Нормальные формы ER-схем
Как и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу реляционных нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Мы приведем только очень краткие и неформальные определения трех первых нормальных форм.
В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, "замаскиро-ванных" под атрибуты.
Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность.
В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
Объектно-ориентированные модели данных
Первой формализованной и общепризнанной моделью данных была реляционная модель Кодда. В этой модели, как и во всех следующих, выделялись три аспекта - структурный, целостный и манипуляционный. Структуры данных в реляционной модели основываются на плоских нормализованных отношениях, ограничения целостности выражаются с помощью средств логики первого порядка и, наконец, манипулирование данными осуществляется на основе реляционной алгебры или равносильного ей реляционного исчисления. Как отмечают многие исследователи, своим успехом реляционная модель данных во многом обязана тому, что опиралась на строгий математический аппарат теории множеств, отношений и логики первого порядка. Разработчики любой конкретной реляционной системы считали своим долгом показать соответствие своей конкретной модели данных общей реляционной модели, которая выступала в качестве меры "реляционности" системы.
Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных, не существует. В большой степени поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности.
Один из наиболее известных теоретиков в области моделей данных Беери предлагает в общих чертах формальную основу ООБД, далеко не полную и не являющуюся моделью данных в традиционном смысле, но позволяющую исследователям и разработчикам систем ООБД по крайней мере говорить на одном языке (если, конечно, предложения Беери будут развиты и получат поддержку). Независимо от дальнейшей судьбы этих предложений мы считаем полезным кратко их пересказать.
Во-первых, следуя практике многих ООБД, предлагается выделить два уровня моделирования объектов: нижний (структурный) и верхний (поведенческий).
На структурном уровне поддерживаются сложные объекты, их идентификация и разновидности связи "isa". База данных - это набор элементов данных, связанных отношениями "входит в класс" или "является атрибутом". Таким образом, БД может рассматриваться как ориентированный граф. Важным моментом является поддержание наряду с понятием объекта понятия значения (позже мы увидим, как много на этом построено в одной из успешных объектно-ориентированных СУБД O2).
Важным аспектом является четкое разделение схемы БД и самой БД. В качестве первичных концепций схемного уровня ООБД выступают типы и классы. Отмечается, что во всех системах, использующих только одно понятие (либо тип, либо класс), это понятие неизбежно перегружено: тип предполагает наличие некоторого множества значений, определяемого структурой данных этого типа; класс также предполагает наличие множества объектов, но это множество определяется пользователем. Таким образом, типы и классы играют разную роль, и для строгости и недвусмысленности требуется одновременная поддержка обоих понятий.
Беери не представляет полной формальной модели структурного уровня ООБД, но выражает уверенность, что текущего уровня понимания достаточно, чтобы формализовать такую модель. Что же касается поведенческого уровня, предложен только общий подход к требуемому для этого логическому аппарату (логики первого уровня недостаточно).
Важным, хотя и недостаточно обоснованным предположением Беери является то, что двух традиционных уровней - схемы и данных - для ООБД недостаточно. Для точного определения ООБД требуется уровень мета-схемы, содержимое которой должно определять виды объектов и связей, допустимых на схемном уровне БД. Мета-схема должна играть для ООБД такую же роль, какую играет структурная часть реляционной модели данных для схем реляционных баз данных.
Имеется множество других публикаций, отноcящихся к теме объектно-ориентированных моделей данных, но они либо затрагивают достаточно частные вопросы, либо используют слишком серьезный для этого обзора математический аппарат (например, некоторые авторы определяют объектно-ориентированную модель данных на основе теории категорий).
Для иллюстрации текущего положения дел мы кратко рассмотрим особенности конкретной модели данных, применяемой в объектно-ориентированной СУБД O2 (это, конечно, тоже не модель данных в классическом смысле).
В O2 поддерживаются объекты и значения. Объект - это пара (идентификатор, значение), причем объекты инкапсулированы, т.е. их значения доступны только через методы - процедуры, привязанные к объектам. Значения могут быть атомарными или структурными. Структурные значения строятся из значений или объектов, представленных своими идентификаторами, с помощью конструкторов множеств, кортежей и списков. Элементы структурных значений доступны с помощью предопределенных операций (примитивов).
Возможны два вида организации данных: классы, экземплярами которых являются объекты, инкапсулирующие данные и поведение, и типы, экземплярами которых являются значения. Каждому классу сопоставляется тип, описывающий структуру экземпляров класса. Типы определяются рекурсивно на основе атомарных типов и ранее определенных типов и классов с применением конструкторов. Поведенческая сторона класса определяется набором методов.
Объекты и значения могут быть именованными. С именованием объекта или значения связана долговременность его хранения (persistency): любые именованные объекты или значения долговременны; любые объект или значение, входящие как часть в другой именованный объект или значение, долговременны.
С помощью специального указания, задаваемого при определении класса, можно добиться долговременности хранения любого объекта этого класса. В этом случае система автоматически порождает значение-множество, имя которого совпадает с именем класса. В этом множестве гарантированно содержатся все объекты данного класса.
Метод - программный код, привязанный к конкретному классу и применимый к объектам этого класса. Определение метода в O2 производится в два этапа. Сначала объявляется сигнатура метода, т.е. его имя, класс, типы или классы аргументов и тип или класс результата. Методы могут быть публичными (доступными из объектов других классов) или приватными (доступными только внутри данного класса).
На втором этапе определяется реализация класса на одном из языков программирования O2 (подробнее языки обсуждаются в следующем разделе нашего обзора).
В модели O2 поддерживается множественное наследование классов на основе отношения супертип/подтип. В подклассе допускается добавление и/или переопределение атрибутов и методов. Возможные при множественном наследовании двусмысленности (по именованию атрибутов и методов) разрешаются либо путем переименования, либо путем явного указания источника наследования. Объект подкласса является объектом каждого суперкласса, на основе которого порожден данный подкласс.
Поддерживается предопределенный класс "Оbject", являющийся корнем решетки классов; любой другой класс является неявным наследником класса "Object" и наследует предопределенные методы ("is_same", "is_value_equal" и т.д.).
Специфической особенностью модели O2 является возможность объявления дополнительных "исключительных" атрибутов и методов для именованных объектов. Это означает, что конкретный именованный объект-представитель класса может обладать типом, являющимся подтипом типа класса. Конечно, с такими атрибутами не работают стандартные методы класса, но специально для именованного объекта могут быть определены дополнительные (или переопределены стандартные) методы, для которых дополнительные атрибуты уже доступны. Подчеркивается, что дополнительные атрибуты и методы привязываются не к конкретному объекту, а к имени, за которым в разные моменты времени могут стоять вообще говоря разные объекты. Для реализации исключительных атрибутов и методов требуется развитие техники позднего связывания.
В следующем разделе мы среди прочего рассмотрим особенности языков программирования и запросов системы O2, которые, конечно, тесно связаны со спецификой модели данных.
Области применения файлов
После этого краткого экскурса в историю файловых систем рассмотрим возможные области их применения. Прежде всего, конечно, файлы применяются для хранения текстовых данных: документов, текстов программ и т.д. Такие файлы обычно образуются и модифицируются с помощью различных текстовых редакторов. Структура текстовых файлов обычно очень проста: это либо последовательность записей, содержащих строки текста, либо последовательность байтов, среди которых встречаются специальные символы (например, символы конца строки).
Файлы с текстами программ используются как входные тексты компиляторов, которые в свою очередь формируют файлы, содержащие объектные модули. С точки зрения файловой системы, объектные файлы также обладают очень простой структурой - последовательность записей или байтов. Система программирования накладывает на эту структуру более сложную и специфичную для этой системы структуру объектного модуля. Подчеркнем, что логическая структура объектного модуля неизвестна файловой системе, эта структура поддерживается программами системы программирования.
Аналогично обстоит дело с файлами, формируемыми редакторами связей и содержащими образы выполняемых программ. Логическая структура таких файлов остается известной только редактору связей и загрузчику - программе операционной системы. Примерно такая же ситуация с файлами, содержащими графическую и звуковую информацию.
Одним словом, файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам. В перечисленных выше случаях использования файлов это даже хорошо, потому что при разработке любой новой прикладной системы опираясь на простые, стандартные и сравнительно дешевые средства файловой системы можно реализовать те структуры хранения, которые наиболее естественно соответствуют специфике данной прикладной области.
Общая характеристика
Наиболее распространенная трактовка реляционной модели данных, по-видимому, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение. По сути дела, в предыдущих двух разделах этой лекции мы рассматривали именно понятия и свойства структурной составляющей реляционной модели.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД - реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй - на классическом логическом аппарате исчисления предикатов первого порядка. Мы рассмотрим эти механизмы более подробно на следующей лекции, а пока лишь заметим, что основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Общая характеристика языка QUEL. Язык программирования EQUEL
Манипуляционная часть языка QUEL является чистой реализацией реляционного исчисления кортежей. Это означает, что в операторах указываются условия, накладываемые на кортежи, с которыми необходимо произвести соответствующие действия.
Основной набор операторов манипулирования данными включает операторы RETRIVE (выбрать), APPEND (добавить), REPLACE (заменить) и DELETE (удалить). Перед выполнением любого из этих операторов необходимо определить используемые в них переменные кортежей, связав их с соответствующими отношениями путем выполнения оператора RANGE:
RANGE OF variable-list IS relation-name
Продемонстрируем основные свойства операторов QUEL на примерах. Будем использовать базу данных СТУДЕНТЫ и ГРУППЫ:
RANGE OF S IS СТУДЕНТЫ
RANGE OF G IS ГРУППЫ
Пример 1. Выбрать имена студентов, куратором которых является Иванов.
RETRIEVE (S.СТУД_ИМЯ)
WHERE (S.ГРУП_НОМЕР = G.ГРУП_НОМЕР AND
G.КУРАТ_ИМЯ = "ИВАНОВ")
Пример 2. Занести в отношение НЕУСПЕВАЮЩИЕ номера студенческих билетов и имена неуспевающих студентов.
RETRIEVE INTO НЕУСПЕВАЮЩИЕ (S.СТУД_НОМЕР, S.СТУД_ИМЯ)
WHERE (S.СТУД_УСП = "NO")
Пример 3. Вывести фамилии студентов, получающих стипендию ниже средней.
RETRIEVE (S.СТУД_ИМЯ)
WHERE (S.СТУД_СТИП < AVG (S.СТУД_СТИП))
Как и в SQL, поддерживаются агрегатные функции COUNT, SUM, MAX, MIN и AVG.
Пример 4. Включить в группу 310 студента Петрова.
APPEND TO СТУДЕНТЫ (СТУД_ИМЯ = "ПЕТРОВ", ....)
Пример 5. Увеличить стипендию в 1,5 раза всем успевающим студентам.
REPLACE S(СТУД_СТИП BY СТУД_СТИП * 1,5)
WHERE (S.CТУД_УСП = "YES")
Пример 6. Удалить из списка групп все группы, в которых не учится ни один студент.
DELETE G
WHERE (G.ГРУП_РАЗМЕР = 0)
Кроме операторов манипулирования данными, язык QUEL содержит операторы для создания и уничтожения отношений:
CREATE имя_отношения (имя_атрибута IS тип_атрибута, ...)
DESTROY имя_отношения
а также два оператора изменения структур хранимых данных:
MODIFY имя_отношения TO структура_памяти
ON (ключ1, ключ2, ...) и
INDEX ON имя_отношения IS имя_индекса (ключ1, ключ2, ...)
Оператор MODIFY изменяет структуру хранимого отношения в соответствии с параметром структура_памяти и заданным набором ключевых атрибутов. Оператор INDEX создает отдельную индексную структуру для заданных полей данного отношения. Созданные индексы используются системой для оптимизации выполнения операторов манипулирования данными. Согласованность содержимого отношений и индексов поддерживается системой автоматически.
Язык QUEL содержит также операторы определения ограничений целостности, представлений и ограничений доступа. На них мы остановимся немного позже.
В том виде, в каком мы его кратко описали, язык QUEL предназначен для интерактивной работы с базами данных Ingres. Для программирования прикладных информационных систем, которые должны взаимодействовать с базами данных, был разработан язык программирования EQUEL, являющийся, по существу, расширением языка программирования Си путем встраивания в него операторов языка QUEL. Язык EQUEL определяется следующим образом:
Любой оператор языка Си является оператором языка EQUEL.
Любой оператор языка QUEL, которому предшествуют два знака '#', является допустимым оператором языка EQUEL.
Переменные Си-программы могут использоваться в операторах QUEL, заменяя имена отношений, имена атрибутов, элементы списка выборки или константы. Те переменные Си-программы, которые используются таким образом, должны при своем объявлении быть помечены двойным знаком '#'.
Оператор RETRIEVE (без INTO) сопровождается составным оператором языка Си, который выполняется по одному разу для каждого выбранного кортежа.
Пример программы на языке EQUEL, выдающей номер группы по имени студента:
main()
{
## char stud_name[20];
## int group_number;
while (READ(stud_name_)
{
## RANGE OF S IS STUDENTS
## RETRIEVE (group_number = G.GROUP.NUMBER)
## WHERE (S.STUD_NAME = stud_name)
{
PRINT ("The group number of 'stud_name' is 'group_number');
}
}
}
Программа на языке EQUEL обрабатывается специальным препроцессором, который превращает ее в обычную Си-программу, содержащую вызовы Ingres с передачей в качестве параметров текстов операторов языка QUEL. Дальнейшую схему мы уже обсуждали.
