. Таким образом, для предикатов соединения оптимизатор запросов по-прежнему опирается на предположение о равномерности.
Независимость предикатов. Селективность каждого предиката вычисляется по отдельности, а затем эти значения перемножаются, т. е., по существу, предполагается, что предикаты статистически независимы друг от друга, несмотря на то, что используемые столбцы могут быть связаны, например, функциональной зависимостью. Хотя многомерные гистограммы решают эту задачу для локальных предикатов, они никогда не применяются к предикатам соединения, агрегации и т.д. В распространенных сегодня приложениях содержатся сотни столбцов в каждой таблице и имеются тысячи таблиц, что делает невозможным выяснить, на каком подмножестве столбцов следует поддерживать многомерную статистику.
Принцип включения. Селективность предиката слияния X.a = Y.b обычно определяется как 1/max {|a|, |b|}, где |b| — это число различных значений в столбце b. Это неявно предполагает наличие «принципа включения», означающего, что для каждого значения из меньшего домена имеется пара в большем домене. К счастью, это предположение зачастую истинно для большинства соединений между первичным ключом таблицы (например, номером продукта в таблице «Продукты» (Products)) и ссылкой на этот ключ (внешним ключом) в другой таблице (например, в таблице «Заказы» (Orders)).
В тех ситуациях, когда эти предположения неверны, возникают существенные ошибки в оценках мощности и, следовательно, стоимости, что приводит к выбору неоптимальных планов. По опыту авторов, основная причина серьезных ошибок моделирования — некорректная оценка мощности, от которой зависит стоимость. Для данной мощности оценки стоимости могут отклоняться от истины на 10-15%, но оценки мощности могут отклоняться от истинных значений на несколько порядков, если базовые предположения неверны или сомнительны. Хотя достигнут значительный успех при использовании гистограмм для определения и корректировки скашивания данных [6-8], а также при использовании образцов для сбора актуальной статистики [9, 10], пока не существует исчерпывающего подхода к исправлению всех модельных ошибок вне зависимости от их источника.
LEO [11] обучается при обнаружении любой ошибки моделирования в любой точке QEP, автоматически сравнивая свои оценки с реальными мощностями промежуточных результатов запроса. Определение того, в какой точке плана возникла существенная ошибка, позволяет повторно оптимизировать запрос в этой точке [12] и динамически настраивать модель оптимизатора для лучшей оптимизации последующих запросов. Со временем этот метод обратной связи приводит к накоплению эмпирической информации, которая расширяет и настраивает статистику базы данных для той ее части, к которой чаще всего обращаются пользователи. Эта информация не только повышает качество оценок оптимизатора, но и также определяет, где следует сконцентрировать сбор статистики, и может даже избавить от необходимости сбора статистики.
СУЩЕСТВЕННОСТЬ
Несмотря на важность этого понятия, исходя из собственного опыта, я считаю, что с этим понятием реально знакомы лишь немногие профессионалы в области баз данных. Поэтому эта заметка представляет собой в основном введение в этот предмет. Замечание: Следующий далее материал частично основан на одной из моих предыдущих статей [6].
Прежде всего, "всем известно", что единственной структурой данных, используемой в реляционной модели, является отношение. Однако, чтобы понять значимость этого факта, требуется знать по крайней мере одну другую структуру данных, например, структуру связей, поддерживаемую в иерархических и сетевых системах. Рассмотрим пример. На Рис. 1 показаны (a) реляционный проект простой базы данных "отделы-сотрудники" и (b) сетевой эквивалент этого проекта. (На самом деле, пример прост по той причине, что в сетевом исполнении проект представляет собой скорее иерархию, но это не важно для нашей цели. Иерархии и сети в большей степени похожи друг на друга, чем на отношения.)

