Некоторые термины и определения, используемые при работе с базами данных
Используемая терминология различна в теории реляционных баз данных, на стадии проектирования концептуальной модели и при практической работе с физической моделью и с базой данных, как это показано далее. Приведенные термины очень важны, однако для начинающих изучать данный предмет могут оказаться сложными для понимания. К этим формулировкам рекомендуется периодически возвращаться (после изучения следующих разделов курса) для их четкого усвоения. Основная часть первоисточников по теории баз данных, а также средства разработчиков используют английскую терминологию, поэтому для большинства русских терминов приведены соответствующие английские значения.
База данных (БД, database) - поименованная совокупность структурированных данных, относящихся к определенной предметной области.
Предметная область - некоторая часть реально существующей системы, функционирующая как самостоятельная единица. Полная предметная область может представлять собой экономику страны или группы союзных государств, однако на практике для информационных систем наибольшее значение имеет предметная область масштаба отдельного предприятия или корпорации.
Система управления базами данных (СУБД) - комплекс программных и языковых средств, необходимых для создания и модификации базы данных, добавления, модификации, удаления, поиска и отбора информации, представления информации на экране и в печатном виде, разграничения прав доступа к информации, выполнения других операций с базой.
Реляционная БД - основной тип современных баз данных. Состоит из таблиц, между которыми могут существовать связи по ключевым значениям.
Таблица базы данных (table) - регулярная структура, которая состоит из однотипных строк (записей, records), разбитых на столбцы (поля, fields).
В теории реляционных баз данных синоним таблицы - отношение (relation), в котором строка называется кортежем, а столбец называется атрибутом.
В концептуальной модели реляционной БД аналогом таблицы является сущность (entity), с определенным набором свойств - атрибутов, способных принимать определенные значения (набор допустимых значений - домен).
Ключевой элемент таблицы (ключ, regular key) - такое ее поле ( простой ключ) или строковое выражение, образованное из значений нескольких полей (составной ключ), по которому можно определить значения других полей для одной или нескольких записей таблицы. На практике для использования ключей создаются индексы - служебная информация, содержащая упорядоченные сведения о ключевых значениях. В реляционной теории и концептуальной модели понятие "ключ" применяется для атрибутов отношения или сущности.
Первичный ключ (primary key) - главный ключевой элемент, однозначно идентифицирующий строку в таблице. Могут также существовать альтернативный (candidate key) и уникальный (unique key) ключи, служащие также для идентификации строк в таблице.
В реляционной теории первичный ключ - минимальный набор атрибутов, однозначно идентифицирующий кортеж в отношении.
В концептуальной модели первичный ключ - минимальный набор атрибутов сущности, однозначно идентифицирующий экземпляр сущности.
Связь (relation) - функциональная зависимость между объектами. В реляционных базах данных между таблицами устанавливаются связи по ключам, один из которых в главной (parent, родительской) таблице - первичный, второй - внешний ключ - во внешней (child, дочерней) таблице, как правило, первичным не является и образует связь "один ко многим" (1:N). В случае первичного внешнего ключа связь между таблицами имеет тип "один к одному" (1:1). Информация о связях сохраняется в базе данных.
Внешний ключ (foreign key) - ключевой элемент подчиненной (внешней, дочерней) таблицы, значение которого совпадает со значением первичного ключа главной (родительской) таблицы.
Ссылочная целостность данных (referential integrity) - набор правил, обеспечивающих соответствие ключевых значений в связанных таблицах.
Хранимые процедуры (stored procedures) - программные модули, сохраняемые в базе данных для выполнения определенных операций с информацией базы.
Триггеры (triggers) - хранимые процедуры, обеспечивающие соблюдение условий ссылочной целостности данных в операциях изменения первичных ключей (возможно каскадное изменение данных), удалении записей в главной таблице (каскадное удаление в дочерних таблицах) и добавлении записей или изменении данных в дочерних таблицах.
Объект (object) - элемент информационной системы, обладающий определенными свойствами (properties) и определенным образом реагирующий на внешние события (events).
Система - совокупность взаимодействующих между собой и с внешним окружением объектов.
Репликация базы данных - создание копий базы данных (реплик), которые могут обмениваться обновляемыми данными или реплицированными формами, отчетами или другими объектами в результате выполнения процесса синхронизации.
Транзакция - изменение информации в базе в результате выполнения одной операции или их последовательности, которое должно быть выполнено полностью или не выполнено вообще. В СУБД существуют специальные механизмы обеспечения транзакций.
Язык SQL (Structured Query Language) - универсальный язык работы с базами данных, включающий возможности ее создания, модификации структуры, отбора данных по запросам, модификации информации в базе и прочие операции манипулирования базой данных.
Null - значение поля таблицы, показывающее, что информация в данном поле отсутствует. Разрешение на возможность существования значения Null может задаваться для отдельных полей таблицы.
Принципы проектирования информационных систем
Информационная система (ИС) - программно-аппаратный комплекс, предназначенный для хранения и обработки информации какой-либо предметной области. База данных - важнейший компонент любой информационной системы. Хорошо структурированная информация в базе данных позволяет не только беспроблемно эксплуатировать систему и выполнять ее текущее обслуживание, но и модифицировать и развивать ее при модернизации предприятия и изменении информационных потоков, законодательства и форм отчетности.
В настоящее время в эксплуатации на крупных предприятиях находятся комплексные ИС управления предприятиями (КИС, корпоративные системы, ERP-системы), такие как R/3 фирмы SAP, Oracle E-Business Suite, BaanERP. Среди российских разработок приближаются по функциональности к системам класса ERP "Галактика", "Флагман", "Парус".
По данным аналитической компании IDC за 2004 г., объем российского рынка интегрированных систем управления предприятием (ИСУП) вырос на 52,8% и достиг 195 млн. долл. Уже третий год подряд темпы его роста превышают аналогичный показатель ИТ отрасли в целом (1.1).
Таблица 1.1. Объем российского рынка интегрированных систем управления предприятием в 2004 г.
Название компанииДоля (%)| SAP | 40,6 |
| Oracle | 22,8 |
| Microsoft | 10,9 |
| Galaktika | 8,2 |
| 1C | 4,6 |
| Epicor-Scala | 3,7 |
| BAAN | 2,4 |
| Остальное | 6,8 |
| ВСЕГО | 195,15 млн. долл. |
Многие ERP-системы могут устанавливаться и функционировать на различных операционных системах и серверах баз данных (многоплатформенные системы). База данных подобных систем состоит из нескольких тысяч таблиц (BaanERP 5.0с - более 2500 таблиц информации по одному предприятию).
Любая сложная система для обеспечения ее надежного функционирования строится как иерархическая система, состоящая из отдельных подсистем и модулей, которые взаимодействуют между собой и используют общую базу данных.
На рис. 1.2 показан полный состав системы BaanERP версии 5.0с (меню администратора системы) и состав модулей подсистемы "Производство".
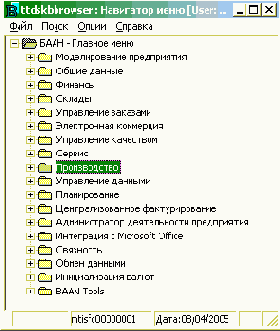

Рис. 1.2. Подсистемы и модули BaanERP 5.0c
На рис. 1.3 приведена схема подсистем и модулей КИС "Флагман".
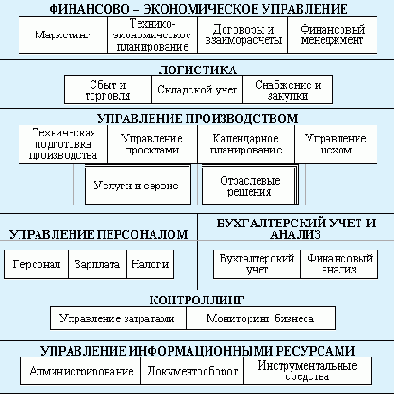
Рис. 1.3. Схема подсистем и модулей КИС "Флагман"
Понимание принципов разработки, организации и функционирования подобных систем, способов хранения и обработки информации необходимо каждому современному специалисту.
При описании информационной системы предполагается, что она содержит два типа сущностей: операционные сущности, которые выполняют какую-либо обработку (некоторый аналог программы), и пассивные сущности, которые хранят информацию, доступную для пополнения, изменения, поиска, чтения (база данных).
При проектировании сложных информационных систем используется метод декомпозиции - система разбивается на составные части, которые связаны, взаимодействуют друг с другом и образуют иерархическую структуру. Иерархический характер сложных систем хорошо согласуется с принципом групповой разработки. В этом случае деятельность каждого участника проекта ограничивается соответствующим иерархическим уровнем.
Классический подход к разработке сложных систем представляет собой структурное проектирование, при котором осуществляется алгоритмическая декомпозиция системы по методу "сверху вниз". Именно в этом случае можно построить хорошо функционирующую систему с общей базой данных, согласованными форматами использования и обработки информации на всех участках, с оптимальным взаимодействием всех подсистем.
Исторически сложилось так, что некоторые системы разрабатывались по методу "снизу вверх": вначале создавались отдельные автоматизированные рабочие места (АРМы), затем предпринимались попытки объединения их в единую информационную систему. Подобные разработки для крупных систем не могут быть успешны.
При создании проекта информационной системы для проектирования ее базы данных следует определить:
- объекты информационной системы (сущности в концептуальной модели);их свойства (атрибуты);взаимодействие объектов (связи) и информационные потоки внутри и между ними.
При этом очень важен анализ существующей практики реализации информационных процессов и нормативной информации (законов, постановлений правительства, отраслевых стандартов), определяющих необходимый объем и формат хранения и передачи информации. Если радикальной перестройки сложившегося информационного процесса не предвидится, следует учитывать имеющиеся формы хранения и обработки информации в виде журналов, ведомостей, таблиц и т.п. бумажных носителей.
Однако предварительно необходимо выполнить анализ возможности перехода на новые системы учета, хранения и обработки информации, возможно, исходя из имеющихся на рынке программных продуктов-аналогов, разработанных крупными информационными компаниями и частично или полностью соответствующими поставленной задаче.
Схема формирования информационной модели представлена на рис.1.4.
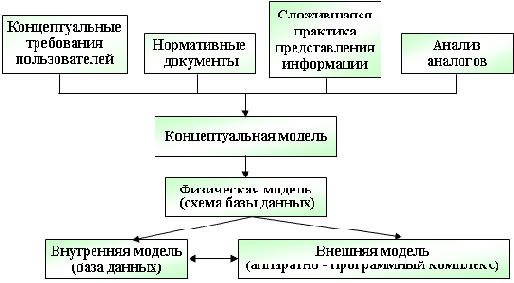
Рис. 1.4. Схема формирования информационной модели
Концептуальная модель (см. рис.1.4) - отображает информационные объекты, их свойства и связи между ними без указания способов физического хранения информации (модель предметной области, иногда ее также называют информационно-логической или инфологической моделью). Информационными объектами обычно являются сущности - обособленные объекты или события, информацию о которых необходимо сохранять, имеющие определенные наборы свойств - атрибутов.
Физическая модель - отражает все свойства (атрибуты) информационных объектов базы и связи между ними с учетом способа их хранения - используемой СУБД.
Внутренняя модель - база данных, соответствующая определенной физической модели.
Внешняя модель - комплекс программных и аппаратных средств для работы с базой данных, обеспечивающий процессы создания, хранения, редактирования, удаления и поиска информации, а также решающий задачи выполнения необходимых расчетов и создания выходных печатных форм.
Создание информационной системы ведется в несколько этапов, на каждом из которых конкретизируются и уточняются элементы разрабатываемой системы.
Существуют различные типы схем, иллюстрирующих жизненный цикл разработки ИС.На рис.1.5 показана каскадная схема с обратной связью.
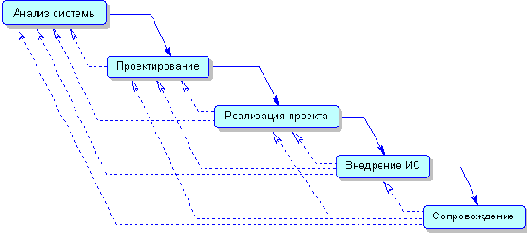
Рис. 1.5. Каскадная схема жизненного цикла ИС
Правил Кодда
- Реляционная СУБД должна быть способна полностью управлять базой данных через ее реляционные возможности.Информационное правило - вся информация в реляционной БД (включая имена таблиц и столбцов) должна определяться строго как значения в таблицах.Гарантированный доступ - любое значение в реляционной БД должно быть гарантированно доступно для использования через комбинацию имени таблицы, значения первичного ключа и имени столбцаПоддержка пустых значений (null value) - СУБД должна уметь работать с пустыми значениями (неизвестными или неиспользованными значениями), в отличие от значений по умолчанию и независимо для любых доменов.Онлайновый реляционный каталог - описание БД и ее содержания должны быть представлены на логическом уровне как таблицы, к которым можно применять запросы, используя язык базы данных.Исчерпывающий язык управления данными - по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть всеобъемлющим. Он должен поддерживать описание структуры данных и манипулирование ими, правила целостности, авторизацию и транзакции.Правило обновления представлений (views) - все представления, теоретически обновляемые, могут быть обновлены через систему.Вставка, обновление и удаление - СУБД поддерживает не только запрос на отбор данных, но и вставку, обновление и удалениеФизическая независимость данных - на программы-приложения и специальные программы логически не влияют изменения физических методов доступа к данным и структур хранилищ данных.Логическая независимость данных - на программы-приложения и специальные программы логически не влияют, в пределах разумного, изменения структур таблиц.Независимость целостности - язык БД должен быть способен определять правила целостности. Они должны сохраняться в онлайновом справочнике, и не должно существовать способа их обойти.Независимость распределения - на программы-приложения и специальные программы логически не влияет, первый раз используются данные или повторно.Неподрывность - невозможность обойти правила целостности, определенные через язык базы данных, использованием языков низкого уровня
Кодд предложил применение реляционной алгебры в СУРБД, для расчленения данных в связанные наборы. Он организовал свою систему БД вокруг концепции, основанной на наборах данных.
В реляционной модели данные разбиваются на наборы, которые составляют табличную структуру. Эта структура таблиц состоит из индивидуальных элементов данных, называемых полями. Одиночный набор или группа полей известна как запись.
Модель данных, или концептуальное описание предметной области - самый абстрактный уровень проектирования баз данных.