Общая интерпретация реляционных операций
Если не вдаваться в некоторые тонкости, которые мы рассмотрим в следующих подразделах, то почти все операции предложенного выше набора обладают очевидной и простой интерпретацией.
При выполнении операции объединения двух отношений производится отношение, включающее все кортежи, входящие хотя бы в одно из отношений-операндов.
Операция пересечения двух отношений производит отношение, включающее все кортежи, входящие в оба отношения-операнда.
Отношение, являющееся разностью двух отношений включает все кортежи, входящие в отношение - первый операнд, такие, что ни один из них не входит в отношение, являющееся вторым операндом.
При выполнении прямого произведения двух отношений производится отношение, кортежи которого являются конкатенацией (сцеплением) кортежей первого и второго операндов.
Результатом ограничения отношения по некоторому условию является отношение, включающее кортежи отношения-операнда, удовлетворяющее этому условию.
При выполнении проекции отношения на заданный набор его атрибутов производится отношение, кортежи которого производятся путем взятия соответствующих значений из кортежей отношения-операнда.
При соединении двух отношений по некоторому условию образуется результирующее отношение, кортежи которого являются конкатенацией кортежей первого и второго отношений и удовлетворяют этому условию.
У операции реляционного деления два операнда - бинарное и унарное отношения. Результирующее отношение состоит из одноатрибутных кортежей, включающих значения первого атрибута кортежей первого операнда таких, что множество значений второго атрибута (при фиксированном значении первого атрибута) совпадает со множеством значений второго операнда.
Операция переименования производит отношение, тело которого совпадает с телом операнда, но имена атрибутов изменены.
Операция присваивания позволяет сохранить результат вычисления реляционного выражения в существующем отношении БД.
Поскольку результатом любой реляционной операции (кроме операции присваивания) является некоторое отношение, можно образовывать реляционные выражения, в которых вместо отношения-операнда некоторой реляционной операции находится вложенное реляционное выражение.
Общая схема обработки запроса
Можно представить, что обработка поступившего в систему запроса состоит из фаз, изображенных ниже.

На первой фазе запрос, заданный на языке запросов, подвергается лексическому и синтаксическому анализу. При этом вырабатывается его внутреннее представление, отражающее структуру запроса и содержащее информацию, которая характеризует объекты базы данных, упомянутые в запросе (отношения, поля и константы). Информация о хранимых в базе данных объектах выбирается из каталогов базы данных. Внутреннее представление запроса используется и преобразуется на следующих стадиях обработки запроса. Форма внутреннего представления должна быть достаточно удобной для последующих оптимизационных преобразований.
На второй фазе запрос во внутреннем представлении подвергается логической оптимизации. Могут применяться различные преобразования, "улучшающие" начальное представление запроса. Среди преобразований могут быть эквивалентные, после проведения которых получается внутреннее представление, семантически эквивалентное начальному (например, приведение запроса к некоторой канонической форме), Преобразования могут быть и семантическими: получаемое представление не является семантически эквивалентным начальному, но гарантируется, что результат выполнения преобразованного запроса совпадает с результатом запроса в начальной форме при соблюдении ограничений целостности, существующих в базе данных. После выполнения второй фазы обработки запроса его внутреннее представление остается непроцедурным, хотя и является в некотором смысле более эффективным, чем начальное.
Третий этап обработки запроса состоит в выборе на основе информации, которой располагает оптимизатор, набора альтернативных процедурных планов выполнения данного запроса в соответствии с его внутреннем представлением, полученным на второй фазе. Для каждого плана оценивается предполагаемая стоимость выполнения запроса. При оценках используется статистическая информация о состоянии базы данных, доступная оптимизатору. Из полученных альтернативных планов выбирается наиболее дешевый, и его внутреннее представление теперь соответствует обрабатываемому запросу.
На четвертом этапе по внутреннему представлению наиболее оптимального плана выполнения запроса формируется выполняемое представление плана. Выполняемое представление плана может быть программой в машинных кодах, если, как в случае System R, система ориентирована на компиляцию запросов в машинные коды, или быть машинно-независимым, но более удобным для интерпретации, если, как в случае INGRES, система ориентирована на интерпретацию запросов. В нашем случае это непринципиально, поскольку четвертая фаза обработки запроса уже не связана с оптимизацией.
Наконец, на пятом этапе обработки запроса происходит его реальное выполнение. Это либо выполнение соответствующей подпрограммы, либо вызов интерпретатора с передачей ему для интерпретации выполняемого плана.
Общий подход к организации представлений, ограничениям целостности и контролю доступа
Мы объединили эти три кажущиеся не очень близкими темы, потому что в Ingres для решения соответствующих проблем применяется единый подход, основанный на модификации операторов SQL. Начнем с представлений. Как и в System R (точнее, в языке SQL), представление базы данных - это некоторый именованный запрос с именованными полями результирующего отношения.
Например, оператор
DEFINE VIEW GROUP310
(STUD_NUMBER = S.STUD_NUMBER,
STUD_NAME = S.STUD_NAME,
STUD_STATUS = S.STUD_STATUS)
WHERE (S.GROUP_NUMBER = 310)
определяет представляемое отношение, включающее номера студенческих билетов и имена студентов из группы 310.
Предположим, что мы хотим теперь найти неуспевающих студентов в отношении GROUP310:
RANGE OF G310 IS GROUP310
RETRIEVE (G310.STUD_NAME)
WHERE (G310.STUD_STATUS = "NO")
Тогда после модификации этот запрос будет выглядеть следующим образом:
RETRIEVE (STUD_NUMBER = S.STUD_NUMBER, STUD_NAME =
S.STUD_NAME, STUD_STATUS = S.STUD_STATUS)
WHERE (S.GROUP_NUMBER = 310 AND
S.STUD_STATUS = "NO")
На тех же самых принципах построен контроль доступа к данным и контроль целостности баз данных. Например, ограничение доступа к отношению СТУДЕНТЫ может быть определено следующим образом:
DEFINE PERMIT RETRIEVE, REPLACE
ON S
TO PETROV
AT TTA5
FROM 9:00 TO 17:50
ON MON TO FRI
WHERE (S.GROUP_NUMBER = 310)
Это означает, что Петрову разрешается читать и модифицировать отношение СТУДЕНТЫ с терминала TTA5 во время от 9 до 15:00 в рабочие дни недели, причем только те кортежи, которые удовлетворяют сформулированному условию. При компиляции любого оператора QUEL над отношением СТУДЕНТЫ этот оператор будет модифицироваться таким образом, чтобы он был выполнен при выполнении условий хотя бы одного из ограничений доступа.
Аналогично, если для отношения СТУДЕНТЫ определено ограничение целостности
DEFINE INTEGRITY
ON S
WHERE (S.STUD_STIP < 150,000)
то к условию любого оператора изменения кортежей отношения СТУДЕНТЫ будет через AND добавляться условия всех ограничений целостности, определенных для этого отношения.
В заключение этой лекции заметим, что конечно, в Ingres поддерживается механизм параллельных транзакций с соответствующей синхронизаций доступа и журнализация изменений баз данных. Однако нам не известны какие-либо особенности применяемых механизмов. На особенностях оптимизации операторов QUEL мы остановимся в лекции, посвященной оптимизациям в языках баз данных.
Оценка стоимости плана запроса
После генерации множества планов выполнения запроса на основе разумных стратегий декомпозиции и эффективных стратегий выполнения элементарных операций нужно выбрать один план, в соответствии с которым будет происходить реальное выполнение запроса. При неверном выборе запрос будет выполнен неэффективно. Прежде всего необходимо определить, что понимается под эффективностью выполнения запроса. Это понятие неоднозначно и зависит от специфики операционной среды СУБД. В одних условиях можно считать, что эффективность выполнения запроса определяется временем его выполнения, т.е. реактивностью системы по отношению к обрабатываемым ею запросам. В других условиях определяющей является общая пропускная способность системы по отношению к смеси параллельно выполняемых запросов. Тогда мерой эффективности запроса можно считать количество системных ресурсов, требуемых для его выполнения и т.д.
Следуя принятой терминологии, мы будем говорить о стоимости плана выполнения запроса, определяемой ресурсами процессора и устройств внешней памяти, которые расходуются при выполнении запроса.
В традиционных реляционных СУБД выделяется подсистема управления доступом к данным на внешней памяти (RSS в System R). Данные на внешней памяти традиционно хранятся в блокированном виде; база данных занимает некоторый набор блоков одного или нескольких дисковых томов. Предполагается, что средства доступа к блокам внешней памяти порождают несравненно меньшие накладные расходы.
Как правило, подсистема управления доступом к данным на внешней памяти осуществляет буферизацию блоков базы данных в оперативной памяти. Каждый блок базы данных, прочитанный в оперативную память для выполнения запроса, сохраняется в одном из буферов буферного пула СУБД, пока не будет вытеснен из него другим блоком базы данных. Эта особенность СУБД существенна для повышения общей эффективности системы, но не учитывается (за исключением частного, но важного случая) при оценках стоимостей планов выполнения запроса. В любом случае компонент стоимости выполнения запроса, связанный с ресурсами устройств внешней памяти, монотонно зависит от числа блоков внешней памяти, доступ к которым потребуется при выполнении запроса.
С другой стороны, число блоков внешней памяти, доступ к которым требуется при выполнении запроса, монотонно зависит от числа кортежей, затрагиваемых запросом.
Из этого следует важность показателя предиката ограничения, характеризующего долю кортежей отношения, которые удовлетворяют данному предикату, и называемого степенью селективности предиката. Степени селективности простых предикатов вида R.C op const, где R.C задает имя поля отношения базы данных, op - операция сравнения (=, !=, >, <, >=, <=), а const - константа, являются основой для оценок стоимости планов запроса. Точность оценок степеней селективности определяет точность общих оценок и правильность выбора оптимального плана запроса.
Степень селективности предиката R.C op const зависит от вида операции сравнения, значения константы и распределения значений поля C отношения R в базе данных. Первые два параметра селективности могут быть известны при проведении оценок, но истинные распределения значений полей отношений, как правило, неизвестны. Существует ряд подходов к приближенным определениям распределений на основе статистической информации. Далее мы рассмотрим наиболее интересные из них.
Если известна степень селективности предиката ограничения отношения, то тем самым известна и мощность результирующего отношения (обычно мощности хранимых отношений известны при обработке запроса). Но в оценочных формулах учитывается необходимое для выполнения запроса число обменов с внешней памятью. Конечно, число кортежей является верхней оценкой требуемого числа обменов, но эта оценка может быть очень завышенной. Все зависит от распределения кортежей по блокам внешней памяти. В ряде случаев можно получить более точную оценку числа блоков.
Наконец, для сложных запросов, включающих, например, соединения более двух отношений, требуется оценивать размеры возникающих в процессе выполнения запроса промежуточных отношений. Чтобы оценить мощность результата соединения двух отношений, вообще говоря, необходимо знать степень селективности предиката соединения по отношению к прямому произведению отношений-операндов.
В общем случае степень селективности такого предиката невозможно определить на основе простой статистической информации. Обычно применяются достаточно грубые эвристические оценки, хотя предлагаются и подходы, обеспечивающие большую точность.
Подход System R базируется на двух основных предположениях о распределениях значений полей отношений: предполагается, что значения полей всех отношений базы данных распределены равномерно и что значения любых двух полей распределены независимо. Первое предположение позволяет оценивать селективность простых предикатов на основе скудной статистической информации о базе данных. На втором предположении основываются оценки числа блоков, в которых располагается известное количество кортежей. Эти два предположения являются предметом критики System R. Они сделаны исключительно в целях упрощения оптимизатора и не могут быть теоретически обоснованы. Можно привести примеры баз данных, для которых эти предположения не оправданы. В этих случаях оценки оптимизатора System R будут неверны.
В каталогах базы данных для каждого отношения R сохраняется число кортежей в данном отношении (T) и число блоков внешней памяти, в которых располагаются кортежи отношения (N); для каждого поля C отношения хранится число различных значений этого поля (CD), минимальное хранимое значение этого поля (CMin) и максимальное значение (CMax).
При наличии такой информации с учетом первого базового предположения степени селективности простых предикатов вычисляется просто (и точно, если распределение на самом деле равномерно). Пусть SEL (P) - степень селективности предиката P.
Тогда
SEL (R.C = const) = CD / (CMax - CMin)
(при равномерном распределении степень селективности такого предиката не зависит от значения константы).
SEL (R.C > const) = (CMax - const) / (CMax - CMin)
и т.д.
При оценках числа блоков, в которых могут располагаться кортежи, удовлетворяющие предикату R.C op const, различаются случаи кластеризованности или некластеризованности отношения по полю C.
Эти оценки имеют смысл только при рассмотрении варианта сканирования отношения с использованием индекса на поле C. При просмотре отношения без использования индекса понадобится всегда обратиться ровно к N блокам внешней памяти.
Предположения о равномерности распределений значений атрибутов отношений позволяют достаточно просто оценивать и мощности отношений, являющихся результатами двухместных реляционных и теоретико-множественных операций над отношениями.