Рис. 1. Отделы и сотрудники: реляционный и сетевой проекты
В сетевом проекте использован "набор (set) в смысле CODASYL" (не нужно путать это понятие с понятием математического множества!). Каждый экземпляр этого набора включает строку DEPT, множество соответствующих строк EMP и экземпляр связи ("DEPTEMP"), соединяющей эти строки DEPT и EMP. (Я использую здесь термин "строка" вместо более принятого слова "запись", чтобы обойти несущественные вопросы, связанные с различием в терминологии этих двух подходов.) Можно представлять ссылку в данном наборе CODASYL как цепочку указателей - указатель от строки DEPT на первую строку EMP для этого отдела, указатель от этой строки EMP на следующую строку для того же отдела и т.д., и, наконец, указатель от последней строки EMP на исходную строку DEPT. Замечание: Эти указатели не обязательно представляются на физическом уровне хранения как реальные указатели, но пользователи обязаны отоситься к ним как к реальным указателям. (Такова сетевая модель!)
Заметим теперь, что строки EMP в сетевом проекте не включают столбец DEPT#. Поэтому для того, чтобы найти, в каком отделе числится данный служащий, нам требуется пройти по экземпляру связи DEPTEMP от требуемой строки EMP к соответствующей строке DEPT; аналогично, чтобы найти служащих данного отдела, нам нужно пройти по экземпляру связи EMPDEPT от требуемой строки DEPT к соответствующим строкам EMP. Другими словами, информация, которая была бы представлена внешним ключом в реляционном проекте, представляется ссылкой в сетевом проекте; ссылки являются сетевым аналогом внешних ключей (вольно выражаясь).
Рассмотрим теперь пару запросов по отношению к этой базе данных. Для каждого запроса я покажу реляционную формулировку (SQL) и ее сетевой эквивалент с использованием гипотетической расширенной версии SQL, в которой поддерживаются связи.
Q1: Получить номера и имена служащих с заработной платой, большей 20K.
| Реляционная формулировка: | Сетевая формулировка: |
| SELECT EMP#, ENAME | SELECT EMP#, ENAME |
| FROM EMP | FROM EMP |
| WHERE SALARY > 20K ; | WHERE SALARY > 20K ; |
| Реляционная формулировка: | Сетевая формулировка: |
| SELECT EMP#, ENAME | SELECT EMP#, ENAME |
| FROM EMP | FROM EMP |
| WHERE SALARY > 20K | WHERE SALARY > 20K |
| AND DEPT# = 'D3' ; | AND ( SELECT DEPT# FROM DEPT OVER EMP ) = 'D3' ; |
Таким образом, Q2 иллюстрирует тот важный момент, что для сетей определенно требуются дополнительные операции доступа к данным.
Отметим также, что эти операции являются дополнительными; реляционные операции, как показывает Q1, по-прежнему необходимы. Более того, заметим, что это замечание относится не только ко всем операциям манипулирования данными (включая операции обновления), но также и к операциям определения, операциям обеспечения безопасности, операциям обеспечения целостности и т.д. Следовательно, связи в сетевых структурах данных определенно добавляют сложность. Однако они не дают дополнительной мощности - нет ничего, что можно было бы представить с помощью сетей и нельзя было бы представить с помощью отношений; нет такого запроса, который можно было бы представить сетевой системе и нельзя бы представить системе реляционной.
Иногда говорят, что можно уменьшить сложность путем добавления к EMP компонента DEPT# (внешнего ключа), как это показано на Рис. 2. В этом доработанном варианте запрос Q2 (сетевая версия) может формулироваться без конструкции OVER; на самом деле, формулировка эквивалента реляционной. Причина этого состоит в том, что DEPT и EMP в этом пересмотренном проекте означают то же самое, что и в реляционном варианте; база данных такая же, что и реляционная, если не принимать во внимание связь DEPTEMP. Но эта связь является полностью избыточной - она не представляет какую-либо информацию, которая не представлена также и внешним ключом. Поэтому мы можем игнорировать эту связь без потери какой-либо функциональности.

Сеть: связь DEPTEMP не является существенной
Рис. 2. Отделы и сотрудники: сетевой проект с внешним ключом EMP.DEPT#
Теперь (наконец!) я поясню смысл понятия существенности. Конструкция, связанная с данными, существенна, если ее утрата вызывает потерю информации - вполне точно, я понимаю это так, что перестанет достигаться некоторое отношение. Например, в реляционном варианте базы данных отделов и сотрудников все конструкции данных в этом смысле существенны. Аналогично, в начальной сетевой версии (Рис. 1) все конструкции (все строки, все столбцы и все связи) тоже существенны.