С точки зрения теории реляционных БД, основные принципы реляционной модели на концептуальном уровне можно сформулировать следующим образом:
все данные представляются в виде упорядоченной структуры, определенной в виде строк и столбцов и называемой отношением;все значения являются скалярами. Это означает, что для любой строки и столбца любого отношения существует одно и только одно значение;все операции выполняются над целым отношением, и результатом их выполнения также является целое отношение. Этот принцип называется замыканием
Формулируя принципы реляционной модели, доктор Кодд выбрал термин "отношение" (relation), потому что, по его мнению, этот термин однозначен (в то время как, например, термин "таблица" имеет множество различных видов - таблица в тексте, электронная таблица и пр.). Весьма распространено следующее заблуждение: реляционная модель названа так потому, что она определяет связи между таблицами. На самом деле, название этой модели происходит от отношений (таблиц базы данных), лежащих в ее основе.
Каждая строка, содержащая данные, называется кортежем, каждый столбец отношения называется атрибутом (на уровне практической работы с современными реляционными БД используются термины "запись" и "поле").
Элементами описания реляционной модели данных на концептуальном уровне являются сущности, атрибуты, домены и связи
Сущность - некоторый обособленный объект или событие, информацию о котором необходимо сохранять в базе данных, имеющий определенный набор свойств - атрибутов.
Сущности могут быть как физические (реально существующие объекты: например, СТУДЕНТ, атрибуты - № зачетной книжки, фамилия, его факультет, специальность, № группы и т.д.), так и абстрактные (например, ЭКЗАМЕН, атрибуты - дисциплина, дата, преподаватель, аудитория и пр.). Для сущностей различают ее тип и экземпляр. Тип характеризуется именем и списком свойств, а экземпляр - конкретными значениями свойств.
Атрибуты сущности бывают:
- Идентифицирующие и описательные. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа и являются потенциальными ключами. Они позволяют однозначно распознавать экземпляры сущности. Из потенциальных ключей выбирается один первичный ключ (ПК). В качестве ПК обычно выбирается потенциальный ключ, по которому чаще происходит обращение к экземплярам записи. ПК должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Остальные атрибуты называются описательными.Простые и составные. Простой атрибут состоит из одного компонента, его значение неделимо. Составной атрибут является комбинацией нескольких компонентов, возможно, принадлежащих разным типам данных (например, адрес). Решение о том, использовать составной атрибут или разбивать его на компоненты, зависит от особенностей процессов его использования и может быть связано с обеспечением высокой скорости работы с большими базами данных.Однозначные и многозначные - могут иметь соответственно одно или много значений для каждого экземпляра сущности.Основные и производные. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов (например, возраст человека вычисляется на основе даты его рождения и текущей даты
Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности - множества значений (или домена), которые может принимать данный атрибут.
Домен - это набор всех допустимых значений, которые может содержать атрибут.
Понятие "домен" часто путают с понятием "тип данных". Необходимо различать эти два понятия. Тип данных - это физическая концепция, а домен - логическая. Например, "целое число" - это тип данных, а "возраст" - это домен.
Связи - на концептуальном уровне представляют собой простые ассоциации между сущностями. Например, утверждение "Покупатели приобретают продукты" указывает, что между сущностями "Покупатели" и "Продукты" существует связь, и такие сущности называются участниками этой связи.
Существует несколько типов связей между двумя сущностями: это связи "один к одному", "один ко многим" и "многие ко многим".
Каждая связь в реляционной модели характеризуется именем, обязательностью, типом и степенью. Различают факультативные и обязательные связи. Если сущность одного типа оказывается по необходимости связанной с сущностью другого типа, то между этими типами объектов существует обязательная связь (обозначается двойной линией). Иначе связь является факультативной.
Степень связи определяется количеством сущностей, которые охвачены данной связью. Пример бинарной связи - связь между отделом и сотрудниками, которые в нем работают.
Диаграмма "сущности-связи" (Entity-Relationship diagrams, или E/R diagram) служит для описания схемы базы на концептуальном уровне проектирования. Метод был предложен в 1976 г. Питером Пин Шань Ченом (Peter Pin Shan Chen) [2]. На диаграммах "сущности-связи" сущности изображаются в виде прямоугольников, атрибуты - в виде эллипсов, а связи - в виде ромбов (см. рис. 2.6).
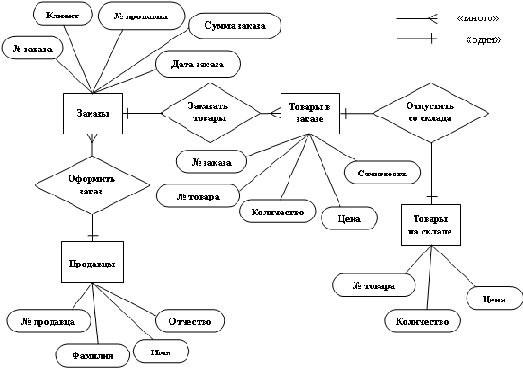
Рис. 2.6. Диаграмма "сущности-связи"
В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.). Кроме того, различные программные средства, реализующие одну и ту же нотацию, могут отличаться своими возможностями. По сути, все варианты диаграмм "сущность-связь" исходят из одной идеи - рисунок всегда нагляднее текстового описания.
Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
Проектирование схемы БД должно решать задачи минимизации дублирования данных, упрощения и ускорения процедур их обработки и обновления. При неправильно спроектированной схеме БД могут возникнуть аномалии модификации данных. Для решения подобных проблем проводится нормализация отношений
Однако в технологии работы с хранилищами данных может использоваться обратный прием - денормализация отношений с целью увеличения скорости выполнения запросов к очень большим объемам архивных данных.
В рамках реляционной модели данных Э.Ф. Коддом были разработаны принципы нормализации отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей нормальной форме.
Нормализация - это формальный метод анализа отношений на основе их первичного ключа и существующих связей. Ее задача - это замена одной схемы (или совокупности отношений) БД другой схемой, в которой отношения имеют более простую и регулярную структуру.
При работе с реляционной моделью для создания отношений приемлемого качества достаточно выполнения требований первой нормальной формы.
Первая нормальная форма (1НФ) связана с понятиями простого и сложного атрибутов. Простой атрибут - это атрибут, значения которого атомарны (т.е. неделимы). Сложный атрибут может иметь значение, представляющее собой объединение нескольких значений одного или разных доменов. В первой нормальной форме устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, "замаскированных" под атрибуты.
Отношение приведено к 1НФ, если все его атрибуты - простые, т.е. значение атрибута не должно быть множеством или повторяющейся группой.
Для приведения таблиц к 1НФ необходимо разбить сложные атрибуты на простые, а многозначные атрибуты вынести в отдельные отношения.
Вторая нормальная форма (2НФ) применяется к отношениям с составными ключами (состоящими из двух и более атрибутов) и связана с понятиями функциональной зависимости.
Если в любой момент времени каждому значению атрибута A соответствует единственное значение атрибута B, то B функционально зависит от A (A

Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального ключа. Эта часть уникального ключа определяет отдельную сущность.
Отношение находится во 2НФ, если оно приведено к 1НФ и каждый неключевой атрибут функционально полно зависит от составного первичного ключа.
Третья нормальная форма (3НФ) связана с понятием транзитивной зависимости. Пусть A, B, C - атрибуты некоторого отношения. При этом A
В третьей нормальной форме устраняются атрибуты, которые зависят от атрибутов, не входящих в уникальный ключ. Эти атрибуты являются основой отдельной сущности.
Отношение находится в 3НФ, если оно находится во 2НФ и не имеет атрибутов, не входящих в первичный ключ и находящихся в транзитивной зависимости от первичного ключа.
Существуют также нормальная форма Бойса-Кодда (НФБК), 4НФ и 5НФ. Однако наибольшее значение имеет 1НФ, т.к. последующие НФ связаны с понятиями о составных ключах и сложных зависимостях от ключей, а на практике встречаются обычно более простые случаи.
Моделирование структуры базы данных при помощи алгоритма нормализации имеет серьезные недостатки:
- Методика нормализации предполагает первоначальное размещение всех атрибутов проектируемой предметной области в одном отношении, что является очень неестественной операцией. Интуитивно разработчик сразу проектирует несколько отношений в соответствии с обнаруженными сущностями. Даже если совершить насилие над собой и создать одно или несколько отношений, включив в них все предполагаемые атрибуты, то совершенно неясен смысл полученного отношения.Невозможно сразу определить полный список атрибутов. Пользователи имеют привычку называть разными именами одни и те же вещи или наоборот, называть одними именами разные вещи.Для проведения процедуры нормализации необходимо выделить зависимости атрибутов, что тоже очень нелегко.
В реальном проектировании структуры базы данных применяются другой метод - так называемое семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опирающееся на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм "сущность-связь (ERD)" c построением концептуальной модели базы данных.
Любой специалист, освоивший общие принципы оптимальной организации реляционных баз данных, в состоянии построить модель, не противоречащую принципам нормализации.
Реляционная БД на физическом уровне состоит из таблиц, между которыми могут существовать связи по ключевым значениям. Одновременно с таблицами и информацией о связях в реляционной базе данных могут присутствовать "хранимые процедуры" и, в частности, "триггеры", обеспечивающие соблюдение условий ссылочной целостности базы.
Дополнительные стратегии поддержания ссылочной целостности
IGNORE (ИГНОРИРОВАТЬ) - разрешить выполнять операцию без проверки ссылочной целостности. В этом случае в дочерней таблице могут появляться некорректные значения внешних ключей, вся ответственность за целостность базы данных ложится на программиста или пользователя.
SET NULL (ЗАДАТЬ ЗНАЧЕНИЕ NULL) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на null-значения. Эта стратегия имеет два недостатка. Во-первых, для нее требуется разрешение на использование null-значений. Во-вторых, записи дочерней таблицы теряют связь с записями родительской таблицы. Установить, с какой записью родительской таблицы были связаны измененные записи дочерней таблицы, после выполнения операции уже нельзя.
SET DEFAULT (ЗАДАТЬ ЗНАЧЕНИЕ ПО УМОЛЧАНИЮ) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию. Достоинство этой стратегии по сравнению с предыдущей в том, что она позволяет не пользоваться null-значениями. Установить, с какими записями родительской таблицы были связаны измененные записи дочерней таблицы, после выполнения такой операции тоже нельзя.
На рис. 2.7 представлен пример реляционной базы, содержащей сведения отдела кадров по работникам предприятия, в которой для каждой таблицы базы показан список ее полей и показаны связи между таблицами по простому ключу - значению поля tabn.
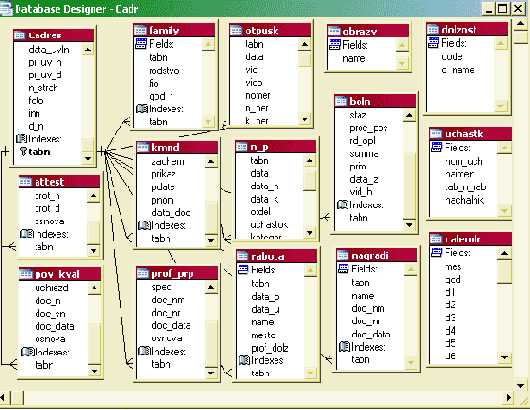
Рис. 2.7. Схема реляционной базы данных
Начиная с 1980-х годов, одновременно с широким распространением персональных компьютеров, большое распространение получили так называемые "настольные" реляционные СУБД (Desktop Databases), такие как dBase, FoхBase (его более поздние версии - FoхPro и Visual FoхPro), Paradoх, Access. Наиболее распространенным форматом таблиц подобных реляционных баз стал *.dbf, с которым работали dBase, FoхBase, а также Clipper - система написания программ (в режиме строкового компилятора) для работы с базами данных.
В последующем некоторые из них стали полноценными сетевыми СУБД, работающими не только в различных операционных системах в архитектуре "файл-сервер", но и имеющими возможности для работы с серверами баз данных в архитектуре "клиент-сервер", а также разработки и использования html-страниц для работы с базами данных.
Все СУБД для ПК можно подразделить на 3 вида:
- Системы управления базами данных в буквальном смысле этого термина, для которых работа с базами возможна только после запуска в работу этой системы без возможности создания автономных программ, работающих с базами. К этим системам относятся: Access, Paradoх, dBase.Системы, имеющие как средства для работы с базами данных, так и возможности разработки исполняемых в операционной системе пользовательских программ (приложений), т. е. средства разработчика программ - FoхPro.Системы для разработки пользовательских программ для работы с базами данных - Clipper, Clarion.
Все подобные СУБД имеют в своем составе средства для:
создания баз данных и модификации их структуры; создания индексных файлов;работы с базами в табличном формате или в виде стандартной формы с расположением полей построчно; при этом возможно редактирование данных, добавление записей, удаление записей, работа с данными из нескольких таблиц базы, вычисление сложных выражений для заданных условий и пр.;разработки экранных форм, имеющих, кроме редактируемых полей, связанных с базой данных или с переменными памяти, также элементы управления разного вида в виде кнопок; более сложные объекты типа раскрывающихся списков и пр.;генерации печатных форм - отчетов сложной структуры с группировкой данных, с получением расчетных значений и итогов по группам и общих итогов (сумма, количество, среднее, максимальное, минимальное, и пр.);разработки программных модулей для сложной обработки данных;генерации запросов очень сложной структуры - с использованием данных из различных баз, заданием сложных условий отбора данных, сортировки и группировки данных;в системах, ориентированных на разработчика, дополнительно возможны разработка меню, справочной системы и проекта, включающего все перечисленные выше компоненты и компилирующегося в исполняемую программу.
Важными факторами, определяющими выбор СУБД, являются:
- Формат базы данных, обеспечивающий возможность обмена информацией с другими приложениями операционной системы. Одним из самых распространенных форматов является dbf-формат, с которым работают dBase, FoхBase, FoхPro, Visual FoхPro, Clipper. Его "понимают" все приложения MS Office. Данные из этих баз можно переносить в Word, Eхcel, Access. Свои собственные форматы данных имеют Clarion, Paradoх, Access.Обеспечение секретности и конфиденциальности данных - имеют системы, не ориентированные на разработчика программ: Access, Paradoх. Однако этот фактор может быть реализован при хранении данных на выделенном сервере, где права различных пользователей легко разграничить.