Оценки селективности предикатов используются и для оценки затрат ресурсов процессора. Предполагается, что основная часть процессорной обработки производится в RSS. Поэтому процессорные затраты измеряются числом обращений к RSS, которое соответствует числу кортежей, получаемых при сканировании хранимого или временного отношения, т.е. селективностью логического выражения, состоящего из простых предикатов (условие выборки уровня RSS). Предположения о равномерности и независимости значений разных полей отношения позволяют легко оценить селективность логического выражения, составленного из простых предикатов, при известных их степенях селективности.
На самом деле в System R не оценивается селективность предикатов в чистом виде. Оценки оптимизатора основываются на фиксированном наборе элементарных оценочных формул, опирающихся на статистическую информацию о базе данных. Каждая формула соответствует некоторому элементарному действию системы; выполнение любого запроса состоит в комбинации некоторых элементарных действий. Примерами элементарных действий могут быть выполнение ограничения отношения путем его сканирования через кластеризованный индекс, сортировка отношения, соединение двух ранее отсортированных отношений и т.д. Общая оценка плана выполнения запроса производится в итерационном процессе, начиная с оценок элементарных операций над хранимыми отношениями.
Одиночные операторы манипулирования данными
Каждый из операторов этой группы является абсолютно независимым от какого бы то ни было другого оператора.
Оператор выборки
Для удобства мы повторяем синтаксис этого оператора еще раз:
<select statement> ::=
SELECT [ALL | DISTINCT] <select name>
INTO <select target list> <table expression>
<select target list>::=
<target specification>
[{,<target specification>}...]
Поскольку, как мы уже объясняли, результатом одиночного оператора выборки является таблица, состоящая не более, чем из одной строки, список целей специфицируется в самом операторе.
Оператор поискового удаления
Оператор описывается следующим синтаксическим правилом:
<delete statement: searched> ::=
DELETE FROM <table name>
WHERE [<search condition>]
Таблица T, указанная в разделе FROM оператора DELETE, должна быть изменяемой. На условие поиска накладывается то условие, что на таблицу T не должны содержаться ссылки ни в каком вложенном подзапросе предикатов раздела WHERE.
Фактически оператор выполняется следующим образом: последовательно просматриваются все строки таблицы T, и те строки, для которых результатом вычисления условия выборки является true, удаляются из таблицы T. При отсутствии раздела WHERE удаляются все строки таблицы T.
Оператор поисковой модификации
Оператор обладает следующим синтаксисом:
<update statement: searched> ::=
UPDATE <table name>
SET <set clause: searched>
[{,<set clause: searched>}...]
[WHERE <search conditions>]
<set clause: searched> ::=
<object column: searched> =
{ <value expression> | NULL }
<object column: searched> ::= <column name>
Таблица T, указанная в операторе UPDATE, должна быть изменяемой. На условие поиска накладывается то условие, что на таблицу T не должны содержаться ссылки ни в каком вложенном подзапросе предикатов раздела WHERE.
Оператор фактически выполняется следующим образом: таблица T последовательно просматривается, и каждая строка, для которой результатом вычисления условия поиска является true, изменяется в соответствии с разделом SET. Если арифметическое выражение в разделе SET содержит ссылки на столбцы таблицы T, то при вычислении арифметического выражения используются значения столбцов текущей строки до их модификации.
Операторы окончания транзакции
Текущая транзакция может быть завершена успешно (с фиксацией в базе данных произведенных изменений) путем выполнения оператора COMMIT WORK или аварийно (с удалением из базы данных изменений, произведенных текущей транзакцией) путем выполнения оператора ROLLBACK WORK. При выполнении любого из этих операторов производится принудительное закрытие всех курсоров, открытых к моменту выполнения оператора завершения транзакции.
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается (примером такой "внешней" ссылки может быть содержимое поля Каф_Номер в экземпляре типа записи Куратор).
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия

Ограничения целостности
В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели).
Оператор чтения строки по курсору, связанному с динамически подготовленным оператором выборки
<dynamic fetch statement> ::=
FETCH [[<fetch orientation>] FROM]
<dynamic cursor name> <using clause>
Комментарий:
По сути, оператор чтения по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только возможным наличием раздела using, в котором задается размещение значений текущей строки результирующей таблицы. Кроме того, имя курсора может задаваться через переменную.
Оператор объявления курсора над динамически подготовленным оператором выборки
<dynamic declare cursor> ::=
DECLARE <cursor name> [INSENSITIVE] [SCROLL]
CURSOR FOR <statement name>
Комментарий:
Как определяется в новом стандарте, для всех операторов DECLARE CURSOR, курсоры фактически создаются при начале транзакции и уничтожаются при ее завершении. Заметим, что в этом операторе <cursor name> и <statement name> - прямо заданные идентификаторы.
Оператор определения курсора над динамически подготовленным оператором выборки
<allocate cursor statement> ::=
ALLOCATE <extended cursor name> [INSENSITIVE] [SCROLL]
CURSOR FOR <extended statement name>
<extended cursor name> ::=
(<scope option>] <simple value specification>
Комментарий:
Курсоры, определяемые с помощью оператора ALLOCATE CURSOR, фактически создаются при выполнении такого оператора и уничтожаются при выполнении оператора DEALLOCATE PREPARE или при завершении транзакции. В этом операторе имена курсора и подготовленного оператора SQL могут задаваться не только в литеральной форме, но и через переменные.
<scope option> относится к области видимости имен: в пределах текущего модуля или в пределах текущей сессии.
Оператор определения схемы
В соответствии с правилами SQL/89 каждая таблица данной БД имеет простое и квалифицированное имена. В качестве квалификатора имени выступает "идентификатор полномочий" таблицы, который обычно в реализациях совпадает с именем некоторого пользователя, и квалифицированное имя таблицы имеет вид:
<идентификатор полномочий>.<простое имя>
Подход к определению схемы в SQL/89 состоит в том, что все таблицы с одним идентификатором полномочий создаются (определяются) путем выполнения одного оператора определения схемы. При этом в стандарте не определяется способ выполнения оператора определения схемы: должен ли он выполняться только в интерактивном режиме или может быть встроен в программу, написанную на традиционном языке программирования.
В операторе определения схемы содержится идентификатор полномочий и список элементов схемы, каждый из которых может быть определением таблицы, определением представления (view) или определением привилегий. Каждое из этих определений представляется отдельным оператором SQL/89, но все они, как уже говорилось, должны быть встроены в оператор определения схемы.
Для этих операторов мы приведем синтаксис, поскольку это позволит более четко описать их особенности.
Оператор освобождения памяти из-под дескриптора
<deallocate descriptor statement> ::=
DEALLOCATE DESCRIPTOR <descriptor name>
Комментарий:
Выполнение этого оператора приводит к освобождению памяти из-под ранее выделенного дескриптора. После этого использование имени дескриптора незаконно в любом операторе, кроме ALLOCATE DESCRIPTOR.
Оператор отказа от подготовленного оператора
<deallocate prepared statement> ::=
DEALLOCATE PREPARE <SQL statement name>
Комментарий:
Выполнение этого оператора приводит к тому, что ранее подготовленный оператор SQL, связанный с указанным именем оператора, ликвидируется, и, соответственно, имя оператора становится неопределенным. Если подготовленный оператор являлся оператором выборки, и к моменту выполнения оператора DEALLOCATE существовал открытый курсор, связанный с именем подготовленного оператора, то оператор DEALLOCATE возвращает код ошибки. Если же для подготовленного оператора выборки существовал неоткрытый курсор, образованный с помощью оператора ALLOCATE CURSOR, то этот курсор ликвидируется. Если курсор объявлялся оператором DECLARE CURSOR, то такой курсор переходит в состояние, существовавшее до выполнения оператора PREPARE. Если с курсором был связан подготовленный оператор (динамический DELETE или UPDATE), то для этих операторов выполняется неявный оператор DEALLOCATE.
Оператор открытия курсора, связанного с динамически подготовленным оператором выборки
<dynamic open statement> ::=
OPEN <dynamic cursor name> [<using clause>]
Комментарий:
По сути, оператор открытия курсора, связанного с динамически подготовленным оператором SQL, отличается от статического случая только возможным наличием раздела using, в котором задаются фактические параметры оператора выборки. Кроме того, имя курсора может задаваться через переменную.
Оператор подготовки
Оператор PREPARE имеет синтаксис:
<prepare-statement> ::=
PREPARE <statement-name> FROM <host-string-variable>
<statement-name> ::= <name>
Во время выполнения оператора PREPARE символьная строка, содержащаяся в host-string-variable, передается компилятору SQL, который обрабатывает ее почти таким же образом, как если бы получил в статике. Построенный при выполнении оператора PREPARE код остается действующим до конца транзакции или до повторного выполнения данного оператора PREPARE в пределах этой же транзакции.
В отличие от статически подставляемых в программу на обычном языке программирования операторов SQL, в которых связь с переменными включающей программы производится по именам (т.е. в соответствии со стандартом во встроенном операторе SQL могут употребляться просто имена переменных включающей программы), динамическая природа операторов, подготавливаемых с помощью оператора PREPARE, заставляет рассматривать эти имена как имена формальных параметров. Соответствие этих формальных параметров адресам переменных включающей программы устанавливается позиционно во время выполнения подготовленного оператора.
Оператор подготовки
<prepare statement> ::=
PREPARE <SQL statement name>
FROM <SQL statement variable>
<SQL statement variable> ::= <simple target specification>
<preparable statement> ::=
<preparable SQL data statement>
| <preparable SQL schema statement>
| <preparable SQL transaction statement>
| <preparable SQL session statement>
| <preparable implementation-defined statement>
<preparable SQL data statement> ::=
<delete statement: searched>
| <dynamic single row select statement>
| <insert statement>
| <dynamic select statement>
| <update statement: searched>
| <preparable dynamic delete statement: positioned>
| <preparable dynamic update statement: positioned>
<preparable SQL schema statement> ::= <SQL schema statement>
<preparable SQL transaction statement> ::= <SQL transaction statement>
<preparable SQL session statement> ::= <SQL session statement>
<dynamic select statement> ::= <cursor specification>
<dynamic simple row select statement> ::= <query specification>
<SQL statement name> ::= <statement name> | <extended statement name>
<extended statement name> ::= [scope option] <simple value specification>
<cursor specification> ::=
<query expression> [<order by clause>]
[<updatability clause>]
<updatability clause> ::=
FOR { READ ONLY | UPDATE [ OF <column name list> ] }
<query expression> ::=
<non-join query expression>
| <joined table>
<query specification> ::=
SELECT [<set quantifier>]
<select list> <table expression>
<set quantifier> ::= DISTINCT | ALL
Комментарий:
Оператор PREPARE вызывает компиляцию и построение плана выполнения заданного в текстовой форме оператора SQL. После успешного выполнения оператора PREPARE с подготовленным оператором связывается указанное (литерально или косвенно) имя этого оператора, которое потом может быть использовано в операторах DESCRIBE, EXECUTE, OPEN CURSOR, ALLOCATE CURSOR и DEALLOCATE PREPARE. Эта связь сохраняется до явного выполнения оператора DEALLOCATE PREPARE.
Оператор подготовки с немедленным выполнением
<execute immediate statement> ::=
EXECUTE IMMEDIATE <SQL statement variable>
Комментарий:
При выполнении оператора EXECUTE IMMEDIATE производится подготовка и немедленное выполнение заданного в текстовой форме оператора SQL. При этом подготавливаемый оператор не должен быть оператором выборки, не должен содержать формальных параметров и комментариев.
Оператор получения информации из области дескриптора SQL
<get descriptor statement> ::=
GET DESCRIPTOR <descriptor name>
<get descriptor information>
<get descriptor information> ::=
<get count>
( VALUE <item number>
<get item information>
({<comma> <get item information>}...]
<get count> ::=
<simple target specification 1>
<equals operator> COUNT
<get item information> ::=
<simple target specification 2>
<equals operator>
<descriptor item name>
<item number> ::= <simple value specification>
<simple target specification 1> ::= <simple target specification>
<simple target specification 2> ::= <simple target specification>
<descriptor item name> ::=
TYPE
( LENGHT
( OCTET_LENGHT
( RETURNED_LENGHT
( RETURNED_OCTET_LENGHT
( PRECISION
( SCALE
( DATETIME_INTERVAL_CODE
( DATATIME_INTERVAL_PRECISION
( NULLABLE
( INDICATOR
( DATA
( NAME
( UNNAMED
( COLLATION_CATALOG
( COLLATION_SCHEMA
( COLLATION_NAME
( CHARACTER_SET_CATALOG
( CHARACTER_SET_SCHEMA
( CHARACTER_SET_NAME
<simple target specification> ::=
<parameter name>
( <embedded variable name>
Комментарий:
Оператор GET DESCRIPTOR служит для выборки описательной информации, ранее размещенной в дескрипторе с помощью оператора DESCRIBE. За одно выполнение оператора можно получить либо число заполненных элементов дескриптора (COUNT), либо информацию, содержащуюся в одном из заполненных элементов.
Оператор получения описания подготовленного оператора
Оператор DESCRIBE предназначен для того, чтобы определить тип ранее подготовленного оператора, узнать количество и типы формальных параметров (если они есть) и количество и типы столбцов результирующей таблицы, если подготовленный оператор является оператором выборки (SELECT).