Но в пересмотренном сетевом варианте (Рис. 2) строки и столбцы продолжают быть существенными, а связь - нет. Нет такой информации, которую можно было бы получить из сети и нельзя было бы получить только из строк и столбцов; вообще отсутствует логическая потребность в связи.
Замечание: Некоторые люди думают, что имеет место обратная ситуация - существенна именно связь, а не внешний ключ. Но это противоречит тому, что поскольку некоторые строки и столбцы должны быть существенными и ничего больше не требуется, то зачем нам нужно что-то еще?
Теперь (наконец) я могу пояснить, в чем состоит принципиальное различие между реляционной базой данных и базой данных другого рода, скажем, сетевой. В реляционной базе данных единственной существенной конструкцией данных является отношение. В других базах данных должна присутствовать по меньшей мере одна дополнительная существенная конструкция данных (такая, как существенная связь). Если бы это было не так, то база данных была бы по существу реляционной с явной демонстрацией некоторых путей доступа. (Не требуется, чтобы пользователи явно применяли эти пути доступа; единственный вопрос состоит в том, почему мы показываем эти пути доступа, а другие не делают этого.) И именно эти дополнительные существенные конструкции данных в основном (но не полностью) приводят к сложности нереляционных баз данных.
Замечание: Конкретно, в случае CODASYL имеется, по меньшей мере, четыре дополнительных конструкции, которые могут использоваться для существенного сохранения информации. Однако рассмотрение подробностей этих конструкций могло бы завести нас слишком далеко.
Сущность "ОID".
Представим адресное пространство R*O-системы в виде отношения OIDs имеющего поле OID в качестве первичного ключа. Ранее отмечалось, что информация о OID является существенной для любого кортежа RxO системы. Поэтому любое отношение, содержащее информацию об объектах, должно иметь поле OID, которое должно быть объявлено как внешний ключ, ссылающийся на поле OID отношения OIDs. Данная связь определяет, атрибутами каких именно объектов являются определенные кортежи этих отношений . После этого проекцию SR-SA
можно будет представить в следующем виде (рис.7)

Рис. 7. R-проекция после введения таблицы OID (классы на рисунке не представлены)
Отношение OIDs фактически отражает наличие сущности являющейся общей и обязательной для любого объекта. Смысл данной сущности можно выразить выражением "идентифицируемый объект". Множество значений первичного ключа (поля OID) отношения OIDs фактически является адресным пространством O-проекции R*O-системы. Существование любого объекта системы определяется существованием кортежа отношения OIDs, содержащего уникальный OID этого объекта. Очевидно,что отношение OIDs может содержать и другую информацию, существенную для любого объекта системы. К информации такого рода относится информация определяющая класс объекта (СlassID).
Сужение с TREAT
Oracle предоставляет специальную функцию TREAT, которая позволяет выполнять операцию сужения. Функция TREAT явно изменяет объявленный тип источника в присваивании на более специализированный тип или подтип в иерархии места назначения.
Для успешного сужения нужно использовать TREAT; без использования этой функции, вы не сможете сослаться на специфичные для подтипа атрибуты и методы.
Вот общий синтаксис этой функции:
TREAT (<object instance> AS <object type>)
где <object instance> - это значение столбца или строки коллекции данного конкретного супертипа в объектной иерархии, а <object type> - это подтип в этой иерархии.
Давайте рассмотрим несколько примеров использования TREAT. Предположим, что я вставил три строки в таблицу meal, как показано в Листинге 3. Обратите внимание, что в третьей строке я передал десерт в качестве главного блюда, одно из любимых занятий моего сына во время еды! Я смог сделать это, поскольку не ограничил подставляемость столбца main_course.
Предположим, что я хочу видеть список всех приемов пищи, в которых десерт указан в качестве главного блюда. Я использую оператор TREAT в предложении WHERE:
Функция TREAT - которую, кстати, в Oracle9i версии 1 можно использовать только в операторах SQL (но не в PL/SQL блоках) - возвращает объектный тип NULL для любых главных блюд, не являющихся десертами.