Все современные СУБД поддерживают режимы работы в локальной сети многих пользователей с одной базой данных. Некоторые имеют "мастеров", "построителей" и "генераторы выражений" для ускоренной разработки баз данных, экранных форм, отчетов, стандартных приложений.
Последние версии СУБД, разработанные для работы в OC Windows 95, относятся к классу RAD-систем (Rapid Application Development) - средства быстрой разработки приложений - и имеют объектно-ориентированный язык программирования. Это такие системы, как Visual FoхPro, MS Access, Visual dBase и другие.
Иерархические базы данных
В основе данной модели - иерархическая модель данных. В этой модели имеется один главный объект и остальные - подчиненные - объекты, находящиеся на разных уровнях иерархии. Взаимосвязи объектов образуют иерархическое дерево с одним корневым объектом.
Иерархическая БД состоит из упорядоченного набора нескольких экземпляров одного типа дерева. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя (см. рис. 2.4).
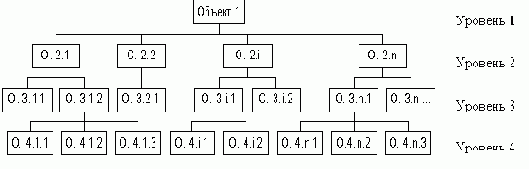
Рис. 2.4. Схема иерархической модели данных
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных этой системы.
Классификация баз данных
По технологии обработки данных базы данных подразделяются на централизованные и распределенные.
Централизованная база данных хранится в памяти одной вычислительной системы. Эта вычислительная система может быть мэйнфреймом - тогда доступ к ней организуется с использованием терминалов - или файловым сервером локальной сети ПК.
Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, которые хранятся в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с сетевым доступом.
Для всех современных баз данных можно организовать сетевой доступ с многопользовательским режимом работы.
Централизованные базы данных с сетевым доступом могут иметь следующую архитектуру:
файл-сервер;клиент-сервер базы данных;"тонкий клиент" - сервер приложений - сервер базы данных (трехуровневая архитектура).

Рис. 2.1. Схема работы с БД в локальной сети с выделенным файловым сервером
Файл-сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (файловый сервер). На этот компьютер устанавливается операционная система (ОС) для выделенного сервера (например, Microsoft Windows Server 2003). На нем же хранится совместно используемая централизованная БД в виде одного или группы файлов. Все другие компьютеры сети выполняют функции рабочих станций (могут работать в ОС Microsoft Windows 2000 Professional или Microsoft Windows 98). Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где и производится обработка информации (см. рис. 2.1). При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также локальные БД на рабочих станциях.

Рис. 2.2. Схема работы с БД в архитектуре "Клиент-сервер"
Клиент-сервер. В этой архитектуре на выделенном сервере, работающем под управлением серверной операционной системы, устанавливается специальное программное обеспечение (ПО) - сервер БД, например, Microsoft®SQL Server™или Oracle. СУБД подразделяется на две части: клиентскую и серверную. Основа работы сервера БД - использование языка запросов (SQL). Запрос на языке SQL, передаваемый клиентом (рабочей станцией) серверу БД, порождает поиск и извлечение данных на сервере. Извлеченные данные транспортируются по сети от сервера к клиенту (см. рис. 2.2). Тем самым, количество передаваемой по сети информации уменьшается во много раз.
Трехуровневая архитектура функционирует в Интранет- и Интернет-сетях. Клиентская часть ("тонкий клиент"), взаимодействующая с пользователем, представляет собой HTML-страницу в Web-браузере либо Windows-приложение, взаимодействующее с Web-сервисами. Вся программная логика вынесена на сервер приложений, который обеспечивает формирование запросов к базе данных, передаваемых на выполнение серверу баз данных. Сервер приложений может быть Web-сервером или специализированной программой (например, Oracle Forms Server) (см. рис. 2.3).

Рис. 2.3. Схема работы с БД в трехуровневой архитектуре
Основные стратегии поддержания ссылочной целостности
Существуют две основные стратегии поддержания ссылочной целостности.
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
CASCADE (КАСКАДНОЕ ИЗМЕНЕНИЕ) - разрешить выполнение требуемой операции, но внести при этом необходимые изменения в связанных таблицах так, чтобы не допустить нарушения ссылочной целостности и сохранить все имеющиеся связи. Изменение начинается в родительской таблице и каскадно выполняется в дочерних таблицах. В реализации этой стратегии имеется одна тонкость, заключающаяся в том, что дочерние таблицы сами могут быть родительскими для некоторых третьих таблиц. При этом может дополнительно потребоваться выполнение какой-либо стратегии и для этой связи и т.д. Если при этом какая-либо из каскадных операций (любого уровня) не может быть выполнена, то необходимо отказаться от первоначальной операции и вернуть базу данных в исходное состояние. Это сложная стратегия, но она не нарушает связей между родительскими и дочерними таблицами.
Эти стратегии являются стандартными и присутствуют во всех СУБД, в которых имеется поддержка ссылочной целостности.
Постреляционные базы данных
В настоящее время известны также так называемые "постреляционные" СУБД, в основе которых лежат модель данных в виде многомерных таблиц (например в системе Cache фирмы InterSystems Сorporation) и широкое использование принципов объектно-ориентированного подхода при организации баз данных и программировании.
Распределенные базы данных
Основная задача систем управления распределенными базами данных состоит в обеспечении средства интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе.
Возможны однородные и неоднородные распределенные базы данных. В однородном случае каждая локальная база данных управляется одной и той же СУБД. В неоднородной системе локальные базы данных могут относиться даже к разным моделям данных. Сетевая интеграция неоднородных баз данных - очень сложная проблема. Многие решения известны на теоретическом уровне, но пока не удается справиться с главной проблемой: недостаточной эффективностью интегрированных систем. Более успешно решается промежуточная задача - интеграция неоднородных SQL-ориентированных систем. Этому в большой степени способствует стандартизация языка SQL.
Примером распределенной СУБД может служить System R*. В данной системе разработчики прикладных программ и конечные пользователи остаются в среде языка SQL. Возможность использования SQL основывается на обеспечении System R* прозрачности местоположения данных. Система автоматически обнаруживает текущее местоположение упоминаемых в запросе пользователя объектов данных; одна и та же прикладная программа, включающая предложения SQL, может быть выполнена в разных узлах сети. При этом в каждом узле сети на этапе компиляции запроса выбирается наиболее оптимальный план выполнения запроса в соответствии с расположением данных в распределенной системе.
Реляционные системы
Реляционные системы далеко не сразу получили широкое распространение. В то время как основные теоретические результаты в этой области были получены еще в 70-х годах и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД.
Реляционная модель данных основывается на математических принципах, вытекающих непосредственно из теории множеств и логики предикатов. Эти принципы впервые были применены в области моделирования данных в конце 1960-х гг. доктором Е.Ф. Коддом, в то время работавшим в IBM, а впервые опубликованы - в 1970 г. [1].
Техническая статья "Реляционная модель данных для больших разделяемых банков данных" доктора Е.Ф. Кодда, опубликованная в 1970 г., является родоначальницей современной теории реляционных БД. Доктор Кодд определил 13 правил реляционной модели (которые называют 12 правилами Кодда).
Серверы баз данных
В локальных и глобальных компьютерных сетях широко применяются серверы: компьютеры и программные средства для обслуживания клиентов - рабочих станций и/или других серверов.
Примерами серверов могут быть:
файловый сервер, поддерживающий общее хранилище файлов для всех рабочих станций;интернет-сервер, обеспечивающий предоставление информации в глобальной сети Интернет;почтовый сервер, обеспечивающий работу с электронной почтой;сервер баз данных - СУБД, которая принимает запросы по локальной сети и возвращает информацию, соответствующую запросу.
Термин "сервер баз данных" обычно используют для обозначения всей СУБД, основанной на архитектуре "клиент-сервер", включая и серверную, и клиентскую части. Наиболее распространенными серверами являются в настоящее время Microsoft SQL Server, Oracle, IBM DB2 Universal DataBase, Informix и др. Размер одной базы данных на этих серверах может достигать миллиона терабайт.
Сетевые базы данных
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
В сетевой модели данных любой объект может быть одновременно и главным, и подчиненным, и может участвовать в образовании любого числа взаимосвязей с другими объектами. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно - из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи (см. рис. 2.5).
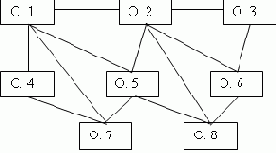
Рис. 2.5. Схема сетевой модели
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages (CODASYL) - организации, ответственной за определение языка программирования Кобол. Отчет DBTG был опубликован в 1971 г., а позже появилось несколько систем, среди которых IDMS.
Соблюдение условий ссылочной целостности в реляционной базе данных
Правило соответствия внешних ключей первичным - основное правило соблюдения условий ссылочной целостности. Для каждого значения внешнего ключа должно существовать соответствующее значение первичного ключа в родительской таблице
Ссылочная целостность может нарушиться в результате операций вставки (добавления), обновления и удаления записей в таблицах. В определении ссылочной целостности участвуют две таблицы - родительская и дочерняя, для каждой из них возможны эти операции, поэтому существует шесть различных вариантов, которые могут привести либо не привести к нарушению ссылочной целостности.
Для родительской таблицы:
Вставка. Возникает новое значение первичного ключа. Существование записей в родительской таблице, на которые нет ссылок из дочерней таблицы, допустимо, операция не нарушает ссылочной целостности.Обновление. Изменение значения первичного ключа в записи может привести к нарушению ссылочной целостности.Удаление. При удалении записи удаляется значение первичного ключа. Если есть записи в дочерней таблице, ссылающиеся на ключ удаляемой записи, то значения внешних ключей станут некорректными. Операция может привести к нарушению ссылочной целостности.
Для дочерней таблицы:
Вставка. Нельзя вставить запись в дочернюю таблицу, если для новой записи значение внешнего ключа некорректно. Операция может привести к нарушению ссылочной целостности.Обновление. При обновлении записи в дочерней таблице можно попытаться некорректно изменить значение внешнего ключа. Операция может привести к нарушению ссылочной целостности.Удаление. При удалении записи в дочерней таблице ссылочная целостность не нарушается.
Таким образом, ссылочная целостность в принципе может быть нарушена при выполнении одной из четырех операций:
- Обновление записей в родительской таблице.Удаление записей в родительской таблице.Вставка записей в дочерней таблице.Обновление записей в дочерней таблице.
Использование методологии IDEF1X для разработки концептуальной модели данных
Важнейшая цель проектирования информационной модели - выработка непротиворечивой структурированной интерпретации реально существующей информации изучаемой предметной области и взаимодействия между ее структурными компонентами
Понятие концептуальной модели данных связано с методологией семантического моделирования данных, т.е. с представлением данных в контексте их взаимосвязей с другими данными.
Методология IDEF1X - один из подходов к семантическому моделированию данных, основанный на концепции "сущность-связь" (Entity-Relationship). Это инструмент для анализа информационной структуры систем различной природы. Информационная модель, построенная с помощью IDEF1X-методологии, отображает логическую структуру информации об объектах системы
Таким образом, концептуальная модель, представленная в соответствии со стандартом IDEF1X, является логической схемой базы данных для проектируемой системы
Основными объектами концептуальной модели являются сущности и связи.
Сущность - некоторый обособленный объект или событие моделируемой системы, имеющий определенный набор свойств - атрибутов. Отдельный элемент этого множества называется "экземпляром сущности". Сущность может обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый образец сущности, и может обладать любым количеством связей с другими сущностями.
Правила для атрибутов сущности:
- Каждый атрибут должен иметь уникальное имя.Сущность может обладать любым количеством атрибутов.Сущность может обладать любым количеством наследуемых атрибутов, но наследуемый атрибут должен быть частью первичного ключа сущности-родителя.Для каждого экземпляра сущности должно существовать значение каждого его атрибута (правило необращения в нуль - Not Null).Ни один из экземпляров сущности не может обладать более чем одним значением для ее атрибута.
Сущность изображается на ER-диаграмме в виде прямоугольника, в верхней части которого приводится ее название; далее следует список атрибутов. Ключевые атрибуты могут быть выделены подчеркиванием или иным способом.
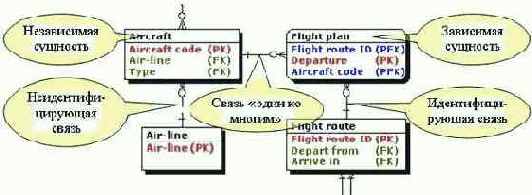
Стандарт IDEF1X описывает способы изображения двух типов сущностей - независимой и зависимой, и связей - идентифицирующих и неидентифицирующих (см. рис. 3.1).
увеличить изображение
Рис. 3.1. Изображение сущностей и связей по стандарту IDEF1X
Каждая сущность может обладать любым количеством связей с другими сущностями.
Сущность является независимой, если каждый ее экземпляр может быть однозначно идентифицирован без определения его связей с другими сущностями.
Сущность называется зависимой, если однозначная идентификация ее экземпляра зависит от его связей с другими сущностями.
Сущность может обладать атрибутами, которые наследуются через связь с родительской сущностью. Последние обычно являются внешними ключами (FK на рис. 3.1) и служат для организации связей между сущностями. Если внешний ключ сущности используется в качестве ее первичного ключа (PK) или как часть составного первичного ключа, то сущность является зависимой от родительской сущности. Если внешний ключ не является первичным и не входит в составной первичный ключ, то сущность является независимой от родительской сущности.
Если сущность является зависимой, то связь ее с родительской сущностью называется идентифицирующей, в противном случае - неидентифицирующей.
Связь изображается на ER-диаграмме линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. идентифицирующая связь изображается сплошной линией, неидентифицирующая - пунктирной.
Связи дается имя, выражаемое грамматической формой глагола. Для связи дополнительно может присутствовать указание мощности: какое количество экземпляров сущности-потомка может существовать для сущности-родителя. Имя связи всегда формируется с точки зрения родителя, так что может быть образовано предложение, если соединить имя сущности родителя, имя связи, выражение мощности и имя сущности-потомка (например "много СТУДЕНТов - сдают - ЭКЗАМЕН").
Принципы изображения концептуальных моделей баз данных стандарта IDEF1 и IDEF1X используют CASE Studio и другие CASE-средства.Подобные системы позволяют на основе концептуальной модели генерировать физическую модель и программный код создания базы данных для большинства наиболее распространенных СУБД и серверов баз данных.