Действие оператора DESСRIBE состоит в том, что в указанную область памяти прикладной программы (структура этой области фиксирована и известна пользователям) помещается информация, характеризующая ранее подготовленный оператор с заданным именем.
Оператор позиционного удаления
<dynamic delete statement: positioned> ::=
DELETE FROM <table name>
WHERE CURRENT OF <dynamic cursor name>
Комментарий:
По сути, оператор позиционного удаления по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только тем, что имя курсора может задаваться через переменную.
Оператор позиционной модификации
<dynamic update statement: positioned> ::=
UPDATE <table name>
SET <set clause> [{<comma> <set clause>}...]
WHERE CURRENT OF <dynamic cursor name>
Комментарий:
По сути, оператор позиционной модификации по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только тем, что имя курсора может задаваться через переменную.
Оператор установки дескриптора
<set descriptor statement> ::=
SET DESCRIPTOR <descriptor name>
<set descriptor information>
<set descriptor information> ::=
<set count>
( VALUE <item number> <set item information>
[{<comma> <set item information>}...]
<set count> ::= COUNT <equals operator> <simple value specification 1>
<set item information> ::=
<descriptor item name>
<equals operator>
<simple value specification 2>
<simple target specification 1> ::= <simple target specification>
<simple target specification 2> ::=<simple target specification>
<item number> ::= <simple value specification>
Комментарий:
Оператор SET DESCRIPTOR служит для заполнения элементов дескриптора с целью его использования в разделе USING. За одно выполнение оператора можно поместить значение в поле COUNT (число заполненных элементов), либо частично или полностью сформировать один элемент дескриптора.
Оператор выборки
Оператор выборки - это отдельный оператор языка SQL/89, позволяющий получить результат запроса в прикладной программе без привлечения курсора. Поэтому оператор выборки имеет синтаксис, отличающийся от синтаксиса спецификации курсора, и при его выполнении возникают ограничения на результат табличного выражения. Фактически, и то, и другое диктуется спецификой оператора выборки как одиночного оператора SQL: при его выполнении результат должен быть помещен в переменные прикладной программы. Поэтому в операторе появляется раздел INTO, содержащий список переменных прикладной программы, и возникает то ограничение, что результирующая таблица должна содержать не более одной строки. Соответственно, результат базового табличного выражения должен содержать не более одной строки, если оператор выборки не содержит спецификации DISTINCT, и таблица, полученная применением списка выборки к результату табличного выражения, не должна содержать более одной несовпадающих строк, если спецификация DISTINCT задана.
Замечание: В диалекте SQL СУБД Oracle поддерживается расширенный вариант оператора выборки, результатом которого не обязательно является таблица из одной строки. Такое расширение не поддерживается ни в SQL/89, ни в SQL/92.
Оператор выделения памяти под дескриптор
<allocate descriptor statement> ::=
ALLOCATE DESCRIPTOR <descriptor name>
[WITH MAX <occurrences>]
<occurences> ::= <simple value specification>
<descriptor name> ::=
(<scope option>] <simple value specification>
<scope option> ::= GLOBAL | LOCAL
<simple value specification> ::=
<parameter name>
(<embedded variable name>
(<literal>
Комментарий:
Дескриптор, это динамически выделяемая часть памяти прикладной программы, служащая для принятия информации о результате или параметрах динамически подготовленного оператора SQL или задания параметров такого оператора. Смысл того, что для выделения памяти используется оператор SQL, а не просто стандартная функция alloc или какая-нибудь другая функция динамического запроса памяти, состоит в том, что прикладная программа не знает структуры дескриптора и даже его адреса. Это позволяет не привязывать SQL к особенностям какой-либо системы программирования или ОС. Все обмены информацией между собственно прикладной программой и дескрипторами производятся также с помощью специальных операторов SQL (GET и SET, см. ниже).
Второй вопрос: зачем вообще выделять память под дескрипторы динамически. Это нужно потому, что в общем случае прикладная программа, использующая динамический SQL, не знает в статике число одновременно действующих динамических операторов SQL, описание которых может потребоваться. С этим же связано то, что имя дескриптора может задаваться как литеральной строкой символов, так и через строковую переменную включающего языка, т.е. его можно генерировать во время выполнения программы.
В операторе ALLOCATE DESCRIPTOR, помимо прочего, может указываться число описательных элементов, на которое он рассчитан. Если, например, при выделении памяти под дескриптор в разделе WITH MAX указано целое положительное число N, а потом дескриптор используется для описания M (M>N) элементов (например, M столбцов результата запроса), то это приводит к возникновению исключительной ситуации.
Оператор выполнения подготовленного оператора
Оператор EXECUTE служит для выполнения ранее подготовленного оператора SQL типа 'N' (не требующего применения курсора) или для совмещенной подготовки и выполнения такого оператора. Синтаксис оператора EXECUTE:
<execute-statement> ::=
EXECUTE
{<statement-name> [USING <host-vars-list>]
( IMMEDIATE <host-string-variable> }
Для выполнения подготовленного оператора служит первый вариант оператора EXECUTE. В этом случае <statement-name> должен задавать имя, употреблявшееся ранее в операторе PREPARE. Если в подготовленном операторе присутствуют формальные параметры, то в операторе EXECUTE должен задаваться список фактических параметров <host-vars-list>. Число и типы фактических параметров должны соответствовать числу и типам формальных параметров подготовленного оператора.
Второй вариант оператора EXECUTE предназначен в Oracle для совмещенной подготовки и выполнения оператора SQL типа 'N'. В этом случае параметром оператора EXECUTE является строка, которая должна содержать текст оператора SQL (эту строку разрешается также задавать литерально). Запрещается использование в этом операторе переменных включающей программы (формальных параметров).
Оператор выполнения подготовленного оператора
<execute statement> ::=
EXECUTE <SQL statement name>
(<result using clause>]
(<parameter using clause>]
<result using clause> ::= <using clause>
<parameter using clause> ::= <using clause>
Комментарий:
Оператор EXECUTE может быть применен к любому ранее подготовленному оператору SQL, кроме <dynamic select statement>. Если это оператор <dynamic single row select statement>, то оператор EXECUTE должен содержать раздел <result using class> с ключевым словом INTO. В любом случае число фактических параметров, задаваемых через разделы using, должно соответствовать числу формальных параметров, определенных в подготовленном операторе SQL.
Оператор закрытия курсора, связанного с динамически подготовленным оператором выборки
<dynamic close statement> ::=
CLOSE <dynamic cursor name>
Комментарий:
По сути, оператор закрытия курсора, связанного с динамически подготовленным оператором SQL, отличается от статического случая только тем, что имя курсора может задаваться через переменную.
Оператор запроса описания подготовленного оператора
<describe statement> ::=
<describe input statement>
| <describe output statement>
<describe input statement> ::=
DESCRIBE INPUT <SQL statement name> <using descriptor>
<describe output statement> ::=
DESCRIBE [OUTPUT] <SQL statement name> <using descriptor>
<using clause> ::= <using arguments> | <using descriptor>
<using arguments> ::=
{ USING | INTO } <argument> [{<comma> <argument>}...]
<argument> ::= <target specification>
<using descriptor> ::=
{ USING | INTO } SQL DESCRIPTOR <descriptor name>
<target specification> ::=
<parameter specification>
| <variable specification>
<parameter specification> ::=
<parameter name> [<indicator parameter>]
<indicator parameter> ::= [INDICATOR] <parameter name>
<variable specification> ::=
<embedded variable name> [<indicator variable>]
<indicator variable> ::= [INDICATOR] <embedded variable name>
Комментарий:
При выполнении оператора DESCRIBE происходит заполнение указанного в операторе дескриптора информацией, описывающей либо результат ранее подготовленного оператора SQL (если это оператор выборки), либо количество и типы параметров подготовленного оператора. В <using descriptor> здесь полагается писать USING SQL DESCRIPTOR.
Операторы определения и манипулирования схемой БД
В число операторов определения схемы БД SQL System R входили операторы создания и уничтожения постоянных и временных хранимых отношений (CREATE TABLE и DROP TABLE) и создания и уничтожения представляемых отношений (CREATE VIEW и DROP VIEW). В языке и в реализации System R не запрещалось использовать операторы определения схемы в пределах транзакции, содержащей операторы выборки и манипулирования данными. Допускалось, например, использование операторов выборки и манипулирования данными, в которых указываются отношения, не существующие в БД к моменту компиляции оператора. Конечно, эта возможность существенно усложняла реализацию и требовалась по существу очень редко.
Оператор манипулирования схемой БД ALTER TABLE позволял добавлять указываемые поля к существующим отношениям. В описании языка определялось, что выполнение этого оператора не должно приводить к недействительности ранее откомпилированных операторов над отношением, схема которого изменяется, и что значения вновь определенных полей в существующих кортежах отношения становятся неопределенными.
Операторы, связанные с курсором
Операторы этой группы объединяет то, что все они работают с некоторым курсором, объявление которого должно содержаться в том же модуле или программе со встроенным SQL.
Оператор объявления курсора
Для удобства мы повторим здесь синтаксические правила объявления курсора, приводившиеся раньше:
<declare cursor> ::=
DECLARE <cursor name> CURSOR FOR <cursor specification>
<cursor specification> ::=
<query expression> [<order by clause>...]
<query expression> ::=
<query term>
| <query expression> UNION [ALL] <query term>
<query term> ::= <query specification> | (<query expression>)
<order by clause> ::=
ORDER BY <sort specification>
[{,<sort specification>}...]
<sort specification> ::=
{ <unsigned integer> | <column specification> }
[ASC | DESC]
В объявлении курсора могут задаваться запросы наиболее общего вида с возможностью выполнения операции UNION и сортировкой конечного результата. Этот оператор не является выполняемым, он только связывает имя курсора со спецификацией курсора.
Оператор открытия курсора
Оператор описывается следующим синтаксическим правилом:
<open statement> ::= OPEN <cursor name>
В реализациях встроенного SQL обычно требуется, чтобы объявление курсора текстуально предшествовало оператору открытия курсора. Оператор открытия курсора должен быть первым в серии выполняемых операторов, связанных с заданным курсором. При выполнении этого оператора производится подготовка курсора к работе над ним. В частности, в этот момент производится связывание спецификации курсора со значениями переменных основного языка в случае встроенного SQL или параметров в случае модуля.
В большинстве реализаций в случае встроенного SQL именно выполнение оператора открытия курсора приводит к компиляции спецификации курсора.
Следующие операторы можно выполнять в произвольном порядке над открытым курсором.
Оператор чтения очередной строки курсора
Синтаксис оператора чтения следующий:
<fetch statement> ::=
FETCH <cursor name> INTO <fetch target list>
<fetch target list> ::=
<target specification>[{,<target specification>}...]
В операторе чтения указывается имя курсора и обязательный раздел INTO, содержащий список спецификаций назначения (список имен переменных основной программы в случае встроенного SQL или имен "выходных" параметров в случае модуля SQL). Число и типы данных в списке назначений должны совпадать с числом и типами данных списка выборки спецификации курсора.
Любой открытый курсор всегда имеет позицию: он может быть установлен перед некоторой строкой результирующей таблицы (перед первой строкой сразу после открытия курсора), на некоторую строку результата или за последней строкой результата.
Если таблица, на которую указывает курсор, является пустой, или курсор позиционирован на последнюю строку или за ней, то при выполнении оператора чтения курсор устанавливается в позицию после последней строки, параметру SQLCODE присваивается значение 100, никакие значения не присваиваются целям, идентифицированным в разделе INTO.
Если курсор установлен в позицию перед строкой, то он устанавливается на эту строку, и значения этой строки присваиваются соответствующим целям.
Если курсор установлен на строку r, отличную от последней строки, то курсор устанавливается на строку, непосредственно следующую за строкой r, и значения из этой следующей строки присваиваются соответствующим целям.
Возникает естественный вопрос, каким образом можно параметризовать курсор неопределенным значением или узнать, что выбранное из очередной строки значение является неопределенным. В SQL/89 это достигается за счет использования так называемых индикаторных параметров и переменных. Если известно, что значение, передаваемое из основной программы СУБД или принимаемое основной программой от СУБД, может быть неопределенным, и этот факт интересует прикладного программиста, то спецификация параметра или переменной в операторе SQL имеет вид: <parameter name>[INDICATOR]<parameter name> при спецификации параметра, и <embedded variable name>[INDICATOR]<embedded variable name> при спецификации переменной.
Отрицательное значение индикаторного параметра или индикаторной переменной (они должны быть целого типа) соответствует неопределенному значению параметра или переменной.
Оператор позиционного удаления
Синтаксис этого оператора следующий:
<delete statement: positioned> ::=
DELETE FROM <table name>
WHERE CURRENT OF <cursor name>
Если указанный в операторе курсор открыт и установлен на некоторую строку, и курсор определяет изменяемую таблицу, то текущая строка курсора удаляется, а он позиционируется перед следующей строкой. Таблица, указанная в разделе FROM оператора DELETE, должна быть таблицей, указанной в самом внешнем разделе FROM спецификации курсора.