Допустим, я хочу узнать, содержит ли какое-нибудь из моих главных блюд шоколад. Этот атрибут характерен для десертов, поэтому если я попытаюсь напрямую сослаться на этот атрибут без TREAT, мой запрос завершится с ошибкой, как показано ниже:
SQL> SELECT main_course.contains_chocolate 2 FROM meal 3 WHERE TREAT (main_course AS dessert_t) 4 IS NOT NULL; SELECT main_course.contains_chocolate * ERROR at line 1: ORA-00904: invalid column name
Даже если все выбранные главные блюда являются десертами, у Oracle нет возможности узнать это; столбец main_course объявлен как тип food_t. Итак, что я должен делать? Использовать функцию TREAT в списке SELECT также как в запросе! Этот запрос и результаты представлены в Листинге 4.
Я могу также использовать TREAT в DML операциях, таких как INSERT'ы и UPDATE'ы. Предположим, например, что я не хочу разрешать вставлять в таблицу meal такие строки, в которых десерт является основным блюдом. Я могу добавить ограничение на таблицу, чтобы предотвратить это, но я также могу удалить все такие строки, используя UPDATE вместе с TREAT.
Только помните, что мы пока не можем использовать TREAT вне SQL оператора, напрямую в родном PL/SQL коде. Возможно, мы получим PL/SQL TREAT в Oracle9i версии 2.
Связи и ссылки
Все связи имеющиеся в R*O-системе фактически являются связями между отношениями т.е . связями характерными для R-системы. Однако существует особый случай который описывает связи характерные для O-систем
Связи между объектами в O-системах осуществляются с помощью элементов специального типа, которые могут быть названы ссылками(или указателями). Понятие "ссылка" определяется и поддерживается системой; структура элемента имеющего тип "ссылка на объект определенного класса" не зависит от типа объекта на который данная ссылка указывает.
По сути дела ссылка определяет существование осмысленной связи между двумя идентифицируемыми объектами. В терминах R*O, где существование объекта определяеться существованием кортежа отношения OIDs, содержащим OID некоторого объекта, эта связь может быть описана парой значений OID. Одно значение соответствует содержащему эту ссылку объекту, второе определяет объект, на который первый объект ссылаеться. Кроме того, должно быть определено семантическое значение ссылки в контексте содержащего ее объекта. [2].
Исходя из этого, для описания и сохранения элементов ссылочного типа можно использовать специальное отношение LINKs .
| Столбец | Тип | Ключ | Описание |
| OID | TypeOID | References (OIDs)OID | OID объекта содержащего ссылку |
| SID | TypeSID | References (SCHEMA)SemanticID | SID определяющий смысл ссылки в объекте |
| RefOID | TypeOID | References (OIDs)OID | OID объекта, на который указывает ссылка |
Отношение LINKs соответствует сущности, смысл которой можно выразить выражением "осмысленная связь между идентифицируемыми объектами".
В связи с тем, что поле refOID отношения LINKs является внешним ключом, связывающим эту отношние с отношением OIDs, кортеж этого отношения, а следовательно и объект, существование которых определено этим кортежем, невозможно удалить до тех пор, пока в системе будут присутствовать ссылки (кортежи отношения LINKs) на данный объект. Таким образом для поддержки O-ссылочной целостности в R*O-системе используются реляционные механизмы.
Пары значений OID и refOID некоторого кортежа отношения LINKs описывает соотношение "содержащий -включенный", существующее между двумя идентифицируемыми объектами системы. Следует отметить, что все пары OID и refOID, существующие в отношении LINKs, в целом описывают сложную неоднородную сетевую структуру переменной глубины, которая является следствием возможного существования в системе любого числа элементов любого числа полей любого числа ссылочных типов, описанных в любом числе классов. [2]
Однако наличие в этой таблице поля SID, определяющего семантическое значение ссылок в контексте содержащих их объектов, позволит определить для множества ссылок, имеющих одинаковое семантическое значение, правила, присущие связи, которая этим семантическим значением характеризуется.
Пример: предположим, что в системе должна сохраняться информация о людях (физических лицах) являющихся сотрудниками фирм (юридических лиц). Логично описать это, определив в классе "Фирма" множество ссылок на объекты класса "Человек" имеющих семантическое значение "сотрудник" = SIDX (это множество является группой повторения).