В рассматриваемом далее примере концептуальной модели (см. рис. рис. 3.5) все сущности - независимые и связи между ними - неидентифицирующие, хотя возможны и другие варианты ключей и связей.
Использование системы CASE Studio для проектирования концептуальной и физической моделей базы данных
CASE Studio является профессиональным инструментом проектирования баз данных. Система предназначена для визуального создания и модификации диаграмм "сущность-связь" (ERD) и диаграмм потоков данных (DFD). Уровень представления ER-диаграмм может быть различен: от простейшего вида (имена сущностей и связи между ними) и до полной физической модели для выбранной СУБД. Сложные модели данных могут быть разбиты на отдельные логические фрагменты - субмодели.
Для разработанных диаграмм далее может быть сгенерирован программный код для создания таблиц, индексов, связей, хранимых процедур, пользователей и других компонентов различных СУБД (см. табл. 3.7.). Кроме того, предусмотрена возможность генерации ER-диаграмм для существующей базы данных (Reverse Engineering) с использованием для связи с БД прямого соединения, ODBC или ADO-драйверов.
При создании новой модели данных следует задать, для какой СУБД она проектируется, т.к. CASE Studio имеет возможность построения полной физической модели базы данных с использованием индивидуальных свойств каждой БД - типы и свойства атрибутов (стандартные БД и пользователя), возможности описания ключей (первичные и внешние), связей, условий соблюдения ссылочной целостности, пользователей и их групп (ролей); возможности написания хранимых процедур и пр. В последующем можно будет выполнить конверсию физической модели для другой СУБД (меню Model - Database Convertion) с сохранением в виде копии.
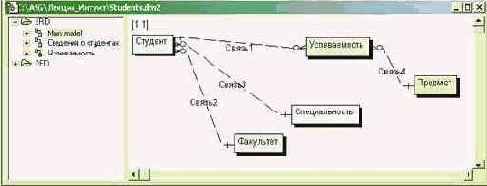
Создание новой модели может начинаться с задания только имен сущностей и связей между ними, как показано на рис. 3.2, который соответствует описанному выше примеру. Связи (неидентифицирующего типа) следует создавать в направлении от предполагаемого первичного ключа к внешнему. Для всех связей в модели заданы условия соблюдения ссылочной целостности: каскадные изменения при изменении и удалении данных в главной таблице и контроль с запретом неверного ввода (restrict) в операциях обновления и добавления данных в дочерних таблицах (см. рис. 3.3).
увеличить изображение
Рис. 3.2. Простейший вид ER-диаграммы в системе CASE Studio
Далее для каждой сущности в окне свойств (рис. рис. 3.4) можно задать название соответствующей ей таблицы в физической модели, названия атрибутов концептуальной модели и полей физической модели с указанием их типа, размера, с заданием ключей, надписей (Notes), описаний и пр. Следует отметить, что для описания полей физической модели необходимо знать типы данных той СУБД, для которой она разрабатывается. В последующем будут разобраны типы данных полей в системах Visual FoxPro, Microsoft Access и Microsoft SQL Server.
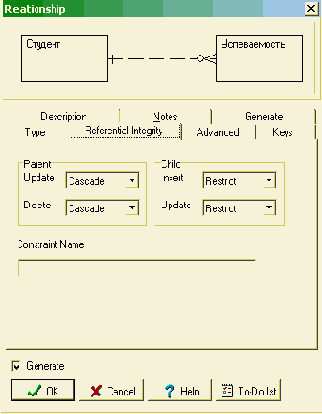
Рис. 3.3. Окно описания свойств связи
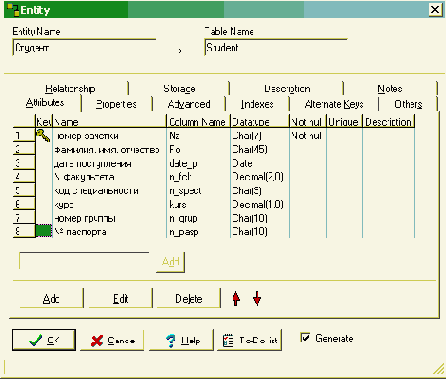
Рис. 3.4. Окно описания свойств сущности и таблицы
После описания всех атрибутов и полей может быть использована различная детализация показа концептуальной (в меню View - Display Level, см. рис. 3.5) и физической (в меню View нужно поставить галочку у позиции Physical View) моделей.

Рис. 3.5. Меню задания режима показа модели
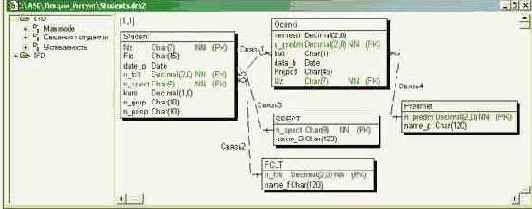
На рис. 3.6 показана концептуальная модель для описанного выше примера, на рис. рис. 3.7 - физическая модель для СУБД Oracle 9i.
увеличить изображение
Рис. 3.6. Концептуальная модель базы данных
увеличить изображение
Рис. 3.7. Физическая модель базы данных
Далее можно описать права групп пользователей и права отдельных пользователей (меню системы пункт Model - Users Roles и Model - Users), если эту информацию нужно использовать при создании базы данных.
На основе описания физической модели был сгенерирован текст программ для создания базы данных в СУБД Oracle (в меню системы пункт Model - Script Generation) и, после конвертации модели, - для Microsoft Access.
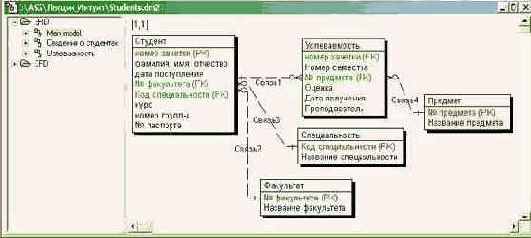
Концептуальная модель базы данных
На концептуальном уровне данные информационной системы состоят из двух основных сущностей: "Студент" и "Успеваемость".
Минимальный состав атрибутов и их описание для сущности "Студент" представлены в табл. 3.1.
Таблица 3.1. Атрибуты сущности "Студент"
Имя атрибутаОписание, особенности использования| Номер зачетки | Первичный ключ - уникальный номер, однозначно идентифицирующий студента университета |
| Фамилия, имя, отчество | Является простым с точки зрения экземпляра сущности, при необходимости из общего поля можно выделить составляющие его фамилию, имя и отчество или фамилию и инициалы, однако на практике часто этот атрибут разделяют на 3 отдельных; первый вариант является более экономичным по необходимой общей ширине поля таблицы |
| Дата поступления в университет | В нашей стране наиболее часто используется формат работы с датой в виде ДД.ММ.ГГ, что совпадает с немецким (German) форматом дат. Количество цифр года: либо две - для новых систем, поддерживающих заданный в Microsoft Windows годичный интервал (Панель управления - Язык и стандарты - Дата - "При вводе двух цифр года воспринимать их как год между:"), или для систем, в которых аналогичный интервал может быть задан в программе, - либо 4 цифры |
| Факультет (№ факультета) | Может быть сложным (кроме кода и названия, может содержать и другие сведения); даже в том случае, если для сущности "Студент" мы хотим сохранять название факультета, оно должно быть представлено в одинаковом виде для каждого факультета, поэтому, в соответствии с принципами нормализации баз данных, этот атрибут следует представить в виде номера, являющегося внешним ключом для новой сущности - "Факультет", в которой каждому номеру, являющемуся первичным ключом, будут соответствовать название и прочие атрибуты этой сущности |
| Специальность(код специальности) | Может быть сложным, кроме того, необходимо использовать справочник министерства с утвержденными кодами специальностей, поэтому данный атрибут должен хранить код специальности - внешний ключ для первичного ключа новой сущности "Специальность" |
| Курс | Число от 1 до 5 |
| Номер группы | Трехзначное число |
| Номер паспорта | Состав и вид паспортных данных определяется требованиями бухгалтерской отчетности перед налоговыми органами, фондами социального страхования и пенсионным фондом |
| ... | Прочие атрибуты, которых может быть достаточно много |
В табл. 3.2-3.5 представлены атрибуты сущностей "Успеваемость", "Факультет", "Специальность", "Предмет".
Таблица 3.2. Атрибуты сущности "Успеваемость"Имя атрибутаОписание, особенности использования
| Номер зачетки | Внешний ключ (к сущности "Студент") |
| Номер семестра | Число от 1 до 10 |
| Предмет (№ предмета) | Может быть сложным, его следует заменить на его номер (внешний ключ) и связать с новой сущностью "Предмет", состоящий, как минимум, из атрибутов "номер предмета" (первичный ключ) и "название предмета" |
| Оценка | Может быть представлена цифрами от 0 до 5 или 1 буквой: например "н" - неявка |
| Дата получения оценки | Формат даты обычно ДД.ММ.ГГ |
| Фамилия преподавателя | Это поле может быть связано с сущностью "Преподаватель". В данном учебном примере ограничимся простым атрибутом |
| ... | Могут быть добавлены и другие атрибуты, например, номер экзаменационной ведомости |
| Номер факультета | Первичный ключ |
| Название факультета | Может быть достаточно длинным, но не более 255 символов |
| ... | Могут быть добавлены и другие атрибуты, например, декан, номер комнаты деканата и т.д. |
| Код специальности | Первичный ключ - значение из справочника министерства |
| Название специальности | Значение из справочника министерства |
| ... | Могут быть добавлены и другие атрибуты |
| № предмета | Первичный ключ |
| Название предмета | Общий справочник университета |
| ... | Могут быть добавлены и другие атрибуты |
Состав данных и связи в концептуальной и физической моделях показаны в табл. 3.6 и табл. 3.7.
Таблица 3.6. Состав базы данных информационной системы
| № п/п | Сущности концептуальной модели | Таблицы физической модели | |
| Название | Информация | ||
| 1. | "Студент" | "SPISOK" | "Список студентов" |
| 2. | "Успеваемость" | "OCENKI" | "Оценки студентов" |
| 3. | "Факультет" | "FCLT" | Справочник факультетов |
| 4. | "Специальность" | "SPECT" | Справочник специальностей |
| 5. | "Предмет" | "PREDMET" | Справочник предметов |
| 1. | "Студент" - "Успеваемость" | "SPISOK" - "OCENKI" |
| 2. | "Студент" - "Факультет" | "SPISOK" - "FCLT" |
| 3. | "Студент" - "Специальность" | "SPISOK" - "SPECT" |
| 4. | "Успеваемость" - "Предмет" | "OCENKI" - "PREDMET" |
Описание модели данных информационной системы "Контингент студентов университета"
Первоначальный этап - создание текстового описания моделируемой системы.
Постановка задачи. Главная задача системы - сохранение в базе данных всех необходимых сведений о студентах и их успеваемости, формирование необходимых печатных форм для проведения зачетной и экзаменационной работы преподавателей, генерация сводных итогов по результатам сессии для руководящих работников деканатов, институтов и университета. При разработке системы следует учитывать, что она взаимодействует с системами "Абитуриент", "Стипендия" и "Кадры университета". Информация о студентах первоначально поступает из системы "Абитуриент" и редактируется на уровне деканатов. Она должна также удовлетворять требованиям бухгалтерского учета по начислению стипендий. Система должна использовать справочник специальностей, утвержденный в вышестоящем министерстве. Информация об успеваемости студентов накапливается постоянно и сохраняется за весь период обучения, после чего переносится в архивное хранилище данных. В системе должен использоваться единый справочник дисциплин (предметов) для всех подразделений университета.