Оператор позиционной модификации
Оператор описывается следующими синтаксическими правилами:
<update statement: positioned> ::=
UPDATE <table name>
SET <set clause:positioned>
[{,<set clause:positioned>}...]
WHERE CURRENT OF <cursor name>
<set clause: positioned> ::=
<object column:positioned> =
{ <value expression> | NULL }
<object column: positioned> ::= <column name>
Если указанный в операторе курсор открыт и установлен на некоторую строку, и курсор определяет изменяемую таблицу, то текущая строка курсора модифицируется в соответствии с разделом SET. Позиция курсора не изменяется. Таблица, указанная в разделе FROM оператора DELETE, должна быть таблицей, указанной в самом внешнем разделе FROM спецификации курсора.
Оператор закрытия курсора
Синтаксис этого оператора следующий:
<close statement> ::= CLOSE <cursor name>
Если к моменту выполнения этого оператора курсор находился в открытом состоянии, то оператор переводит курсор в закрытое состояние. После этого над курсором возможно выполнение только оператора OPEN.
Определение ограничений целостности таблицы
Ограничения целостности таблицы обладают следующим синтаксисом:
<table constraint definition> ::=
<unique constraint definition>
| <referential constraint definition>
| <check constraint definition>
<unique constraint definition> ::=
<unique specification> (<unique column list>)
<unique specification> ::= UNIQUE | PRIMARY KEY
<unique column list> ::= <column name> [{,<column name>}...]
<referential constraint definition> ::=
FOREIGN KEY (<referencing columns>) <references specification>
<references specification> ::=
REFERENCES <referenced table and columns>
<referencing columns> ::= <reference column list>
<referenced table and columns> ::=
<table name> [(<reference column list>)]
<reference column list> ::= <column name> [{,<column name>}...]
<check constraint definition> ::= CHECK (<search condition>)
Для одной таблицы может быть задано несколько ограничений целостности, в том числе те, которые неявно порождаются ограничениями целостности столбцов. Стандарт SQL/89 устанавливает, что ограничения таблицы фактически проверяются при выполнении каждого оператора SQL.
Замечание: Наличие правильно подобранного набора ограничений БД очень важно для надежного функционирования прикладной информационной системы. Вместе с тем, в некоторых СУБД ограничения целостности практически не поддерживаются. Поэтому при проектировании прикладной системы необходимо принять решение о том, что более существенно: рассчитывать на поддержку ограничений целостности, но ограничить набор возможных СУБД, или отказаться от их использования на уровне SQL, сохранив возможность использования не самых современных СУБД.
Далее T обозначает таблицу, для которой определяются ограничения целостности.
Ограничение уникальности
Каждое имя столбца в списке уникальности должно именовать столбец T и не должно входить в этот список более одного раза.
в список уникальности, должно быть
При определении столбца, входящего в список уникальности, должно быть указано ограничение столбца NO NULL. Среди ограничений уникальности T не должно быть более одного определения первичного ключа (ограничения уникальности с ключевым словом RIMARY KEY).
Действие ограничения уникальности состоит в том, что в таблице T не допускается появление двух или более строк, значения столбцов уникальности которых совпадают.
Ограничение по ссылкам
Ограничение по ссылкам от заданного набора столбцов CT таблицы T на заданный набор столбцов CT1 некоторой определенной к этому моменту таблицы T1 определяет условие на содержимое обеих этих таблиц, при котором ссылки можно считать корректными.
Если список столбцов CT1 явно специфицирован в определении ограничения по ссылкам, то требуется, чтобы этот список явно входил в какое-либо определение уникальности таблицы T1. Если же список CT1 не специфицирован явно в определении ограничения по ссылкам таблицы T, то требуется, чтобы в определении таблицы T1 присутствовало определение первичного ключа, и список CT1 неявно полагается совпадающим со списком имен столбцов из определения первичного ключа таблицы T1. Имена столбцов списков CT и CT1 должны именовать столбцы таблиц T и T1 соответственно, и не должны появляться в списках более одного раза. Списки столбцов CT и CT1 должны содержать одинаковое число элементов, и столбец таблицы T, идентифицируемый i-ым элементом списка CT должен иметь тот же тип, что столбец таблицы T1, идентифицируемый i-ым элементом списка CT1.
По определению, таблицы T и T1 удовлетворяют заданному ограничению по ссылкам, если для каждой строки s таблицы T такой, что все значения столбцов s, идентифицируемых списком CT, не являются неопределенными, существует строка s1 таблицы T1 такая, что значения столбцов s1, идентифицируемых списком CT1, позиционно равны значениям столбцов s, идентифицируемых списком CT. По человечески это можно сформулировать так: ограничение по ссылкам удовлетворяется, если для каждой корректной ссылки существует объект, на который она ссылается.В привычной программистам терминологии, ограничение по ссылкам не позволяет производить "висячие" ссылки, не ведущие ни к какому объекту.
Проверочное ограничение
Проверочное ограничение специфицирует условие, которому должна удовлетворять в отдельности каждая строка таблицы T. Это условие не должно содержать подзапросов, спецификаций агрегатных функций, а также ссылок на внешние переменные или параметров. В него могут входить только имена столбцов данной таблицы и литеральные константы.
Таблица удовлетворяет проверочному ограничению целостности в том и только в том случае, когда вычисление условия для каждой строки таблицы дает true.
Замечание: В некоторых реализациях допускаются расширенные механизмы ограничений по ссылкам и проверочных ограничений. Следует быть внимательным, если не желать выходить за пределы возможностей стандарта.
Определение представлений
Механизм представлений (view) является мощным средством языка SQL, позволяющим скрыть реальную структуру БД от некоторых пользователей за счет определения представления БД, которое реально является некоторым хранимым в БД запросом с именованными столбцами, а для пользователя ничем не отличается от базовой таблицы БД (с учетом технических ограничений). Любая реализация должна гарантировать, что состояние представляемой таблицы точно соответствует состоянию базовых таблиц, на которых определено представление. Обычно вычисление представляемой таблицы (материализация соответствующего запроса) производится каждый раз при использовании представления.
В стандарте SQL/89 оператор определения представления имеет следующий синтаксис:
<view definition> ::=
CREATE VIEW <table name> [(<view column list>)]
AS <query specification> [WITH CHECK OPTION]
<view column list> ::= <column name> [{,<column name>}...]
Определяемая представляемая таблица V является изменяемой (т.е. по отношению к V можно использовать операторы DELETE и UPDATE) в том и только в том случае, если выполняются следующие условия для спецификации запроса:
В списке выборки не указано ключевое слово DISTINCT;
Каждое арифметическое выражение в списке выборки представляет собой одну спецификацию столбца, и спецификация одного столбца не появляется более одного раза;
В разделе FROM указана только одна таблица, являющаяся либо базовой таблицей, либо изменяемой представляемой таблицей;
В условии выборки раздела WHERE не используются подзапросы;
В табличном выражении отсутствуют разделы GROUP BY и HAVING.
Замечание: Эти ограничения являются очень сильными. В реализациях они могут быть ослаблены. Но если стремиться к мобильности, не следует пользоваться расширенными возможностями.
Если в списке выборки спецификации запроса имеется хотя бы одно арифметическое выражение, состоящее не из одной спецификации столбца, или если одно имя столбца участвует в списке выборки более одного раза, определение представления должно содержать список имен столбцов представляемой таблицы. Более просто, нужно явно именовать столбцы представляемой таблицы, если эти имена не наследуются от столбцов таблиц раздела FROM спецификации запроса.
Требование WITH CHECK OPTION в определении представления имеет смысл только в случае определения изменяемой представляемой таблицы, которая определяется спецификацией запроса, содержащей раздел WHERE. При наличии этого требования не допускаются изменения представляемой таблицы, которые приводят к появлению в базовых таблиц строк, не видимых в представляемой таблице (т.е. таких строк, которые не удовлетворяют условию поиска раздела WHERE спецификации запроса). Если WITH CHECK OPTION в определении представления отсутствует, такой контроль не производится.
Определение привилегий
В соответствии с идеологией языка SQL контроль прав доступа данного пользователя к таблицам БД производится на основе механизма привилегий. Фактически, этот механизм состоит в том, что для выполнения любого действия над таблицей пользователь должен обладать соответствующей привилегией (реально все возможные действия описываются фиксированным стандартным набором привилегий). Пользователь, создавший таблицу, автоматически становится владельцем всех возможных привилегий на выполнение операций над этой таблицей. В число этих привилегий входит привилегия на передачу всех или некоторых привилегий по отношению к данной таблице другому пользователю, включая привилегию на передачу привилегий. Иногда поддерживается и обратная операция изъятия привилегий от пользователя, ранее их получившего.
В SQL/89 определяется упрощенная схема механизма привилегий. Во-первых, "раздача" привилегий возможна только при определении таблицы. Во-вторых, пользователь, получивший некоторые привилегии от других пользователей, может передать их дальше только при определении схемы.
Определение привилегий производится в следующем синтаксисе:
<privilege definition> ::=
GRANT <privileges> ON <table name> TO <grantee>
[{,<grantee>}...] [WITH GRANT OPTION]
<privileges> ::=
ALL PRIVILEGES
| <action> [{,<action>}...]
<action> ::= SELECT | INSERT | DELETE
| UPDATE [(<grant column list>)]
| REFERENCES [(<grant column list>]
<grant column list> ::= <column name> [{,<column name>}...]
<grantee> ::= PUBLIC | <authorization identifier>
Смысл механизма определения привилегий в SQL/89 достаточно понятен из этого синтаксиса. Заметим лишь, что привилегией REFERENCES по отношению к указанным столбцам таблицы T1 необходимо обладать, чтобы иметь возможность при определении таблицы T определить ограничение по ссылкам между этой таблицей и существующей к этому моменту таблицей T1.
Еще раз заметим, что хотя в общем смысле во всех SQL-ориентированных СУБД поддерживается механизм защиты доступа на основе привилегий, реализации могут различаться в деталях. Это опять то место, которое нужно локализовывать, если стремиться к созданию мобильной прикладной системы.
Определение процедуры
Процедуры в модуле SQL определяются следующими синтаксическими конструкциями:
<procedure> ::=
PROCEDURE <procedure name>
<parameter declaration>...;
<SQL statment>;
<parameter declaration>::=
<parameter name> <data type>
| <SQLCODE parameter>
<SQLCODE parameter> ::= SQLCODE
<SQL statement> ::=
<close statement>
| <commit statement>
| <delete statement positioned>
| <delete statement searched>
| <fetch statement>
| <insert statement>
| <open statement>
| <rollback statement>
| <select statement>
| <update statement positioned>
| <update statement searched>
Имена всех процедур в одном модуле должны быть различны. Любое имя параметра, содержащегося в операторе SQL процедуры, должно быть специфицировано в разделе объявления параметров. Число фактических параметров при вызове процедуры должно совпадать с числом формальных параметров, указанных при ее объявлении. Список формальных параметров каждой процедуры должен содержать ровно один параметр SQLCODE (код ответа процедуры; возможные значения кодов ответа стандартизованы, но некоторые из них определяются в реализации).
Определение столбца
Оператор определения столбца описывается следующими синтаксическими правилами:
<column definition> ::=
<column name> <data type>
[<default clause>] [<column constraint>...]
<default clause> ::=
DEFAULT { <literal> | USER | NULL }
<column constraint> ::=
NOT NULL [<unique specification>]
| <references specification>
| CHECK (<search condition>)
Как видно, кроме обязательной части, в которой определяется имя столбца и его тип данных, определение столбца может содержать два необязательных раздела: раздел значения столбца по умолчанию и раздел ограничений целостности столбца.
В разделе значения по умолчанию указывается значение, которое должно быть помещено с строку, заносимую в данную таблицу, если значение данного столбца явно не указано. Значение по умолчанию может быть указано в виде литеральной константы с типом, соответствующим типу столбца; путем задания ключевого слова USER, которому при выполнении оператора занесения строки соответствует символьная строка, содержащая имя текущего пользователя (в этом случае столбец должен иметь тип символьных строк); или путем задания ключевого слова NULL, означающего, что значением по умолчанию является неопределенное значение. Если значение столбца по умолчанию не специфицировано, и в разделе ограничений целостности столбца указано NOT NULL, то попытка занести в таблицу строку с неспецифицированным значением данного столбца приведет к ошибке.
Указание в разделе ограничений целостности NOT NULL приводит к неявному порождению проверочного ограничения целостности для всей таблицы (см. следующий подраздел) "CHECK (C IS NOT NULL)" (где C - имя данного столбца). Если ограничение NOT NULL не указано, и раздел умолчаний отсутствует, то неявно порождается раздел умолчаний DEFAULT NULL. Если указана спецификация уникальности, то порождается соответствующая спецификация уникальности для таблицы.
Если в разделе ограничений целостности указано ограничение по ссылкам данного столбца (<reference specification>), то порождается соответствующее определение ограничения по ссылкам для таблицы:
FOREIGN KEY(C) <reference specification>.
Наконец, если указано проверочное ограничение столбца, то условие поиска этого ограничения должно ссылаться только на данный столбец, и неявно порождается соответствующее проверочное ограничение для всей таблицы.
Определение таблицы
Оператор определения таблицы имеет следующий синтаксис:
<table definition> ::=
CREATE TABLE <table name> (<table element>
[{,<table element>}...])