Class Person extended Client { .... } Class Firm extended Client { Person [] emloyee; ... }
Существует правило, согласно которому человек (объект идентифицируемый неким OIDY) может являться сотрудником только одной фирмы. Тогда в множества кортежей отношения LINKs (среди всех ссылок существующих в системе) не может существовать более одного кортежа со значениями поля SID = SIDX и поля refOID = OIDY.
Пример: предположим, что в системе должна сохраняться информация о родственных связях людей (имеется в виду связь "родитель - ребенок"). Логично описать эту связь, определив в классе "Человек" множество ссылок на объекты класса "Человек" имеющих семантическое значение "ребенок" = SIDК
(это множество является группой повторения).
Class Person extended Client { Person [] children .... }
Тогда множество кортежей отношения LINKs имеющих данное семантическое значение определяет существование однородной структуры переменной глубины, которая фактически описывает генеалогическое древо.
Поскольку человек ( объект идентифицируемый неким OIDМ) обязательно должен иметь двух родителей., в множества кортежей отношения LINKs (среди всех ссылок существующих в системе) должно существовать два кортежа со значениями поля SID = SIDK и поля refOID = OIDM.
R*O поддерживает ссылочные конструкции характерные для навигационного способа доступа к данным [14,22,25] присущего сетевым и иерархическим системам [2].
Пример (использует два предыдущих примера ) предположим, что необходимо получить информацию о детях сотрудников фирмы. Для этого логично использовать констукцию
... employee.children ...
которая является примером навигационного способа доступа к данным. В терминах R*O эта конструкция описывает реляционное соединение 2-х подмножеств кортежей отношения LINKs : подмножество кортежей имеющих семантическое значение "сотрудник" (по полю refOID) с подмножеством кортежей имеющих семантическое значение "ребенок" (по полю OID).
Таким образом R*O позволяет представить ссылочные конструкции в терминах реляционных систем.
по сравнению со стандартом
В стандарте SQL/ 92 по сравнению со стандартом SQL/89 язык был расширен главным образом количественно, хотя даже этих количественных расширений оказалось достаточно для того, чтобы стандарт SQL/92 не удалось полностью реализовать до сих пор в большинстве коммерческих СУБД. Поскольку SQL/92не удовлетворял значительной части претензий, исторически предъявляемых к языку SQL, был сформирован новый комитет, который должен выработать стандарт языка с качественными расширениями. Язык SQL-3 пока не сформирован полностью, многие аспекты продолжают обсуждаться. Поэтому к приводимой здесь сводке возможностей нужно относиться как к сугубо предварительной.
Свойства модели "объект-качество" и реализующей ее системы.
Повторим, что ортогональность означает, что каждая из компонент системы типов обладает определенным и присушим только ей набором свойств. Неоднократно показано, что эти свойства являются несовместимыми, однако эта несовместимость является следствием попыток совместить их путем создания некоего универсальный тип. Задачу же следует ставить по-другому - надо описать данные одновременно и как объекты и как отношения, а эта задача решена изначально. Наше знание о любой вещи является совокупностью знаний о качествах этой вещи, а качества, как мы уже показали, являются реляционным понятием. Таким образом информации, возникающей в процессе познания окружающего мира уже обладает требуемой структурой, являющейся и объектной и реляционной одновременно. Следовательно мы можем говорить о том, что модель "объект-качество" обладает и объектными и реляционными свойствами.
Каждая из ортогональных компонент системы типов обладает своими собственными свойствами. Например, один из механизмов, реализующих принцип инкапсуляции, заключается в том, что доступ к определенным атрибутам объекта может быть разрешен или запрещен. Информация об таких ограничениях, присущих объектным системам, должна содержаться в описании класса объекта (public и private атрибуты), т.е. в объектной компоненте системы типов. Однако если мы получили доступ к какому либо качественному атрибуту, то данные, хранящиеся в нем, будут доступными полностью. Это является следствием того, что структура этого атрибута описана уже в реляционной компоненте системы типов, а реляционная модель не накладывает никаких ограничений на доступ к данным.