Сгенерированная Case Studio программа создания таблиц базы данных для СУБД Access
' Created 02.02.2006 ' Modified 03.02.2006 ' Project Kontingent ' Model Students ' Company AGTU ' Author Groshev ' Version 2006.1 ' Database Access 2000 '======================================================= '=== MS Access 2000 database creation method '=== '=== 1. Create a new database in the MS Access 2000 '=== 2. Create a new module '=== 3. Copy the CASE Studio 2 output SQL script into the new MS Access 2000 module '=== 4. Select from main menu "Tools" item "References..." and check '=== the "Microsoft DAO 3.6 Object Library." '=== 5. Place your mouse cursor somewhere in the main procedure Main() '=== 6. Run the module code (Click the "Run Sub/UserForm" button or press F5) '======================================================= Public dbs As DAO.Database Public tdf As DAO.TableDef Public idx As DAO.Index Public rel As DAO.Relation Sub Main() Set dbs = CurrentDb() On Error GoTo ErrorHandler Call CreateTables Call CreatePrimaryKeys Call CreateIndexes Call CreateAlterKeys Call CreateRelations Call CreateQueries MsgBox "Script successfully processed.", vbInformation Exit Sub ErrorHandler: Select Case Err.Number Case 3010 MsgBox "Table " & tdf.Name & " allready exist!", vbInformation Err.Clear Case 3284 MsgBox "Index " & idx.Name & " for table " & tdf.Name & " allready exist!", vbInformation Err.Clear Case Else MsgBox Err.Description, vbCritical End Select End Sub ' Create tables '=============== Sub CreateTables() Call CreateTable1 'Student Call CreateTable2 'Ocenki Call CreateTable3 'Predmet Call CreateTable4 'FCLT Call CreateTable5 'SPECT End Sub '=== Create table Student ====== Sub CreateTable1() Set tdf = dbs.CreateTableDef( "Student" ) Call AddFieldToTable("Nz", dbText, 7, 0, "", "", "", TRUE ) Call AddFieldToTable("Fio", dbText, 45, 0, "", "", "", FALSE ) Call AddFieldToTable("date_p", dbDate, 0, 0, "", "", "", FALSE ) Call AddFieldToTable("n_fclt", dbSingle, 0, 0, "", "", "", TRUE ) Call AddFieldToTable("n_spect", dbText, 9, 0, "", "", "", TRUE ) Call AddFieldToTable("kurs", dbSingle, 0, 0, "", "", "", FALSE ) Call AddFieldToTable("n_grup", dbText, 10, 0, "", "", "", FALSE ) Call AddFieldToTable("n_pasp", dbText, 10, 0, "", "", "", FALSE ) dbs.TableDefs.Append tdf End Sub '=== Create table Ocenki ====== Sub CreateTable2() Set tdf = dbs.CreateTableDef( "Ocenki" ) Call AddFieldToTable("semestr", dbSingle, 0, 0, "", "", "", FALSE ) Call AddFieldToTable("n_predm", dbSingle, 0, 0, "", "", "", TRUE ) Call AddFieldToTable("ball", dbText, 1, 0, "", "", "", FALSE ) Call AddFieldToTable("data_b", dbDate, 0, 0, "", "", "", FALSE ) Call AddFieldToTable("Prepod", dbText, 45, 0, "", "", "", FALSE ) Call AddFieldToTable("Nz", dbText, 7, 0, "", "", "", TRUE ) dbs.TableDefs.Append tdf End Sub '=== Create table Predmet ====== Sub CreateTable3() Set tdf = dbs.CreateTableDef( "Predmet" ) Call AddFieldToTable("n_predm", dbSingle, 0, 0, "", "", "", TRUE ) Call AddFieldToTable("name_p", dbText, 120, 0, "", "", "", FALSE ) dbs.TableDefs.Append tdf End Sub '=== Create table FCLT ====== Sub CreateTable4() Set tdf = dbs.CreateTableDef( "FCLT" ) Call AddFieldToTable("n_fclt", dbSingle, 0, 0, "", "", "", TRUE ) Call AddFieldToTable("name_f", dbText, 120, 0, "", "", "", FALSE ) dbs.TableDefs.Append tdf End Sub '=== Create table SPECT ====== Sub CreateTable5() Set tdf = dbs.CreateTableDef( "SPECT" ) Call AddFieldToTable("n_spect", dbText, 9, 0, "", "", "", TRUE ) Call AddFieldToTable("name_S", dbText, 120, 0, "", "", "", FALSE ) dbs.TableDefs.Append tdf End Sub ' Create primary keys '===================== Sub CreatePrimaryKeys() '=== Create primary key for table Student ====== Set tdf = dbs.TableDefs( "Student" ) Set idx = tdf.CreateIndex( "pk_Student" ) idx.Primary = True idx.Unique = True idx.IgnoreNulls = False Call AddFieldToIndex( "Nz", False ) tdf.Indexes.Append idx '=== Create primary key for table Predmet ====== Set tdf = dbs.TableDefs( "Predmet" ) Set idx = tdf.CreateIndex( "pk_Predmet" ) idx.Primary = True idx.Unique = True idx.IgnoreNulls = False Call AddFieldToIndex( "n_predm", False ) tdf.Indexes.Append idx '=== Create primary key for table FCLT ====== Set tdf = dbs.TableDefs( "FCLT" ) Set idx = tdf.CreateIndex( "pk_FCLT" ) idx.Primary = True idx.Unique = True idx.IgnoreNulls = False Call AddFieldToIndex( "n_fclt", False ) tdf.Indexes.Append idx '=== Create primary key for table SPECT ====== Set tdf = dbs.TableDefs( "SPECT" ) Set idx = tdf.CreateIndex( "pk_SPECT" ) idx.Primary = True idx.Unique = True idx.IgnoreNulls = False Call AddFieldToIndex( "n_spect", False ) tdf.Indexes.Append idx End Sub ' Create indexes '================ Sub CreateIndexes() End Sub ' Create alter keys (unique indexes in MS ACCESS) '================================================ Sub CreateAlterKeys() End Sub ' Create relations '================== Sub CreateRelations() '=== Create relations between parent table Student and child table Ocenki ====== Set rel = dbs.CreateRelation("Student_Ocenki") rel.Table = "Student" rel.ForeignTable = "Ocenki" rel.Attributes = dbRelationUpdateCascade+dbRelationDeleteCascade Call AddFieldToRelation("Nz", "Nz") dbs.Relations.Append rel '=== Create relations between parent table Predmet and child table Ocenki ====== Set rel = dbs.CreateRelation("Predmet_Ocenki") rel.Table = "Predmet" rel.ForeignTable = "Ocenki" rel.Attributes = dbRelationUpdateCascade+dbRelationDeleteCascade Call AddFieldToRelation("n_predm", "n_predm") dbs.Relations.Append rel '=== Create relations between parent table FCLT and child table Student ====== Set rel = dbs.CreateRelation("FCLT_Student") rel.Table = "FCLT" rel.ForeignTable = "Student" rel.Attributes = dbRelationUpdateCascade+dbRelationDeleteCascade Call AddFieldToRelation("n_fclt", "n_fclt") dbs.Relations.Append rel '=== Create relations between parent table SPECT and child table Student ====== Set rel = dbs.CreateRelation("SPECT_Student") rel.Table = "SPECT" rel.ForeignTable = "Student" rel.Attributes = dbRelationUpdateCascade+dbRelationDeleteCascade Call AddFieldToRelation("n_spect", "n_spect") dbs.Relations.Append rel End Sub ' Create queries '================ Sub CreateQueries() Dim qdf As QueryDef End Sub ' Add fields to table '===================== Sub AddFieldToTable(FieldName As String, DataType As String, SizeCol As Integer, Attributes As Long, DefaultValue As Variant, ValText As String, ValRule As String, NotN As Boolean) Dim fld As DAO.Field Set fld = tdf.CreateField( FieldName, DataType ) If SizeCol <> 0 Then fld.Size = SizeCol If Attributes <> 0 Then fld.Attributes = Attributes fld.Required = NotN fld.DefaultValue = DefaultValue fld.ValidationRule = ValRule fld.ValidationText = ValText tdf.Fields.Append fld End Sub ' Add properties to table '========================= Sub AddPropertyToTable( PropertyName As String, Value As Variant, DataType As String) Dim prp As DAO.Property Set prp = tdf.CreateProperty(PropertyName, DataType, Value) tdf.Properties.Append prp End Sub ' Add properties to field '========================= Sub AddPropertyToField(FieldName As String, PropertyName As String, Value As Variant, DataType As String) Dim prp As DAO.Property Dim fld As DAO.Field Set fld = tdf.Fields( FieldName ) Set prp = fld.CreateProperty(PropertyName, DataType, Value) fld.Properties.Append prp End Sub ' Add fields to index '===================== Sub AddFieldToIndex( FieldName As String, Descending As Boolean ) Dim fld As DAO.Field Set fld = idx.CreateField( FieldName ) If Descending = True Then fld.Attributes = dbDescending idx.Fields.Append fld End Sub ' Add fields to relation '======================== Sub AddFieldToRelation( PKField As String, FKField As String ) Dim fld As DAO.Field Set fld = rel.CreateField( PKField ) fld.ForeignName = FKField rel.Fields.Append fld End Sub
Сгенерированная Case Studio SQL-программа создания таблиц базы данных для сервера Oracle
/* Created 02.02.2006 Modified 03.02.2006 Project Kontingent Model Students Company AGTU Author Groshev Version 2006.1 Database Oracle 9i */ Create table "Student" ( "Nz" Char(7) NOT NULL , "Fio" Char(45), "date_p" Date, "n_fclt" Decimal(2,0) NOT NULL , "n_spect" Char(9) NOT NULL , "kurs" Decimal(1,0), "n_grup" Char(10), "n_pasp" Char(10)) / Create table "Ocenki" ( "semestr" Decimal(2,0), "n_predm" Decimal(2,0) NOT NULL , "ball" Char(1), "data_b" Date, "Prepod" Char(45), "Nz" Char(7) NOT NULL ) / Create table "Predmet" ( "n_predm" Decimal(2,0) NOT NULL , "name_p" Char(120)) / Create table "FCLT" ( "n_fclt" Decimal(2,0) NOT NULL , "name_f" Char(120)) / Create table "SPECT" ( "n_spect" Char(9) NOT NULL , "name_S" Char(120)) / Alter table "Student" add primary key ("Nz") / Alter table "Predmet" add primary key ("n_predm") / Alter table "FCLT" add primary key ("n_fclt") / Alter table "SPECT" add primary key ("n_spect") / Alter table "Ocenki" add foreign key ("Nz") references "Student" ("Nz") on delete cascade / Alter table "Ocenki" add foreign key ("n_predm") references "Predmet" ("n_predm") on delete cascade / Alter table "Student" add foreign key ("n_fclt") references "FCLT" ("n_fclt") on delete cascade / Alter table "Student" add foreign key ("n_spect") references "SPECT" ("n_spect") on delete cascade / -- Update trigger for Student Create Trigger "tu_Student" after update of "Nz","n_fclt","n_spect" on "Student" referencing new as new_upd old as old_upd for each row declare numrows integer; begin -- cascade child Ocenki update when parent Student changed if (:old_upd."Nz" != :new_upd."Nz") then begin update "Ocenki" set "Nz" = :new_upd."Nz" where "Ocenki"."Nz" = :old_upd."Nz" ; end; end if; -- restrict parent SPECT when child Student updated if :new_upd."n_spect" != :old_upd."n_spect" then begin select count( * ) into numrows from "SPECT" where :new_upd."n_spect" = "SPECT"."n_spect"; if ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20002,'Parent does not exist.
Cannot update child.'); end; end if; end; end if; -- restrict parent FCLT when child Student updated if :new_upd."n_fclt" != :old_upd."n_fclt" then begin select count( * ) into numrows from "FCLT" where :new_upd."n_fclt" = "FCLT"."n_fclt"; if ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20002,'Parent does not exist. Cannot update child.'); end; end if; end; end if;
end; / -- Update trigger for Ocenki Create Trigger "tu_Ocenki" after update of "n_predm","Nz" on "Ocenki" referencing new as new_upd old as old_upd for each row declare numrows integer; begin -- restrict parent Predmet when child Ocenki updated if :new_upd."n_predm" != :old_upd."n_predm" then begin select count( * ) into numrows from "Predmet" where :new_upd."n_predm" = "Predmet"."n_predm"; if ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20002,'Parent does not exist. Cannot update child.'); end; end if; end; end if; -- restrict parent Student when child Ocenki updated if :new_upd."Nz" != :old_upd."Nz" then begin select count( * ) into numrows from "Student" where :new_upd."Nz" = "Student"."Nz"; if ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20002,'Parent does not exist. Cannot update child.'); end; end if; end; end if;
end; / -- Update trigger for Predmet Create Trigger "tu_Predmet" after update of "n_predm" on "Predmet" referencing new as new_upd old as old_upd for each row declare numrows integer; begin -- cascade child Ocenki update when parent Predmet changed if (:old_upd."n_predm" != :new_upd."n_predm") then begin update "Ocenki" set "n_predm" = :new_upd."n_predm" where "Ocenki"."n_predm" = :old_upd."n_predm" ; end; end if; end; / -- Update trigger for FCLT Create Trigger "tu_FCLT" after update of "n_fclt" on "FCLT" referencing new as new_upd old as old_upd for each row declare numrows integer; begin -- cascade child Student update when parent FCLT changed if (:old_upd."n_fclt" != :new_upd."n_fclt") then begin update "Student" set "n_fclt" = :new_upd."n_fclt" where "Student"."n_fclt" = :old_upd."n_fclt" ; end; end if; end; / -- Update trigger for SPECT Create Trigger "tu_SPECT" after update of "n_spect" on "SPECT" referencing new as new_upd old as old_upd for each row declare numrows integer; begin -- cascade child Student update when parent SPECT changed if (:old_upd."n_spect" != :new_upd."n_spect") then begin update "Student" set "n_spect" = :new_upd."n_spect" where "Student"."n_spect" = :old_upd."n_spect" ; end; end if; end; / -- Insert trigger for Student Create Trigger "ti_Student" after insert on "Student" referencing new as new_ins for each row declare numrows integer; begin -- restrict child Student when parent SPECT insert if (:new_ins."n_spect" is not null) then begin select count( * ) into numrows from "SPECT" where :new_ins."n_spect" = "SPECT"."n_spect"; IF ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20004,'Parent does not exist.
Cannot insert child.'); end; end if; end; end if; -- restrict child Student when parent FCLT insert if (:new_ins."n_fclt" is not null) then begin select count( * ) into numrows from "FCLT" where :new_ins."n_fclt" = "FCLT"."n_fclt";
IF ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20004,'Parent does not exist. Cannot insert child.'); end; end if; end; end if; end; / -- Insert trigger for Ocenki Create Trigger "ti_Ocenki" after insert on "Ocenki" referencing new as new_ins for each row declare numrows integer; begin -- restrict child Ocenki when parent Predmet insert if (:new_ins."n_predm" is not null) then begin select count( * ) into numrows from "Predmet" where :new_ins."n_predm" = "Predmet"."n_predm"; IF ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20004,'Parent does not exist. Cannot insert child.'); end; end if; end; end if; -- restrict child Ocenki when parent Student insert if (:new_ins."Nz" is not null) then begin select count( * ) into numrows from "Student" where :new_ins."Nz" = "Student"."Nz"; IF ( numrows = 0 ) then begin RAISE_APPLICATION_ERROR(-20004,'Parent does not exist. Cannot insert child.'); end; end if; end; end if; end; / Create role "Stud_admin" / Create role "Dekan" / Grant "Stud_admin" to "Petrov_P_P" / Grant "Dekan" to "Иванов_И_И" / /* Roles permissions */ Grant select on "Student" to "Stud_admin" / Grant update on "Student" to "Stud_admin" / Grant delete on "Student" to "Stud_admin" / Grant insert on "Student" to "Stud_admin" / Grant references on "Student" to "Stud_admin" / Grant select on "Student" to "Dekan" / Grant update on "Student" to "Dekan" / Grant delete on "Student" to "Dekan" / Grant insert on "Student" to "Dekan" / Grant references on "Student" to "Dekan" / Grant select on "Ocenki" to "Stud_admin" / Grant update on "Ocenki" to "Stud_admin" / Grant delete on "Ocenki" to "Stud_admin" / Grant insert on "Ocenki" to "Stud_admin" / Grant references on "Ocenki" to "Stud_admin" / Grant select on "Ocenki" to "Dekan" / Grant update on "Ocenki" to "Dekan" / Grant delete on "Ocenki" to "Dekan" / Grant insert on "Ocenki" to "Dekan" / Grant references on "Ocenki" to "Dekan" / Grant select on "Predmet" to "Stud_admin" / Grant update on "Predmet" to "Stud_admin" / Grant delete on "Predmet" to "Stud_admin" / Grant insert on "Predmet" to "Stud_admin" / Grant references on "Predmet" to "Stud_admin" / Grant select on "FCLT" to "Stud_admin" / Grant update on "FCLT" to "Stud_admin" / Grant delete on "FCLT" to "Stud_admin" / Grant insert on "FCLT" to "Stud_admin" / Grant references on "FCLT" to "Stud_admin" / Grant select on "SPECT" to "Stud_admin" / Grant update on "SPECT" to "Stud_admin" / Grant delete on "SPECT" to "Stud_admin" / Grant insert on "SPECT" to "Stud_admin" / Grant references on "SPECT" to "Stud_admin" / /* Users permissions */
Использование стандартных режимов BROWSE и EDIT для работы с таблицами базы
В системе VFP существует два основных режима работы с таблицами (и, соответственно, команды языка этой системы): Browse - табличный формат и Edit - форма с построчным расположением полей.