<table element> ::=
<column definition>
| <table constraint definition>
Кроме имени таблицы, в операторе специфицируется список элементов таблицы, каждый из которых служит либо для определения столбца, либо для определения ограничения целостности определяемой таблицы. Требуется наличие хотя бы одного определения столбца. Оператор CREATE TABLE определяет так называемую базовую таблицу, т.е. реальное хранилище данных.
Для определения столбцов таблицы и ограничений целостности используются специальные операторы, которые должны быть вложены в оператор определения таблицы.
Определение управляющих структур
Внесение в реляционный язык, каким является SQL, явных операторов порождения и уничтожения структур физического уровня, поддерживающих эффективное выполнение запросов к БД, явилось в SQL System R чисто прагматическим решением, обеспечивающим возможность всех видов работ с БД с помощью одного языка.
В SQL System R упоминаются два вида таких структур: индексы и связи (links). Индекс в его абстрактном языковом представлении - это инвертированный файл, обеспечивающий доступ к кортежам соответствующего отношения на основе заданных значений одного или нескольких столбцов, составляющих ключ индекса. Операторы языка позволяли создавать и уничтожать индексы, но никаким образом не давали возможности явно указать на необходимость использования существующего индекса при выполнении оператора выборки, решение об этом возлагалось на реализацию.
С помощью оператора определения индекса можно было выразить два дополнительных утверждения, касающихся логической схемы отношения и физической структуры его хранения. Использование при определении индекса ключевого слова UNIQUE означало, что ключ этого индекса является возможным ключом соответствующего отношения. Фактически это означает наличие дополнительного механизма определения ограничения целостности отношения. Один из индексов для данного отношения мог быть определен с ключевым словом CLUSTERING. Это означает требование физической кластеризации во внешней памяти кортежей отношения с равными или близкими значениями ключа индекса.
Операторы определения связи позволяли в стиле сетевой модели данных организовать во внешней памяти списки кортежей указанного отношения. Как и в случае индексов, операторы позволяли создавать и уничтожать такие списки, но не давали возможности явно указать на необходимость использования существующих списков при выполнении операторов выборки. Большая трудоемкость поддержания списков при выполнении операторов манипулирования данными и трудность выполнения оценок стоимости их использования при выполнении операторов выборки привели к тому, что механизм связей исчез из языка уже на поздней стадии проекта System R. С тех пор этот механизм, насколько нам известно, не появлялся ни в одном варианте SQL.
Определения ограничений целостности и триггеров
Язык SQL System R включал очень мощные средства контроля и поддержания целостности БД. Средства контроля базировались на аппарате ограничений целостности (ASSERTIONS). Фактически, ограничение целостности - это логическое выражение, вычисляемое над текущим состоянием БД, ложность которого соответствует нецелостному состоянию БД. Логическое выражение ограничения целостности могло содержать любой допустимый в языке предикат.
Более точно, ограничения целостности делились на два класса: проверяемые после выполнения оператора манипулирования данными и проверяемые при завершении транзакции или при выполнении специального оператора INFORCE INTEGRITY. Типы предикатов, которые можно использовать в операторах определения ограничений целостности разных классов, различаются. В операторах первого класса проверяется, фактически, текущий кортеж, с которым производится манипулирование. Во втором случае проверяются указанные в ограничении целостности отношения, т.е. все их кортежи. Различается и определяемая в языке реакция системы на нарушения ограничений целостности разных классов. В первом случае нарушение ограничения целостности приводит к откату транзакции в точку, непосредственно предшествующую операции манипулирования данными, выполнение которого вызвало нарушение ограничения целостности. Во втором случае ограничение приводит к полному откату транзакции к ее началу.
Очень важным механизмом, определенным в языке SQL System R, является механизм триггеров. В контексте System R этот механизм рассматривался главным образом как средство автоматического поддержания целостности БД. При определении триггера указывалось условие проверки его применимости (имя отношения и тип операции манипулирования данными), условие применимости триггера (логическое выражение, построенное по правилам, близким к правилам для ограничений целостности первого класса) и действие, которое должно быть выполнено над БД в случае истинности условия применимости. Такое действие могло быть выражено с помощью произвольного оператора манипулирования данными. Во время выполнения действия могли срабатывать другие триггеры и т.д.
Механизмы ограничений целостности и триггеров System R являлись очень мощными и общими, но реализация их очень трудна и накладна (как уже отмечалось, триггеры так и не были реализованы в System R). Дополнительную сложность в реализации создавал тот факт, что допускалось (по крайней мере не запрещалось языком) определение ограничений целостности и триггеров в пределах той же транзакции, в которой выполняются операторы манипулирования данными. При наиболее полной реализации требовалось бы большое число дополнительных действий во время выполнения транзакции. Кроме того, в ряде случаев отсутствие зафиксированной семантики соответствующих конструкций языка приводило к неоднозначному пониманию выполнения транзакций.
Оптимизация запросов, управляемая правилами
В лекции 18 мы коротко рассмотрели проблемы оптимизации запросов, которые приходится решать в компиляторах языков баз данных. Возможно, главным выводом, который следовало бы сделать на основе материалов этой лекции, является то, что оптимизатор запросов - это наиболее громоздкий, сложный и критичный компонент СУБД. Все разработчики систем управления базами данных согласны с тем, что на оптимизации запросов экономить нельзя. Чем большее количество вариантов выполнения запроса анализируется и чем более точные оценки стоимости плана выполнения запроса применяются, тем более вероятно, что запрос будет выполнен эффективно.
Главная неприятность, связанная с оптимизаторами запросов, состоит в том, что отсутствует принятая технология их программирования. Обычно оптимизатор представляет собой аморфный набор относительно независимых процедур, которые жестко связаны с другими компонентами компилятора. По этой причине очень трудно менять стратегии оптимизации или качественно их расширять (делать это приходится, поскольку оптимизация вообще и оптимизация запросов, в частности, в принципе является эмпирической дисциплиной, а хорошие эмпирические алгоритмы появляются только со временем).
Каким же образом можно решать эту проблему? Имеются компромиссные решения, не выводящие за пределы традиционной технологии производства компиляторов. В основном все они связаны с применением тех или иных инструментальных средств, обеспечивающих автоматизацию построения компиляторов. Среди них отметим технологию, примененную Ричардом Столлманом в его семействе компиляторов gcc, а также инструментальный пакет Cocktail, разработанный в Германском университете города Карлсруе. Основным производственным достоинством gcc является применение единого языка в качестве средства внутреннего представления программы. Высокоуровневый лиспоподобный язык RTL используется на всех фазах компиляции gcc, что позволяет применять одни и те же преобразующие процедуры на разных стадиях оптимизации программы (вплоть до стадии машинно-зависимых оптимизаций).
В пакете Cocktail обеспечивается набор универсальных, настраиваемых процедур преобразования графов внутреннего представления программы. В некотором смысле Cocktail можно рассматривать как специализированный язык для написания компиляторов (компиляторов любых языков, а не только процедурных языков программирования или декларативных языков баз данных). Как утверждается, Cocktail позволяет повысить производительность труда разработчиков компиляторов в 2-3 раза.
Однако наиболее революционный подход среди известных автору был применен в экспериментальной постреляционной системе компании IBM Starburst. В некотором смысле этот подход является развитием идеи Столлмана, примененной при реализации широко популярного редактора Emacs. Напомним, что в основе этого редактора лежит интерпретатор расширенного диалекта языка Common Lisp. Сам этот интерпретатор написан на языке Си, а основная часть редактора написана на языке Лисп. Это позволяет, среди прочего, добавлять в редактор новые возможности, не покидая его среды: вы просто пишете новый текст на Лиспе и объявляете соответствующую функцию подключенной к редактору.
Система Starburst основана на применении продукционной системы. Эта система является, по существу, виртуальной машиной, в которой выполняются все компоненты СУБД, начиная от компилятора языка баз данных (расширенного варианта языка SQL) и заканчивая подсистемой непосредственного исполнения запросов. Сама СУБД представляет собой набор продукционных правил, каждое из которых вызывается продукционной системой при возникновении соответствующего события и выполняет некоторое действие, которое, в свою очередь, может привести к возникновению события, активизирующего другое правило. Правила представляются на специальном языке. Поддерживается набор предопределенных правил низкого уровня, обеспечивающих интерфейс с подсистемой управления внешней памятью (конечно, по соображениям эффективности эта подсистема написана не на продукционном языке).
Очевидно, что такая организация системы обеспечивает максимальную гибкость.Например, чтобы внедрить в оптимизатор запросов некоторую новую стратегию выполнения (например, расширить применяемый набор методов выполнения эквисоединения) достаточно дополнительно написать одно или несколько новых правил, связанных с событием требования выполнить соединение. Тем самым, Starburst может использоваться (и реально используется в научно-исследовательских лабораториях компании IBM) как мощное и гибкое средство исследования методов оптимизации запросов. Конечно, сомнительно, что технология, положенная в основу Starburst, позволит этой системе конкурировать с такими выполненными в традиционной манере коммерческими СУБД, как DB2, Oracle, Informix и т.д.
Организация внешней памяти в базах данных System R
Как мы отмечали, база данных System R располагается в одном или нескольких сегментах внешней памяти. Каждый сегмент состоит из страниц данных и страниц индексной информации. Размер страницы данных в сегменте может быть выбран равным либо 4, либо 32 килобайтам; размер страницы индексной информации равен 512 байтам. Кроме того, при работе RSS поддерживается дополнительный набор данных для ведения журнала. Для повышения надежности журнала (а это наиболее критичная информация; при ее потере восстановление базы данных после сбоев невозможно) этот набор данных дублируется на двух внешних носителях.
В каждой странице данных хранятся кортежи одного или нескольких отношений. Фундаментальным понятием RSS является идентификатор кортежа (tuple identifier - tid). Гарантируется неизменяемость tid'а во все время существования кортежа в базе данных независимо от перемещений кортежа внутри страницы и даже при перемещении кортежа в другую страницу. Реально tid представляет собой пару <номер страницы, индекс описателя кортежа в странице>. При этом кортеж может реально располагаться в данной странице:
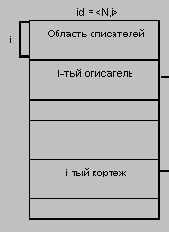
или в другой странице:
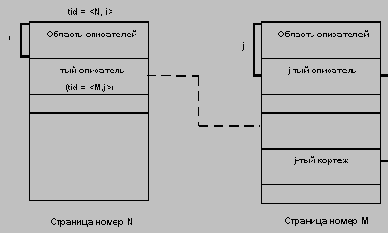
Во втором случае описатель кортежа содержит не координаты кортежа в данной странице, а tid, указывающий на реальное положение кортежа в другой странице. Легко видеть, что применение такого подхода позволяет ограничиться максимум одним уровнем косвенности.
Поскольку допускается нахождение в одной странице данных кортежей разных отношений, каждый кортеж должен, кроме содержательной части, включать служебную информацию, идентифицирующую отношение, которому принадлежит данный кортеж. Кроме того, в System R (точнее, в языке SQL) допускается динамическое добавление полей к существующим отношениям. При этом реально происходит лишь модификация описателя отношения в отношении-каталоге отношений. В существующем кортеже отношения новое поле возникает только при модификации этого кортежа, затрагивающей новое поле. Это позволяет избежать массовой перестройки хранимого отношения при добавлении к нему новых полей, но, естественно, требует хранения при кортеже дополнительной служебной информации, определяющей реальное число полей в данном кортеже. (Заметим, что удалять существующие поля существующего отношения в SQL System R не разрешается).
На основе наличия неизменяемых во время существования кортежей tid'ов в System R поддерживаются дополнительные управляющие структуры - индексы. Каждый индекс определен на одном или нескольких полях отношения, значения которых составляют его ключ, и позволяет производить прямой поиск по ключу кортежей (их tid'ов) и последовательное сканирование отношения по индексу, начиная с указанного ключа, в порядке возрастания или убывания значений ключа. Некоторые индексы при их создании могут обладать атрибутом уникальности. В таком индексе не допускаются дубликаты ключа. Это единственное средство SQL указания системе первичного ключа отношения (фактически, набора первичного и всех альтернативных ключей отношения).
Для организации индексов в System R применяется техника B-деревьев. Каждый индекс занимает отдельный набор страниц, номер корневой страницы запоминается в описателе индекса. Использование B-деревьев позволяет достичь эффективности при прямом поиске, поскольку они в силу своей сильной ветвистости обладают небольшой глубиной. Кроме того, B-деревья сохраняют порядок ключей в листовых блоках иерархии, что позволяет производить последовательное сканирование отношения в порядке возрастания или убывания значений полей, на которых определен индекс. Фундаментальное свойство B-деревьев - автоматическая балансировка дерева - допускает произведение лишь локальных модификаций индекса при переполнениях и опустошениях страниц индекса. (Мы достаточно вольно используем здесь термин B-дерево. На самом деле в System R используется модифицированный по сравнению с исходным вариант B-деревьев, который называют B*-, а иногда B+-деревьями). В самих B-деревьях System R ничего особенного нет; более подробно мы на этом останавливаться не будем. Отметим только, что System R, насколько нам известно, была первой системой, в которой для организации индексов использовались B-деревья. Эту традицию соблюдает большинство реляционных систем, возникших после System R.