Не следует путать свойства определяемые моделью данных и механизмы присущие системам хранения информации. Например, несмотря на то, что триггеры присущи обычно именно реляционным БД, их существование никак не обуславливается реляционной моделью. В системах, реализующих модель "объект-качество", возможно определять и переопределять триггер для атрибута объекта. В этом случае триггеры можно рассматривать уже как механизм реализующий объектные принципы инкапсуляции и полиморфизма.
Последний пример является хорошей иллюстрацией слияния механизмов, присущих объектным и реляционным системам, которое возможно в системе, реализующей модель "объект-качество". Тот же триггер для качественного атрибута объекта может быть описан как метод класса. Также в виде метода класса может быть оформлено выражение, возвращающее переменную отношения, причем эта переменная может быть и собственно качественным атрибутом, и временной переменной, возникшей в результате выполнения реляционных операция над качественными атрибутами - в этом случае мы говорим о виде (механизм реляционных систем) оформленном в виде метода (объектное понятие).
С другой стороны, тот факт, что система, реализующая модель "объект-качество", основана на реляционных принципах, позволяет использовать механизмы поиска и групповой обработки данных, присущих реляционным БД, применительно к объектам (традиционные объектные системы предполагают, что для этой цели должны использоваться итераторы, последовательно перебирающие объекты). На уровне хранения каждому качеству Q соответствует одно единственное отношение R, в котором хранятся все существующие в системе и описывающие разные объекты значения этого качества. Такая организация данных позволяет, например, обратиться к значениям атрибута Attr у множества объектов класса C (а также всех классов C',C''... - наследников С), имеющего качественный тип Q. Для этого на уровне представления может быть использовано следующее выражение
UPDATE C.Attr SET C.Attr.i =.... WHERE C.Attr.j >...//условие отбора
которое при переходе на уровень хранения преобразуется системой к виду
UPDATE R SET R.i.... WHERE R.S = "Attr" AND R.J> ..// условие отбора
где R - отношение соответствующее качеству Q
Более того. Реляционная природа описываемой системы позволяет реализовывать свойства, принципиально невозможные в традиционных объектных системах. В последних ссылка считается единственным способом доступа к объекту. Следовательно, обязательно должны существовать ссылка на любой созданный объект, то есть объекты должны быть обязательно включены в иерархию объектов.
Если ссылки на объект не существует, то он считается потерянным и без пользы занимает память или уничтожается специальным сборщиком. Но в системе, реализующей модель "объект-качество", объект может существовать сам по себе, даже если ссылки на него отсутствует. Доступ к его данным может быть осуществлен с помощью групповых операций и, в конце концов, с помощью этих же групповых операций мы имеем возможность вновь получить ссылку на этот объект. Для того, что бы получить набор ссылок на объекты удовлетворяющие определенному условию на уровне представления можно использовать выражения вида
SELECT * FROM C WHERE C.Attr.i =...//условие отбора
которое на уровне хранения преобразуется системой например к следующему виду
SELECT R.OID FROM R WHERE R.S = "Attr" AND R.i =...//условие отбора
Модель "объект-качество" позволяет разрешить некоторые теоретические вопросы, обычно возникающие при противопоставлении объектных и реляционных систем. Одним из таких вопросов является вопрос об истинности утверждения, что постоянство хранения ортогонально типу (POTT). Сторонники объектных систем хранения информации утверждает, что объекты должны быть хранимыми и это свойство (которое может быть названо "хранимость" или "постоянство") должно быть прозрачным для программиста - другими словами "хранимость" ортогональна типу. Сторонники же реляционных систем утверждают обратное - все данные должны явно сохраняться в виде отношений, т.е. хранимость должна явным образом выражаться через тип отношения.
Если рассматривать этот вопрос с позиций модели "объект-качество", то никакого противоречия в этих утверждениях нет. Действительно, для классов "хранимость" является ортогональным свойством, поскольку оно определяется через ортогональную систему качественных типов, являющихся отношениями. Объект, являющийся множеством кортежей обладающих свойством "хранимость", сам, таким образом, является хранимым.
К сожалению ограничения по объему статьи не позволяют рассмотреть систему, основанную на модели "объект-качество" более подробно.Однако и то, что уже сказано, позволяет рассматривать эту модель как интересный объект для исследования и реализации.