Существует много разных способов открыть окно таблицы базы данных для редактирования в одном из этих режимов, в том числе:
- в открытом окне модификации структуры базы (Database Designer) щелкнуть правой кнопкой мыши на таблице и выбрать команду Browse;щелкнуть мышкой на значке Open стандартной панели инструментов, задать тип файла Table, выбрать нужную таблицу и дать команду Browse в окне Command или в пункте меню View;открыть окно Data session (из пункта главного меню Window), в нем открыть нужные таблицы (кнопка Open), затем выбрать нужную Вам открытую таблицу и нажать на кнопку Browse;создать проект, добавить в него базу данных (внешняя) и в окне проекта выбрать для нужной таблицы команду Browse (полезно сразу создать проект, тогда не нужно будет искать файлы разрабатываемой системы на диске, все файлы можно создавать в окне проекта с указанием, где они будут располагаться на диске);написать в окне Command команду USE ?, выбрать таблицу и написать команду BROWSE.
После вариантов 1-4 в окне Command мы увидим 2 или 3 команды (вторая может отсутствовать), например, для табл. 4.4, следующие:
USE c:\asg\students\fclt.dbf IN 0 EXCLUSIVE - открыть таблицу в первой свободной рабочей зоне с алиасом (псевдонимом) FCLT эксклюзивно;
SELECT FCLT - выбрать рабочую зону с алиасом FCLT;
BROWSE LAST - показать на экране таблицу в той же конфигурации, как ранее (если в структуре таблицы добавлены новые поля или ранее был задан показ не всех полей, а нужно показать все, следует написать команду BROWSE NORMAL).
В результате будет открыто окно таблицы базы данных (рис. 4.12), изменится пункт главного меню View (Вид) - в нем появятся пункты Browse и Edit для переключения режимов, кроме того, пункт Append mode - режим автоматического добавления записей в таблицу (возможен только при работе с таблицами из системы VFP, в программном режиме для добавления записей служат команды APPEND: и INSERT:).
В системе VFP существует два основных режима работы с таблицами (и, соответственно, команды языка этой системы): Browse - табличный формат и Edit - форма с построчным расположением полей.
Существует много разных способов открыть окно таблицы базы данных для редактирования в одном из этих режимов, в том числе:
- в открытом окне модификации структуры базы (Database Designer) щелкнуть правой кнопкой мыши на таблице и выбрать команду Browse;щелкнуть мышкой на значке Open стандартной панели инструментов, задать тип файла Table, выбрать нужную таблицу и дать команду Browse в окне Command или в пункте меню View;открыть окно Data session (из пункта главного меню Window), в нем открыть нужные таблицы (кнопка Open), затем выбрать нужную Вам открытую таблицу и нажать на кнопку Browse;создать проект, добавить в него базу данных (внешняя) и в окне проекта выбрать для нужной таблицы команду Browse (полезно сразу создать проект, тогда не нужно будет искать файлы разрабатываемой системы на диске, все файлы можно создавать в окне проекта с указанием, где они будут располагаться на диске);написать в окне Command команду USE ?, выбрать таблицу и написать команду BROWSE.
После вариантов 1-4 в окне Command мы увидим 2 или 3 команды (вторая может отсутствовать), например, для табл. 4.4, следующие:
USE c:\asg\students\fclt.dbf IN 0 EXCLUSIVE - открыть таблицу в первой свободной рабочей зоне с алиасом (псевдонимом) FCLT эксклюзивно;
SELECT FCLT - выбрать рабочую зону с алиасом FCLT;
BROWSE LAST - показать на экране таблицу в той же конфигурации, как ранее (если в структуре таблицы добавлены новые поля или ранее был задан показ не всех полей, а нужно показать все, следует написать команду BROWSE NORMAL).
В результате будет открыто окно таблицы базы данных (рис. 4.12), изменится пункт главного меню View (Вид) - в нем появятся пункты Browse и Edit для переключения режимов, кроме того, пункт Append mode - режим автоматического добавления записей в таблицу (возможен только при работе с таблицами из системы VFP, в программном режиме для добавления записей служат команды APPEND: и INSERT:).
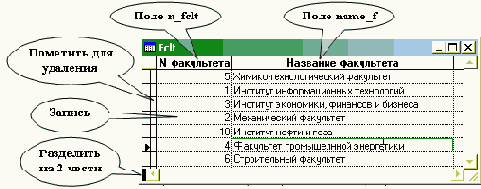
Рис. 4.12. Стандартный режим Browse работы с таблицей
Выбрав режимы Browse и Append mode (в меню у этих пунктов появится галочка), мы сможем занести новые записи в таблицы нашей базы.
Окно Browse имеет очень много возможностей, которые используются при программировании (см. полный синтаксис команды Browse в приложении). Поля таблиц на экране можно менять местами, изменять их ширину и пр. В диалоговом режиме VFP по умолчанию выполняется команда Browse Last - открыть окно в той конфигурации, в которой оно было открыто в предыдущий раз. Если вы при модификации структуры таблицы добавили в нее новое поле, оно может не появиться на экране. В этом случае нужно написать в окне Command команду Browse или Browse normal.
Окно Browse можно разделить на 2 части. Одна из них может быть в режиме Browse, другая - Edit, что удобно при работе с таблицами, имеющими большое количество полей. Можно изменять расположение и ширину полей.
Назначение узкой белой колонки слева от полей таблицы - пометить запись для удаления. Помеченная запись может быть видна с черной отметкой в этой колонке (set delete off) или не видна и как бы отсутствует (set delete on). Помеченные записи можно удалить из файла таблицы (командой Pack), но эта операция связана с переписыванием информации из одного файла в другой, может выполняться только в эксклюзивном режиме открытия таблицы, поэтому выполняется нечасто и обычно не простым пользователем, а администратором базы или программистом.
Режим Edit для той же таблицы показан на рис. 4.13.
В таблице 3-я запись помечена для удаления. Отметку легко снять, повторно щелкнув по черной полоске слева от записи. Она видна, если параметр системы SET DELETED имеет значение OFF.

Рис. 4.13. Стандартный режим Edit работы с таблицей
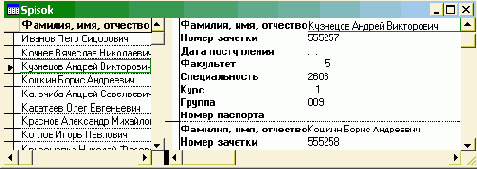
Рис. 4.14. Стандартный режим с разделением окна на 2 части
Возможен показ таблицы с разделением ее на 2 части, одна из которых будет в режиме Browse, другая - в режиме Edit (рис. 4.14).
Режим сохранения добавленных, измененных и удаленных данных зависит от того, используется или нет буферизация данных. Изменить режим можно в свойствах рабочей зоны (Properties для выбранной таблицы в меню или в окне Data Session), окно описания свойств показано на рис. 4.15
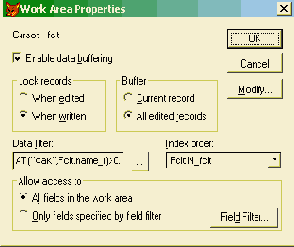
Рис. 4.15. Окно свойств рабочей зоны, в которой открыта таблица Fclt.dbf
Если режим буферизации не задан, сохранение информации происходит сразу при выходе из поля редактирования или закрытии таблицы.
В режиме буферизации изменения заносятся в таблицу только в том случае, если перед ее закрытием дана команда =TABLEUPDATE(.T.).
Буферизация бывает оптимистическая (Lock records when written) и пессимистическая (Lock records when edited), на уровне одной записи (Buffer current record) или многих (Buffer all edited records).
Правильное использование режимов буферизации имеет большое значение при многопользовательском режиме работы с одной таблицей базы данных. В режиме оптимистической буферизации сразу несколько пользователей могут редактировать одни и те же записи и поля. В VFP имеются специальные механизмы разрешения конфликтов сохранения данных, которые могут возникать в этом случае.
Более подробные сведения о многопользовательской работе и использовании режимов буферизации можно найти в справочной системе VFP.
Особенность VFP при показе в стандартных режимах двух таблиц, между которыми установлена связь: в дочерней таблице система показывает только те записи, внешний ключ которых соответствует значению первичного ключа главной таблицы (см. рис. 4.16).
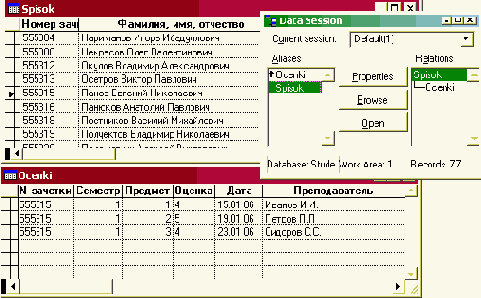
Рис. 4.16. Работа с таблицами, между которыми установлена связь
Для разрабатываемой информационной системы следует занести в стандартном режиме работы с таблицами информацию в справочники - таблицы табл. 4.4, табл. 4.5 и табл. 4.7. Список студентов и список их оценок лучше заполнять с использованием экранной формы, которая будет создана далее.

<
Рис. 4.12. Стандартный режим Browse работы с таблицей
Выбрав режимы Browse и Append mode (в меню у этих пунктов появится галочка), мы сможем занести новые записи в таблицы нашей базы.
Окно Browse имеет очень много возможностей, которые используются при программировании (см. полный синтаксис команды Browse в приложении). Поля таблиц на экране можно менять местами, изменять их ширину и пр. В диалоговом режиме VFP по умолчанию выполняется команда Browse Last - открыть окно в той конфигурации, в которой оно было открыто в предыдущий раз. Если вы при модификации структуры таблицы добавили в нее новое поле, оно может не появиться на экране. В этом случае нужно написать в окне Command команду Browse или Browse normal.
Окно Browse можно разделить на 2 части. Одна из них может быть в режиме Browse, другая - Edit, что удобно при работе с таблицами, имеющими большое количество полей. Можно изменять расположение и ширину полей.
Назначение узкой белой колонки слева от полей таблицы - пометить запись для удаления. Помеченная запись может быть видна с черной отметкой в этой колонке (set delete off) или не видна и как бы отсутствует (set delete on). Помеченные записи можно удалить из файла таблицы (командой Pack), но эта операция связана с переписыванием информации из одного файла в другой, может выполняться только в эксклюзивном режиме открытия таблицы, поэтому выполняется нечасто и обычно не простым пользователем, а администратором базы или программистом.
Режим Edit для той же таблицы показан на рис. 4.13.
В таблице 3-я запись помечена для удаления. Отметку легко снять, повторно щелкнув по черной полоске слева от записи. Она видна, если параметр системы SET DELETED имеет значение OFF.
Рис. 4.13. Стандартный режим Edit работы с таблицей
Рис. 4.14. Стандартный режим с разделением окна на 2 части
Возможен показ таблицы с разделением ее на 2 части, одна из которых будет в режиме Browse, другая - в режиме Edit (рис. 4.14).
Настройка системы
Перед использованием системы VFP необходимо выполнить некоторые настройки для удобства использования. Для этого в меню Tools следует вызвать команду Options, после чего появится многостраничная экранная форма для задания параметров настройки с аналогичным названием (рис. 4.1).
Рис. 4.1. Окно настройки параметров системы Visual FoxPro
Наиболее существенными являются настройки:
на странице Regional - Date Format - German (дд.мм.гггг) и пр.;страница Debug - можно задать расположение отладочных окон (всего их 7 - Trace, Watch и др.) в отдельном окне в Windows или в главном окне VFP и пр.;страница Editor - можно задать цветовое выделение синтаксиса и прочие параметры окон с текстом программ;страница Data - можно определить, как будут открываться по умолчанию базы и таблицы: эксклюзивно (Open Exclusive) или нет, с использованием одного из возможных режимов буферизации данных (buffering) или нет, будем ли мы видеть помеченные для удаления записи (Ignore deleted records) и многое другое;страница File Locations - следует задать Default Directory - папку по умолчанию, которая будет открываться в командах Open и Save, а также использование и расположение файла сохранения конфигураций (ресурсного файла) foxuser.dbf;страница Forms - следует задать максимальный размер экранных форм - Maximum design area - обычно 800х600 и т.д.
Все заданные параметры будут сохранены в файле foxuser.dbf, если будет нажата кнопка Set As Default.
Еще один файл, который связан с настройкой системы, - Config.fpw. Это текстовый файл, в котором можно записать некоторые команды конфигурирования системы (например, codepage = auto, date = german, screen = off и пр.). Он выполняется автоматически при запуске VFP или приложения, разработанного в этой системе для работы с базой данных.
Во время работы в системе все предварительные установки при необходимости можно изменить.
При работе в VFP очень полезными являются окна Command, в котором можно видеть команды из меню и писать свои команды, и окно Data Session (когда-то раньше оно называлось View), в котором можно видеть все открытые таблицы, установленный порядок по индексам, заданные фильтры и связи между таблицами, и выполнять все эти операции.
Их можно держать постоянно открытыми в главном окне VFP.
Следует знать о таком свойстве окон в VFP, как Dockable - прилипание к границам родительского окна (аналогичное свойство имеют панели инструментов). Если это свойство задано, окно, с одной стороны, может прилипать, но одновременно может и выдвигаться за границы родительского окна и всегда лежит поверх других окон. При большом количестве окон в VFP, 15'' или 17'' мониторе и разрешении 1024х768 лучше это свойство выключить и использовать его на больших мониторах с вынесением ряда окон из основного окна VFP.