Видимо, наиболее важной особенностью физической организации баз данных в System R является возможность обеспечения кластеризации связанных кортежей одного или нескольких отношений.
Под кластеризацией кортежей понимается физически близкое расположение (в пределах одной страницы данных) логически связанных кортежей. Обеспечение соответствующей кластеризации позволяет добиться высокой эффективности системы при выполнении выделенного класса запросов. В силу большой важности понятия кластеризации в System R и ее развитиях рассмотрим историю вопроса более подробно.
В окончательном варианте System R существует только одно средство определения условий кластеризации отношения - объявить до заполнения отношения один (и только один) индекс, определенный на полях этого отношения, кластеризованным. Тогда, если заполнение отношения кортежами производится в порядке возрастания или убывания значений полей кластеризации (в зависимости от атрибутики индекса), система физически располагает кортежи в страницах данных в том же порядке. Кроме того, в каждой странице данных кластеризованного отношения оставляется некоторое резервное свободное пространство. При последующих вставках кортежей в такое отношение система стремится поместить каждый кортеж в одну из страниц данных, в которых уже находятся кортежи этого отношения с такими же (или близкими) значениями полей кластеризации. Естественно, что поддерживать идеальную кластеризацию отношения можно только до определенного предела, пока не исчерпается резервная память в страницах. Далее этого предела степень кластеризации отношения начинает уменьшаться, и для восстановления идеальной кластеризации отношения требуется физическая реорганизация отношения (ее можно произвести средствами SQL).
Очевидным преимуществом кластеризации отношения является то, что при последовательном сканировании кластеризованного отношения с использованием кластеризованного индекса потребуется ровно столько чтений страниц данных с внешней памяти, сколько страниц занимают кортежи этого отношения. Следовательно, при правильно выбранных критериях кластеризации запросы, связанные с заданием условий на полях кластеризации можно выполнить почти оптимально.
В ранних версиях System R существовал еще один способ физического доступа к кортежам отношения и, соответственно, еще один способ указания условия кластеризации с использованием так называемых связей (links). На уровне физического представления связь - это физическая ссылка (tid) из одного кортежа на другой (не обязательно одного отношения). В языке SEQUEL (до того момента, когда его стали называть SQL) существовали средства определения связей в иерархической манере: можно было объявить некоторое отношение родительским по отношению к тому же или другому отношению-потомку. При этом указывались поля родительского отношения и отношения-потомка, в соответствии со значениями которых образовывалась иерархия. Правила построения были очень простыми - проводились связи между кортежем родительского отношения ко всем кортежам отношения-потомка с теми же значениями полей связывания. На самом деле, все кортежи отношения-потомка с общим значением полей связывания образовывали кольцевой список, на который проводилась одна связь из соответствующего кортежа родительского отношения. Естественно, от отношения-родителя требовалась уникальность по отношению к значениям полей связывания.
Следует заметить, что мы описали способ использования механизма связей, который поддерживался в ранних версиях SEQUEL. В интерфейсе RSS System R этого периода допускалась возможность произвольного проведения связей без учета совпадения значений полей связывания. Тем самым, в системе в целом не использовались все возможности RSS, которые с избытком превосходили потребности организации иерархических бинарных связей по совпадению полей связывания.
Для одного отношения допускалось создание многих связей: кортеж отношения мог быть родителем нескольких иерархий и входить в несколько других иерархий в качестве потомка. При этом одна связь могла быть объявлена кластеризованной. Тогда система стремилась поместить в одну страницу данных все кортежи одной иерархии. При этом, естественно, использовалась возможность размещения в одной странице данных кортежей нескольких отношений.
Основной смысл такой кластеризации заключался в возможности оптимизации выполнения некоторых запросов, включающих (экви)соединение двух связанных отношений в соответствии со значениями полей связывания.
В более поздних публикациях по System R упоминания о механизме связей исчезли, из чего можно заключить, что разработчики отказались от его использования. Думается, что основными причинами отказа от использования связей были следующие. Во-первых, средства построения связей, обеспечиваемые RSS, были очень низкого уровня, гораздо более низкого, чем средства поддержания индексов. Если при занесении кортежа RSS обеспечивала автоматическую коррекцию всех индексов, то для коррекции связей требовалось выполнить ряд дополнительных обращений к RSS, из-за чего время выполнения операции занесения кортежа, конечно, увеличивалось (то же касается операций удаления и модификации кортежа). Во-вторых, при реализации этого механизма, возникают дополнительные синхронизационные проблемы нижнего уровня (уровня совместного доступа к страницам данных). В частности, наличие прямых ссылок между страницами данных увеличивает вероятность возникновения синхронизационных тупиков. Наконец, в-третьих, все эти дополнительные накладные расходы не окупались предоставляемыми механизмом связей преимуществами. Действительно, максимального эффекта от использования связей можно достичь только при выполнении операции соединения двух кластеризованных по этой связи отношений, если поле соединения совпадает с полем связывания, и условия, накладываемые на родительское отношение, выделяют в нем ровно один кортеж. Очевидно, что такие запросы на практике редки. (Отметим, что приведенные соображения принадлежат автору и не излагались в публикациях по System R, так что на самом деле причины могли быть и другими.)
Кроме отношений и индексов при работе System R на внешней памяти могут располагаться еще и временные объекты - списки (lists). Список - это мгновенный снимок некоторой выборки с проекцией кортежей одного отношения, возможно, упорядоченный в соответствии со значениями некоторых полей.Средства работы со списками имеются в интерфейсе RSS, но их, естественно, нет в SQL. Соответственно, эти средства используются только внутри системы при выполнении запросов (в частности, один из наиболее эффективных алгоритмов выполнения соединений основан на использовании отсортированных списков кортежей). Публикации по System R не дают точного представления о структурах данных, используемых при организации списков, но исходя из здравого смысла можно предположить, что они устроены не так, как отношения (например, для кортежа, входящего в список, не требуется адресация через tid), и что располагаются они во временных файлах (в случае сбоя системы все временные объекты пропадают).
Ориентация на расширенную реляционную модель
Одним из основных положений реляционной модели данных является требование нормализации отношений: поля кортежей могут содержать лишь атомарные значения. Для традиционных приложений реляционных СУБД - банковских систем, систем резервирования и т.д. - это вовсе не ограничение, а даже преимущество, позволяющее проектировать экономные по памяти БД с предельно понятной структурой. Запросы с соединениями в таких системах сравнительно редки, для динамической поддержки целостности используются соответствующие средства SQL.
Однако с появлением эффективных реляционных СУБД их стали пытаться использовать и в менее традиционных прикладных системах - САПР, системах искусственного интеллекта и т.д. Такие системы обычно оперируют сложно структурированными объектами, для реконструкции которых из плоских таблиц реляционной БД приходится выполнять запросы, почти всегда требующие соединения отношений. В соответствии с требованиями разработчиков нетрадиционных приложений появилось направление исследований баз сложных объектов. Основной смысл этого направления состоит в том, что в руки проектировщиков даются настолько же мощные и гибкие средства структуризации данных, как те, которые были присущи иерархическим и сетевым системам базам данных.
Однако важным отличием является то, что в системах баз данных, поддерживающих сложные объекты, сохраняется четкая граница между логическим и физическим представлениями таких объектов. В частности, для любого сложного объекта (произвольной сложности) должна обеспечиваться возможность перемещения или копирования его как единого целого из одной части базы данных в другую ее часть или даже в другую базу данных. Это очень обширная область исследований, в которой затрагиваются вопросы моделей данных, структур данных, языков запросов, управления транзакциями, журнализации и т.д. Во многом эта область соприкасается с областью объектно-ориентированных БД. (И в этой области настолько же плохо обстоят дела с теоретическим обоснованием.)
Близкое, но, вообще говоря, основанное на других принципах направление представлено системами баз данных, основанных на реляционной модели, в которой не обязательно поддерживается первая нормальная форма отношений.
Напомним, что требование атомарности значений, которые могут храниться в элементах кортежей отношений, является базовым требованием классической реляционной модели. Приведение исходного табличного представления предметной области к "плоскому" виду является обязательным первым шагом в процессе проектирования реляционной базы данных на основе принципов нормализации. С другой стороны, абсолютно очевидно, что такое "уплощение" таблиц хотя и является необходимым условием получения неизбыточной и "правильной" схемы реляционной базы данных, в дальнейшем потенциально вызывает выполнение многочисленных соединений, наличие которых может свести на нет все преимущества "хорошей" схемы базы данных.
Так вот, в "ненормализованных" реляционных моделях данных допускается хранение в качестве элемента кортежа кортежей (записей), массивов (регулярных индексированных множеств данных), регулярных множеств элементарных данных, а также отношений. При этом такая вложенность может быть, по существу, неограниченной. Если внимательно продумать эти идеи, то станет понятно, что они приводят (только) к логически обособленным (от физического представления) возможностям иерархической модели данных. Но это уже не так уж и мало, если учесть, что к настоящему времени фактически полностью сформировано теоретическое основание реляционных баз данных с отказом от нормализации. Скорее всего, в этой теории все еще имеются темные места (они наличествуют даже в классической реляционной теории), но тем не менее большинство известных теоретических результатов реляционной теории уже распространено на ненормализованную модель, и даже такой пурист реляционной модели, как Дейт, полагает возможным использование ограниченной и контролируемой реляционной модели в SQL-3.
Основные цели System R и их связь с архитектурой системы
Основными целями разработчиков System R являлись следующие:
обеспечить ненавигационный интерфейс высокого уровня пользователя с системой, позволяющий достичь независимости данных и дать возможность пользователям работать максимально эффективно;
обеспечить многообразие допустимых способов использования СУБД, включая программируемые транзакции, диалоговые транзакции и генерацию отчетов;
поддерживать динамически изменяемую среду баз данных, в которой отношения, индексы, представления, транзакции и другие объекты могут легко добавляться и уничтожаться без приостановки нормального функционирования системы;
обеспечить возможность параллельной работы с одной базой данных многих пользователей с допущением параллельной модификации объектов базы данных при наличии необходимых средств защиты целостности базы данных;
обеспечить средства восстановления согласованного состояния баз данных после разного рода сбоев аппаратуры или программного обеспечения;
обеспечить гибкий механизм, позволяющий определять различные представления хранимых данных и ограничивать этими представлениями доступ пользователей к базе данных по выборке и модификации на основе механизма авторизации;
обеспечить производительность системы при выполнении упомянутых функций, сопоставимую с производительностью существующих СУБД низкого уровня.
Прежде всего отметим, что в основном поставленные цели при разработке System R были достигнуты. Рассмотрим теперь, какими средствами были достигнуты эти цели, и как более точно можно интерпретировать их в контексте System R.
Основой System R является реляционный язык SQL. Иногда его называют языком запросов или языком манипулирования данными, но на самом деле его возможности гораздо шире. Средствами SQL (с соответствующей системной поддержкой) решаются многие из поставленных целей. Язык SQL включает средства динамической компиляции запросов, на основе чего возможно построение диалоговых систем обработки запросов. Допускается динамическая параметризация статически откомпилированных запросов, в результате чего возможно построение эффективных (не требующих динамической компиляции) диалоговых систем со стандартными наборами (параметризуемых) запросов.
Средствами SQL определяются все доступные пользователю объекты баз данных: таблицы, индексы, представления. Имеются средства уничтожения любого такого объекта. Соответствующие операторы языка могут выполняться в любой момент, и возможность выполнения операции данным пользователем зависит от ранее предоставленных ему прав.
Что касается целостности баз данных, то в System R под целостным состоянием базы данных понимается состояние, удовлетворяющее набору сохраняемых при базе данных предикатов целостности. Эти предикаты, называемые в System R условиями целостности (assertions), задаются также средствами языка SQL. Любое предложение языка выполняется в пределах некоторой транзакции - неделимой в смысле состояния базы данных последовательности предложений языка. Неделимость означает, что все изменения, произведенные в пределах одной транзакции либо целиком отображаются в состоянии базы данных, либо полностью в нем отсутствуют. Последняя возможность возникает при откате транзакции, который может произойти по инициативе пользователя (при выполнении соответствующего оператора SQL) или по инициативе системы.
Одной из причин отката транзакции по инициативе системы является как раз нарушение целостности базы данных в результате действий данной транзакции (другие возможные условия отката транзакции по инициативе системы мы рассмотрим позже). Язык SQL содержит средство установки так называемых точек сохранения (savepoint). При инициируемом пользователем откате транзакции можно указать номер точки сохранения, выше которого откат не распространяется. Инициируемый системой откат транзакции производится до ближайшей точки сохранения, в которой условие, вызвавшее откат, уже отсутствует. В частности, откат инициированный по причине нарушения условия целостности, производится до ближайшей точки сохранения, в которой условия целостности соблюдены. (Заметим, что средства установки точек сохранения отсутствуют в коммерческих расширениях System R).
Естественно, что для реального выполнения отката транзакции необходимо запоминание некоторой информации о выполнении транзакции.
В System R для этих и других целей используется специальный набор данных - журнал, в который помещаются записи обо всех меняющих состояние базы данных операциях всех транзакций. При откате транзакции происходит процесс обратного выполнения транзакции (undo), в ходе которого в обратном порядке выполняются все изменения, запомненные в журнале.