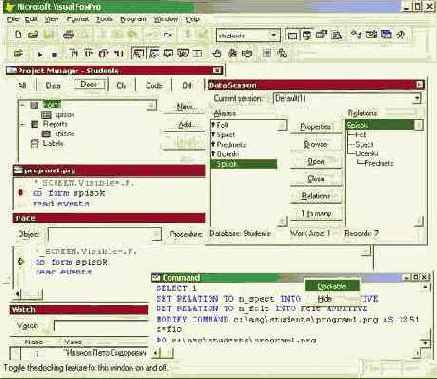
увеличить изображение
Рис. 4.2. Главное окно системы Visual FoxPro с открытыми в нем окнами проекта, программы, Trace, Watch, Data Session и Command
Общая характеристика системы
Visual FoxPro (VFP) - современная СУБД для персональных компьютеров, использующая реляционные базы данных, имеющая объектно-ориентированный алгоритмический язык для работы с информацией, методы визуального программирования и достаточно большие возможности (табл. 4.1). Типы данных, которые могут иметь поля таблиц базы данных, приведены в табл. 4.2 и табл. 4.3
Версия системы 7.0 может работать в операционных системах Windows 9x и ядра NT, версии 8.0 и 9.0 - только в Windows XP, 2000, 2003.
Таблица 4.1. Основные максимальные возможности системы Visual FoxPro
Наименование предельной величиныПредельная величина| Количество записей в файле таблицы | 1 миллиард |
| Размер файла таблицы | 2 гигабайта |
| Количество символов в одной записи | 65500 |
| Количество полей в одной записи | 255 |
| Количество одновременно открытых таблиц | 255 |
| Количество символов в поле таблицы | 254 |
| Количество байтов в индексном ключе в некомпаундном индексе | 100 |
| Количество байтов в индексном ключе в компаундном индексе | 240 |
| Количество открытых индексных файлов для одной таблицы | не ограничено |
| Количество открытых индексов во всех рабочих областях | не ограничено |
| Количество связей | не ограничено |
| Длина выражений связи | не ограничена |
| Размер символьных полей | 254 |
| Размер числовых полей | 20 |
| Количество символов в имени поля в свободной таблице | 10 |
| Количество символов в имени поля в таблице, содержащейся в базе данных | 128 |
| Диапазон целых чисел | + 2 147 483 647 |
| Точность в числовых вычислениях | 16 цифр до 9007199254740992 (253) |
| Действительные числа | до 10308 или 2 1023 |
| Количество переменных по умолчанию | 16384 |
| Количество переменных | 65000 |
| Количество массивов | 65000 |
| Количество элементов в массиве | 65000 |
| Количество строк в исходных программных файлах | не ограничено |
| Размер модуля компилируемой программы | 64 килобайта |
| Размер процедур в файле | не ограничен |
| Количество вложенных DO | 128 |
| Количество вложенных READ | 5 |
| Количество передаваемых параметров | 27 |
| Количество транзакций | 5 |
| Количество объектов в отчете | не ограничено |
| Длина описания отчета | 20 дюймов |
| Количество уровней группировки | 74 |
| Длина символьных переменных в отчете | 255 |
| Количество открытых окон (всех типов) | не ограничено |
| Количество открытых окон BROWSE | 255 |
| Количество символов в символьной строке или переменной памяти | 16 777 184 |
| Количество символов в командной строке | 8192 |
| Количество открытых файлов | возможности ОС |
| Количество нажатий клавиш в макро | 1024 |
| Количество полей в одном запросе SQL | 255 |
Таблица 4.2. Типы данных в системе Visual FoxPro
ТипОписаниеРазмерДиапазонBlobCharacterCurrencyDateDateTimeLogicalNumericVarbinaryVariant| Двоичные данные неограниченной длины. Значения сохраняются в memo (.fpt) файле. Кодовая страница не учитывается | 4 байта в *.dbf | Ограничен доступной памятью, на диске до 2 Гб |
| Текст, состоящий из символов | 1 байт на символ, до 254 символов | Любые символы |
| Денежный формат | 8 байт | - $922337203685477.5807 до $922337203685477.5807 |
| Дата, состоящая из месяца, дня и года | 8 байт | От {^0001-01-01} - 1 января 1 года до {^9999-12-31} - 31 декабря 9999 года |
| Дата и время, состоит из месяца, дня, года, часа, минуты и секунды | 8 байт | От {^0001-01-01} до {^9999-12-31}, время от 00:00:00 до 23:59:59 |
| Логическое значение, True или False | 1 байт | True (.T.) или False (.F.) |
| Целые или действительные числа | 8 байт в памяти; от 1 до 20 байт в *.dbf | - .9999999999E+19 до .9999999999E+20 |
| Двоичные значения. Под пустые концевые значения место на диске не резервируется. Кодовая страница не учитывается | 1 байт на шестнадцатеричное значение, всего до 255 байт | Любое шестнадцатеричное значение |
| Любой тип Visual FoxPro и null-значение. Когда данные сохраняются в переменной, ее тип становится типом данных | См. все другие типы | См. все другие типы |
table class="xml_table" cellpadding="2" cellspacing="1">
Таблица 4.3. Типы данных в полях таблиц системы Visual FoxProТип поляОписаниеРазмерДиапазонCharacter BinaryТекст, состоящий из символов. Кодовая страница не учитывается1 байт на символ, до 254 символовЛюбые символыDoubleДействительные числа удвоенной значимости8 байт+4.94065645841247E-324 до +8.9884656743115E307FloatТо же самое, что и Numeric8 байт в памяти; от 1 до 20 байт в *.dbf- .9999999999E+19 до .9999999999E+20GeneralСсылка на OLE-объект. Значения сохраняются в memo (.fpt) файле4 байт в *.dbfОграничен доступной памятьюIntegerЦелое числовое значение4 байта-2147483647 до 2147483647Integer AutoincЦелое значение, автоматически изменяющееся. Только для чтения (read-only)4 байтаОпределяется значениями Next и StepMemoСимвольный текст. Значения сохраняются в memo (.fpt) файле4 байтa в *.dbfОграничен доступной памятьюMemo BinaryТо же, что Memo. Кодовая страница не учитывается4 байтa в *.dbfОграничен доступной памятьюVarcharСимвольный текст. Varchar подобен Character, но не резервируется место для концевых пробелов1 байт на символ, всего до 254 символовЛюбые символыVarchar BinaryТип Varchar, кодовая страница не учитывается1 байт на символ, всего до 254 символовЛюбые символы Некоторые достоинства системы:
- Широко известный формат таблиц баз данных, что позволяет легко организовать обмен информацией с другими приложениями Microsoft Windows.Современная организация реляционных баз данных, позволяющая хранить информацию о таблицах базы, их свойствах, индексах и связях, задавать условия соблюдения ссылочной целостности, создавать локальные и удаленные представления (Views), связи с серверами, хранимые процедуры, исполняемые при наступлении более 50 различных видов событий (VFP 7.0-9.0).Высокая скорость работы с большими базами данных.Высокая наглядность работы с базами данных: многофункциональное окно Data session позволяет видеть список открытых таблиц баз данных, их связи, фильтры, порядок по индексам, режимы буферизации, переходить к режимам модификации структуры, к работе с информацией таблиц и пр.Высокая скорость разработки приложений с использованием Мастеров (Wizard), Конструкторов (Designer), Построителей (Builder), режим подсказок IntelliSense при написании текста программ, системы отладки и тестирования программ.Собственный объектно-ориентированный язык работы с базами данных, основу которого составляет широко известное ядро xBase.
Наличие в составе системы значительного количества библиотек стандартных классов с доступным для модификации исходным текстом. Возможность использования библиотек других приложений Windows (ActiveX).Возможность разработки приложений, работающих по технологии "клиент-сервер" с данными, размещенными на серверах баз данных Oracle и Microsoft SQL Server и с другими приложениями Microsoft Windows с использованием ODBC и OLEВозможность разработки Интернет-приложений для работы с базами данных и работы с Web-сервисами. Создание и работа с COM и COM+ компонентами (Component Object Model).Возможность разработки проекта для работы с базами данных с компиляцией его в программу, исполняемую в VFP (*.app), в операционной системе Microsoft Windows (*.exe или *.dll) или в Интернет-браузере (*.app).В дистрибутиве системы присутствует большая библиотека примеров, что облегчает освоение всех ее возможностей.
Система VFP предназначена для использования профессиональными программистами, поэтому нет смысла в русификации ее меню и языка - для любого программиста английский синтаксис алгоритмического языка более привычен, чем русский.
Создание базы данных
Разработка любой информационной системы начинается с создания базы данных. Рассмотрим процесс создания базы данных, модель которой описана в предыдущей лекции, в системе VFP.
Для создания новой базы данных можно воспользоваться кнопкой New стандартной панели инструментов (рис. 4.3) или пунктом меню "File - New:".

Рис. 4.3. Стандартная панель инструментов системы Visual FoxPro
Рис. 4.4. Выбор типа файла в диалоге New
Особенность этой команды - возможность создания большого количества различных типов файлов, соответствующих различным типам объектов системы, которые мы видим в окне New, появляющемся после этой команды (рис. 4.4).
В окне New в данном случае нужно выбрать тип файла Database.
Далее можно использовать кнопки New file или Wizard. Если выбрать кнопку Wizard - будут предложены готовые американские образцы баз данных - Address Book, Book Collection, Contact Management, Event Management, Music Collection, Picture Library, Students and Classes, Video Collection и прочие, всего более двух десятков.
Для примера на рис. 4.5 приведена схема базы данных, полученная с помощью Wizard для образца Students and Classes.
Как видно из примера, база данных слишком специфична, не совсем соответствует структуре нашего высшего учебного заведения, используется слишком много не совсем привычных для нас английских терминов, очень много индексов (каждый индекс дублирует информацию полей таблиц, при чрезмерно большом их количестве размер индексного файла может получиться больше, чем размер таблицы, что нерационально). Проще создать новую базу данных, соответствующую разработанной нами ранее модели.
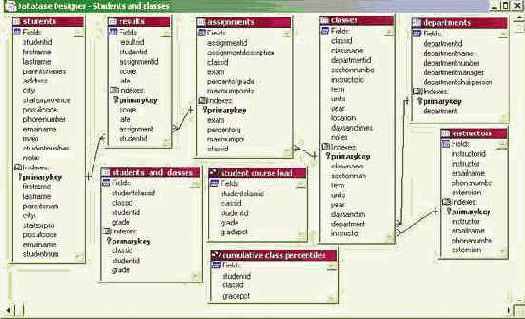
увеличить изображение
Рис. 4.5. Образец базы данных, полученный с использованием Wizard
Выберем кнопку New file для создания собственной базы данных. После этого нужно задать папку на диске, где мы будем сохранять все компоненты, относящиеся к разрабатываемому проекту, и задать название базы данных (расширение файла указывать не надо - система допишет его сама).
Пусть папка и имя базы данных будут Students (рис. 4.6).
Рис. 4.6. Диалог для сохранения базы данных на диске
После нажатия на кнопку Save (Сохранить) будут созданы файлы базы данных (students.dbc, students.dct и students.dcx) и откроется пустое окно модификации структуры базы данных (Database Designer), показанное на рис. 4.7. Следует отметить, что очень многие команды, задаваемые нами с использованием меню системы, отображаются в виде текстовых команд в окне Command (создается протокол команд, который сохраняется), и это может быть использовано для повторного выполнения использованных команд или для включения их в текст программы, а также может быть полезно начинающим пользователям для изучения языка системы VFP. После команды Save в окне Command появятся 2 строки команд: CREATE DATABASE и MODIFY DATABASE, как показано на рис. 4.8.
Поместив курсор мыши в окно Database Designer, щелкнем в нем правой кнопкой мыши и в контекстном меню выберем команду New table:.
Далее выбираем New table, а не Wizard, который нам опять предложил бы американские образцы таблиц за основу, выбираем папку и задаем имя главной таблицы базы - Spisok, после чего открывается окно описания структуры таблицы базы данных (Table Designer) (рис. 4.9).
Рис. 4.7. Окно Конструктора базы данных

Рис. 4.8. Окно Command системы VFP
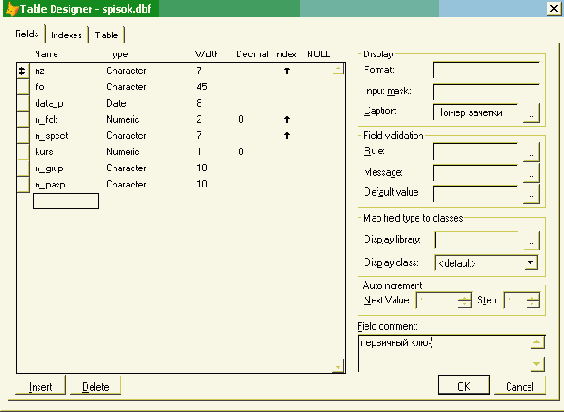
увеличить изображение
Рис. 4.9. Окно Конструктора таблиц
В окне Table Designer описываем все поля таблицы Spisok.dbf- имя поля (Name), тип (Type), ширину (Width), количество десятичных знаков для действительных чисел (Decimal), наличие простого индекса (Index) и задаем заголовок поля таблицы (Caption). Имена полей лучше писать латинскими буквами.
Для индекса NZ на странице Indexes окна Table Designer следует задать тип индекса - Primary (первичный), т.к. номер зачетки - уникальный для каждого студента, однозначно его идентифицирует и поэтому может служить первичным ключом (в таблице обозначения A (Ascending) - индекс в порядке возрастания, P (Primary).
Структура главной таблицы базы данных приведена в табл. 4.3.
Для таблицы, входящей в состав базы данных, в окне Table Designer присутствуют разделы Display, Map field type to classes, Field validation, Field comment, эта информация сохраняется в файле базы данных и поэтому отсутствует при описании структуры свободных таблиц (файлы *.dbf, не входящие в состав базы данных). Таблицу можно удалить из базы, но оставить в виде свободной таблицы на диске; в таком случае информация этих разделов теряется.
Задание заголовков (Caption) для полей при описании структуры таблицы облегчает разработку экранных форм и отчетов - эти названия появятся как подписи для полей (если Caption отсутствует, подписью будет имя поля).
Таблица 4.3. Структура таблицы Spisok.dbfNameTypeWidthDecimalIndexCaption
| Nz | C | 7 | A,P | Номер зачетки | |
| Fio | C | 45 | Фамилия, имя, отчество | ||
| data_p | D | 8 | Дата поступления | ||
| n_fclt | N | 2 | A | Факультет | |
| n_spect | C | 7 | A | Специальность | |
| kurs | N | 1 | Курс | ||
| n_grup | С | 10 | Группа | ||
| n_pasp | С | 10 | Номер паспорта |
табл. 4.4
Таблица 4.4. Структура таблицы Fclt.dbfNameTypeWidthDecimalIndexCaption
| n_fclt | N | 2 | A,P | Номер факультета | |
| name_f | C | 120 | Название факультета |
Точно так же создаем в базе данных следующие таблицы и индексы для табл. 4.5, табл. 4.6, табл. 4.7.
Таблица 4.5. Структура таблицы Spect.dbfNameTypeWidthDecimalIndexCaption
| n_spect | C | 7 | A,P | Код специальности | |
| name_s | C | 120 | Название специальности |
| nz | C | 7 | A | Номер зачетки | |
| semestr | N | 1 | Семестр | ||
| n_predm | N | 2 | A | Предмет | |
| ball | С | 1 | Оценка | ||
| data_b | D | 8 | Дата | ||
| prepod | C | 45 | Преподаватель |
| n_predm | N | 2 | A,P | Номер предмета | |
| name_p | С | 120 | Название предмета |
Далее в окне Database Designer задаем постоянные связи между таблицами в базе, перетаскивая мышкой название первичного индекса к обычному (Regular) индексу (внешний ключ). В результате получаем схему базы данных (рис. 4.10).
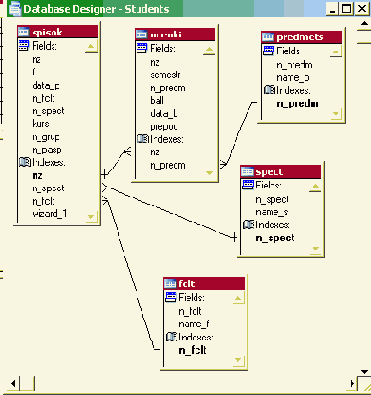
Рис. 4.10. Окно базы данных STUDENTS
Для связей можно задать условия соблюдения ссылочной целостности: каскадное обновление в операциях удаления и вставки и контроль с запретом ввода записей с неверными ключевыми значениями в операциях вставки (см. рис. 4.11). Для заданных условий будет сгенерирован программный код, занесенный в базу данных как хранимые процедуры - триггеры. Эти программы при желании можно просмотреть, изучить механизм их действия или модифицировать, если такая необходимость возникнет. Текст триггеров может представлять значительный интерес для программистов, т.к. он написан в наиболее универсальном виде для работы с различными режимами и базами с использованием стиля оформления, принятого в фирме-разработчике системы VFP.
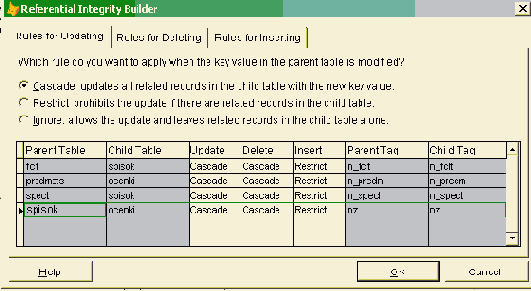
Рис. 4.11. Задание условий соблюдения ссылочной целостности
Типы файлов, которые использует система
Особенность системы - использование значительного количества файлов с различными расширениями для работы с различными типами объектов, но по сути формат многих из них - dbf с мемо-полями.
В табл. 4.4 приведен список основных типов файлов. Знание всех типов файлов необходимо каждому программисту, работающему с системой.
Таблица 4.4. Список расширений для различных типов файлов VFP
Основной файлMemo поляИндексыСкомпилированный файлТип файла| .dbc | .dct | .dcx | База данных (Database) | |
| .dbf | .fpt | .cdx, .idx | Таблица (Table) | |
| .frx | .frt | Отчет (Report) | ||
| .h | Файл заголовков | |||
| .ico | Иконка | |||
| .lbx | .lbt | Этикетка (Label) | ||
| .mnx | .mnt | .mpx | Меню | |
| .mpr | Сгенерированная программа меню | |||
| .ocx | Библиотека объектов ActiveX | |||
| .pjx | .pjt | .exe, .dll, .app | Мемо-поля проекта | |
| .prg | .fxp | Файл программы | ||
| .qpr | .qpx | Программа-запрос | ||
| .scx | .sct | Форма (Form) | ||
| .vcx | .vct | Библиотека Visual FoxPro |
Использование Мастера для разработки экранных форм
В системе VFP Мастер (Wizard) разработки экранных форм создает их с использованием первого стиля. Созданные Мастером простейшие формы далее, как правило, приходится дополнять и модифицировать для реализации всех необходимых условий работы с базой. Мастера системы VFP используют библиотеки объектов, в которых реализованы механизмы сетевой работы с любыми базами данных в разных режимах буферизации или без нее. Поэтому модификацию существующих программных модулей библиотечных объектов следует выполнять при необходимости крайне осторожно, разобравшись в стандартном программном коде.
При работе с базой данных наиболее удобно использовать режим буферизации данных на уровне многих записей - в этом случае все изменения, выполненные в различных таблицах (редактирование существующих данных, добавление и удаление записей) могут быть сохранены после нажатия на соответствующую кнопку на экране или панели инструментов, либо все изменения могут быть отменены.
Мастер экранных форм (Form Wizard) позволяет разрабатывать экранные формы, имеющие некоторый стандартный набор кнопок управления. В этом случае данные становятся доступны для редактирования только после нажатия на кнопку Правка, а по завершении редактирования надо нажать на кнопку Сохранить или Отменить.
При использовании Мастера проектов (Application Wizard) можно разрабатывать экранные формы, входящие в состав проекта, и оформленные в новом стиле - все данные на экране изначально доступны для редактирования, пользователь может в любой момент принять решение, сохранять изменения или нет. Для управления используется не набор кнопок, а панели инструментов. Система следит за изменениями: если Вы попытаетесь закончить работать с базой, не дав команды о сохранении или отмене изменений, появится соответствующий запрос (как в программах Word или в Excel при закрытии окна).
Воспользуемся способом разработки экранных форм с использованием Form Wizard. Предварительно откроем базу данных Students в эксклюзивном режиме (в окне Open должна стоять галочка у слова Exclusive).
Далее нажимаем на кнопку New на стандартной панели инструментов системы VFP, выбираем тип нового файла - Form - и нажимаем на большую кнопку Wizard (см. ранее рис. 2.2 - экран New). В появившемся окне Wizard Selection выбираем вариант One-to-Many Form Wizard - разработка экранной формы для двух связанных таблиц, показывающей поля одной записи главной таблицы и множество связанных записей дочерней таблицы в виде объекта Grid. В нашем случае главная таблица базы - Spisok, связанная с ней таблица - Ocenki.
Работа Мастера заключается в пошаговом формировании ответов на определенные вопросы с генерацией для полученного таким образом описания экранной формы или другого объекта при использовании других Мастеров.
Шаг 1 (Step 1, рис. 5.6): выбор главной таблицы и ее полей. Экран содержит краткое описание этого шага и следующие списки: выбора базы данных и таблиц (Databases and tables), доступных полей выбранной таблицы (Available fields) и выбранных для размещения на экранной форме полей главной таблицы (Selected fields).
Рис. 5.6. Шаг 1 Мастера разработки экранных форм
Для выбора необходимых полей служат кнопки со стрелками или может использоваться двойной щелчок мыши.
Далее нажимаем на кнопку Next > и переходим ко второму шагу, где нам необходимо выбрать на аналогичном экране таблицу, связанную с главной связью от одной записи - ко многим, и ее поля, в нашем случае это все поля таблицы Ocenki.
На третьем шаге нужно подтвердить, что выбранные таблицы действительно связаны по значению поля NZ.
Четвертый шаг - выбор стиля формы и типа кнопок (рис. 5.7). Использование кнопок с картинками (Picture buttons) имеет то преимущество, что изображение носит интернациональный характер, после усвоения назначения кнопок быстрее воспринимается, чем текст. Другой вариант в международных многоязыковых системах - сохранять все названия кнопок в отдельных файлах или в базе данных, т.е. с названиями кнопок связывать значения переменных, которые определяются при запуске системы в работу.
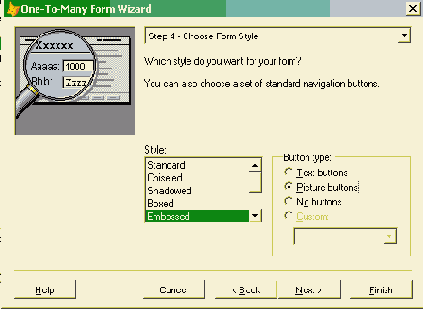
Рис. 5.7. Шаг 4 Мастера разработки форм
Шаг 5 - задание сортировки записей главной таблицы. Можно задать сортировку по имеющемуся у таблицы индексу или указать последовательность полей для создания сложного индекса (не более трех), например, поля N_fclt, N_grup, Fio (рис. 5.8).
Рис. 5.8. Шаг 5 Мастера разработки форм
На шестом, последнем шаге задаем заголовок (Titul) для формы и выбираем завершающую операцию - Save form and modify it in Form Designer - Сохранить форму и модифицировать ее в дизайнере форм.
После нажатия на кнопку Finish выбираем папку для сохранения файлов экранной формы и ее название - можно оставить предлагаемое системой название, совпадающее с названием главной таблицы (у файлов таблицы и формы будут разные расширения).
В результате будет сгенерирована и открыта в дизайнере форма следующего вида (рис. 5.9):
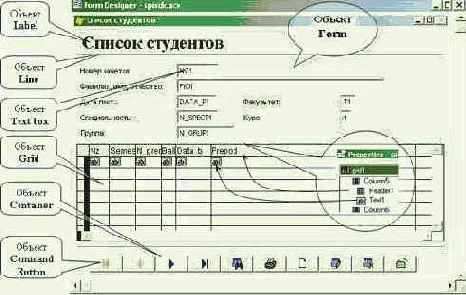
увеличить изображение
Рис. 5.9. Экранная форма, разработанная Мастером
Модификация экранной формы в Конструкторе
При работе с базами данных всегда используются таблицы-справочники. На экранных формах для выбора данных из справочников можно использовать раскрывающиеся списки (в VFP - объект Combo Box) или выполнять выбор из другой раскрывающейся формы после нажатия на командную кнопку. Второй способ позволяет просматривать сложную информацию справочников и одновременно дополнять и редактировать справочник.
Для использования информации из справочных таблиц необходимо добавить их в Data Environment - окно, связанное с экранной формой и описывающее, какие таблицы связаны с формой, как они открываются и закрываются при запуске формы в работу (см. свойства в окне Properties). Другой вариант - в событии Load экранной формы самому написать команды открытия таблиц, задания порядка по индексам и установления связей.
Для начинающих программистов проще воспользоваться первым, визуальным способом. Окно Data Environment можно открыть, щелкнув на соответствующем названии в пункте главного меню View или выбрав команду Data Environment в контекстном меню экранной формы. Вид этого окна показан на рис. 5.13. Щелкнув правой кнопкой мыши на пустом месте окна Data Environment, выберем команду Add в контекстном меню, добавим таблицы Fclt, Spect, Predmеts и зададим правильно связи между ними перетаскиванием мышкой названия поля к названию индекса, как показано на рисунке.
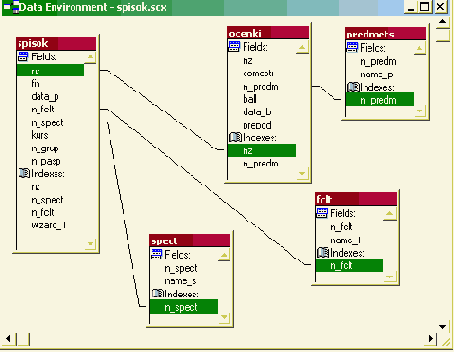
Рис. 5.13. Окно данных экранной формы Data Environment
Теперь можно добавить на экранную форму раскрывающиеся списки для показа информации из справочников факультетов, специальностей и предметов и занесения соответствующих номеров из справочников в список студентов или в таблицу оценок.
Найдем на панели Form Controls объект Combo Box, щелкнем на нем мышкой и покажем область размещения и размер этого объекта на экранной форме Spisok. Затем щелкаем правой кнопкой мыши на нем и в контекстном меню выбираем пункт Builder. В результате в VFP открывается окно Combo Box Builder (рис. 5.14.). Это окно состоит из четырех страниц для выбора исходных данных, стиля и внешнего вида списка и задания, какую колонку и где сохранять при выборе пункта списка.
Затем надо описать свойства вставленного в колонку 3 объекта с именем Combo1:
ControlSourse - если для колонки было задано ocenki.n_predm и BoundTo = .T., это свойство автоматически становится таким же, как свойство колонки, т.е. ocenki.n_predm;RowSourseType 6 - Fields;RowSourse predmets.n_predm, name_p;ColumnCount 2;ColumnWidths 20, 180; BorderStyle 0 - None;SpecialEffect 1 - Plain.
Для показа названия предмета в таблице добавим количество колонок (для объекта Grid свойство ColumnCount изменим на 7), переместим колонку перетаскиванием мышкой за заголовок на четвертое место в таблице после колонки N_predm и опишем свойства колонки 7: ControlSourse - Predmets.name_p (выбором из списка доступных полей); ReadOnly - .T. (делаем эту колонку нередактируемой).
Далее отредактируем заголовки (Header) у всех колонок объекте Grid, цвет фона экранной формы и объекта Grid (BackColor) и цвета объектов Combo box - DisabledBackColor и DisabledForeColor.
В результате экранная форма (после запуска ее в работу) будет иметь вид, показанный на рис. 5.16.
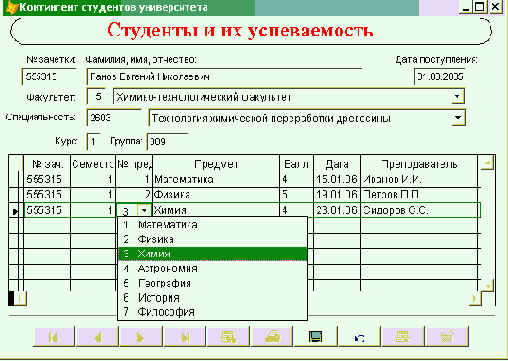
Рис. 5.16. Экранная форма после модификации в Конструкторе