В языке SQL имеется средство определения так называемых условных воздействий (triggers), позволяющих автоматически поддерживать целостность базы данных при модификациях ее объектов. Условное воздействие - это каталогизированная операция модификации, для которой задано условие ее автоматического выполнения. Особенно существенно наличие такого аппарата в связи с наличием рассматриваемых ниже представлений базы данных, которыми может быть ограничен доступ к базе данных для ряда пользователей. Возможна ситуация, когда такие пользователи просто не могут соблюдать целостность базы данных без автоматического выполнения условных воздействий, поскольку они просто "не видят" всей базы данных и, в частности, не могут представить всех ограничений ее целостности. Заметим, что, за исключением ранних публикаций по System R, реализация механизма условных воздействий нигде не описывалась, хотя в принципе подходы к реализации достаточно понятны. Этот механизм не реализован в коммерческих системах, возникших на базе System R. Видимо, это связано с возникающими дополнительными непредсказуемыми для пользователей накладными расходами при выполнении транзакций.
Язык SQL содержит средства определения представлений. Представление - это запомненный именованный запрос на выборку данных (из одной или нескольких таблиц). Поскольку SQL - это реляционный язык, то результатом выполнения любого запроса на выборку является таблица, и поэтому концептуально можно относиться к любому представлению как к таблице (при определении представления можно, в частности, присвоить имена полям этой таблицы). В языке допускается использование ранее определенных представлений практически везде, где допускается использование таблиц (с некоторыми ограничениями по поводу возможностей модификации через представления).
Наличие возможности определять представления в совокупности с развитой системой авторизации позволяет ограничить доступ некоторых пользователей к базе данных выделенным набором представлений.
Авторизация доступа к базе данных основана также на средствах SQL. При создании любого объекта базы данных выполняющий эту операцию пользователь становится полновластным владельцем этого объекта, т.е. может выполнять по отношению к этому объекту любую функцию из предопределенного набора. Далее этот пользователь может выполнить оператор SQL, означающий передачу всех его прав на этот объект (или их подмножества) любому другому пользователю. В частности, этому пользователю может быть передано право на передачу всех переданных ему прав (или их части) третьему пользователю и т.д. Одним из прав пользователя по отношению к объекту является право на изъятие у других пользователей всех или некоторых прав, которые ранее им были переданы. Эта операция распространяется транзитивно на всех дальнейших наследников этих прав.
Наличие в языке средств определения представлений и авторизации в принципе позволяет обойтись при эксплуатации System R без традиционного администратора баз данных, поскольку практически все системные действия производятся на основе средств SQL. Тем не менее, если организационно администратор баз данных требуется, то его работа достаточно упрощается за счет унифицированного набора средств управления. Кроме того, в System R каталоги баз данных поддерживаются также в виде таблиц, и к ним применены все запросы языка SQL. Заметим, что в коммерческих СУБД появился ряд дополнительных утилит, не связанных с языком SQL (например, утилиты сбора статистики или массовой загрузки базы данных), и в этих системах, видимо, без администратора базы данных не обойтись.
По части обеспечения параллельной работы многих пользователей с одной базой данных, основной подход System R состоит в том, что пользователь не обязан знать о наличии других, конкурирующих с ним за доступ к базе данных, пользователей, т.е.
система ответственна за обеспечение изолированности пользователей с гарантией отсутствия их взаимного влияния в пределах транзакций. Из этого следует, во-первых, что в интерфейсе пользователя с системой (т.е. в языке SQL) не должно быть средств регулирования взаимодействий с другими пользователями и, во-вторых, что система должна обеспечить автоматическую сериализацию набора транзакций, т.е. обеспечить режим выполнения этого набора транзакций, эквивалентный по конечному результату некоторому последовательному выполнению этих транзакций. Эта проблема решается в System R за счет автоматического выполнения синхронизационных захватов по отношению ко всем изменяемым объектам базы данных. Имеется ряд тонкостей, связанных с такой синхронизацией, на которых мы остановимся ниже.
Одним из основных требований к СУБД вообще и к System R в частности является обеспечение надежности баз данных по отношению к различного рода сбоям. К таким сбоям могут относиться программные ошибки прикладного и системного уровня, сбои процессора, поломки внешних носителей и т.д. В частности, к одному из видов сбоев можно отнести упоминавшиеся выше нарушения целостности базы данных, и автоматический инициируемый системой откат транзакции - это системное средство восстановления базы данных после сбоев такого рода. Как мы отмечали, такое восстановление происходит путем обратного выполнения транзакции на основе информации о внесенных ею изменениях, запомненной в журнале. На информации журнала основано восстановление базы данных и после сбоев другого рода. Управление журнализацией и восстановлением в System R весьма интересно, применяемые методы в ряде случаев отличаются от методов, используемых в других СУБД.
Что касается естественных требований к эффективности системы, то здесь основные решения связаны со спецификой физической организации баз данных на внешней памяти, буферизацией используемых страниц базы данных в оперативной памяти и развитой техникой оптимизации запросов, сформулированных на SQL, производимой на стадии их компиляции.
Структурная организация System R вполне согласуется с поставленными при ее разработке целями и выбранными решениями. Основными структурными компонентами System R являются система управления реляционной памятью (Relational Storage System - RSS) и компилятор запросов языка SQL. RSS обеспечивает интерфейс довольно низкого, но достаточного для реализации SQL, уровня для доступа к хранимым в базе данным. Синхронизация транзакций, журнализация изменений и восстановление баз данных после сбоев также относятся к числу функций RSS. Компилятор запросов использует интерфейс RSS для доступа к разнообразной справочной информации (каталоги отношений, индексов, прав доступа, условий целостности, условных воздействий и т.д.) и производит рабочие программы, выполняемые в дальнейшем также с использованием интерфейса RSS. Таким образом, система естественно разделяется на два уровня - уровень управления памятью и синхронизацией, фактически, не зависящий от базового языка запросов системы, и языковый уровень (уровень SQL), на котором решается большинство проблем System R. Заметим, что эта независимость скорее условная, чем абсолютная: язык SQL можно заменить на другой язык, но он должен обладать примерно такой же семантикой.
Далее мы последовательно рассмотрим особенности организации RSS, процесс компиляции и оптимизации запросов и технику выполнения откомпилированных транзакций (включая отмеченную выше возможность динамической компиляции запросов).
Основные функции СУБД
Более точно, к числу функций СУБД принято относить следующие:
Основные особенности систем, основанных на инвертированных списках
К числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам). Кстати, когда мы будем рассматривать внутренние интерфейсы реляционных СУБД, вы увидите, что они очень близки к пользовательским интерфейсам систем, основанных на инвертированных списках.
Основные понятия модели Entity-Relationship (Сущность-Связи)
Далее мы кратко рассмотрим некоторые черты одной из наиболее популярных семантических моделей данных - модель "Сущность-Связи" (часто ее называют кратко ER-моделью).
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделей одна из наиболее развитых применяется в системе CASE фирмы ORACLE. Ее мы и рассмотрим. Более точно, мы сосредоточимся на структурной части этой модели.
Основными понятиями ER-модели являются сущность, связь и атрибут.
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа.
Ниже изображена сущность АЭРОПОРТ с примерными объектами Шереметьево и Хитроу:

Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е.
любой ли экземпляр данной сущности должен участвовать в данной связи).
Связь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При это в месте "стыковки" связи с сущностью используются трехточечный вход в прямоугольник сущности, если для этой сущности в связи могут использоваться много (many) экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности. Обязательный конец связи изображается сплошной линией, а необязательный - прерывистой линией.
Как и сущность, связь - это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания.
В изображенном ниже примере связь между сущностями БИЛЕТ и ПАССАЖИР связывает билеты и пассажиров. При том конец сущности с именем "для" позволяет связывать с одним пассажиром более одного билета, причем каждый билет должен быть связан с каким-либо пассажиром. Конец сущности с именем "имеет" означает, что каждый билет может принадлежать только одному пассажиру, причем пассажир не обязан иметь хотя бы один билет.
Лаконичной устной трактовкой изображенной диаграммы является следующая:
Каждый БИЛЕТ предназначен для одного и только одного ПАССАЖИРА;
Каждый ПАССАЖИР может иметь один или более БИЛЕТОВ.
На следующем примере изображена рекурсивная связь, связывающая сущность ЧЕЛОВЕК с ней же самой. Конец связи с именем "сын" определяет тот факт, что у одного отца может быть более чем один сын. Конец связи с именем "отец" означает, что не у каждого человека могут быть сыновья.

Лаконичной устной трактовкой изображенной диаграммы является следующая:
Каждый ЧЕЛОВЕК является сыном одного и только одного ЧЕЛОВЕКА;
Каждый ЧЕЛОВЕК может являться отцом для одного или более ЛЮДЕЙ ("ЧЕЛОВЕКОВ").
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности.Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно, с примерами.
Пример:
Уникальным идентификатором сущности является атрибут, комбинация атрибутов, комбинация связей или комбинация связей и атрибутов, уникально отличающая любой экземпляр сущности от других экземпляров сущности того же типа.
Особенности теоретико-множественных операций реляционной алгебры
Хотя в основе теоретико-множественной части реляционной алгебры лежит классическая теория множеств, соответствующие операции реляционной алгебры обладают некоторыми особенностями.
Начнем с операции объединения (все, что будет говориться по поводу объединения, переносится на операции пересечения и взятия разности). Смысл операции объединения в реляционной алгебре в целом остается теоретико-множественным. Но если в теории множеств операция объединения осмысленна для любых двух множеств-операндов, то в случае реляционной алгебры результатом операции объединения должно являться отношение. Если допустить в реляционной алгебре возможность теоретико-множественного объединения произвольных двух отношений (с разными схемами), то, конечно, результатом операции будет множество, но множество разнотипных кортежей, т.е. не отношение. Если исходить из требования замкнутости реляционной алгебры относительно понятия отношения, то такая операция объединения является бессмысленной.
Все эти соображения приводят к появлению понятия совместимости отношений по объединению: два отношения совместимы по объединению в том и только в том случае, когда обладают одинаковыми заголовками. Более точно, это означает, что в заголовках обоих отношений содержится один и тот же набор имен атрибутов, и одноименные атрибуты определены на одном и том же домене.
Если два отношения совместимы по объединению, то при обычном выполнении над ними операций объединения, пересечения и взятия разности результатом операции является отношение с корректно определенным заголовком, совпадающим с заголовком каждого из отношений-операндов. Напомним, что если два отношения "почти" совместимы по объединению, т.е. совместимы во всем, кроме имен атрибутов, то до выполнения операции типа соединения эти отношения можно сделать полностью совместимыми по объединению путем применения операции переименования.
Заметим, что включение в состав операций реляционной алгебры трех операций объединения, пересечения и взятия разности является очевидно избыточным, поскольку известно, что любая из этих операций выражается через две других.
Тем не менее, Кодд в свое время решил включить все три операции, исходя из интуитивных потребностей потенциального пользователя системы реляционных БД, далекого от математики.
Другие проблемы связаны с операцией взятия прямого произведения двух отношений. В теории множеств прямое произведение может быть получено для любых двух множеств, и элементами результирующего множества являются пары, составленные из элементов первого и второго множеств. Поскольку отношения являются множествами, то и для любых двух отношений возможно получение прямого произведения. Но результат не будет отношением! Элементами результата будут являться не кортежи, а пары кортежей.
Поэтому в реляционной алгебре используется специализированная форма операции взятия прямого произведения - расширенное прямое произведение отношений. При взятии расширенного прямого произведения двух отношений элементом результирующего отношения является кортеж, являющийся конкатенацией (или слиянием) одного кортежа первого отношения и одного кортежа второго отношения.
Но теперь возникает второй вопрос - как получить корректно сформированный заголовок отношения-результата? Очевидно, что проблемой может быть именование атрибутов результирующего отношения, если отношения-операнды обладают одноименными атрибутами.
Эти соображения приводят к появлению понятия совместимости по взятию расширенного прямого произведения. Два отношения совместимы по взятию прямого произведения в том и только в том случае, если множества имен атрибутов этих отношений не пересекаются. Любые два отношения могут быть сделаны совместимыми по взятию прямого произведения путем применения операции переименования к одному из этих отношений.
Следует заметить, что операция взятия прямого произведения не является слишком осмысленной на практике. Во-первых, мощность ее результата очень велика даже при допустимых мощностях операндов, а во-вторых, результат операции не более информативен, чем взятые в совокупности операнды. Как мы увидим немного ниже, основной смысл включения операции расширенного прямого произведения в состав реляционной алгебры состоит в том, что на ее основе определяется действительно полезная операция соединения.
По поводу теоретико-множественных операций реляционной алгебры следует еще заметить, что все четыре операции являются ассоциативными. Т. е., если обозначить через OP любую из четырех операций, то (A OP B) OP C = A (B OP C), и следовательно, без введения двусмысленности можно писать A OP B OP C (A, B и C - отношения, обладающие свойствами, требуемыми для корректного выполнения соответствующей операции). Все операции, кроме взятия разности, являются коммутативными, т.е. A OP B = B OP A.
Открытые системы
Реальное распространение архитектуры "клиент-сервер" стало возможным благодаря развитию и широкому внедрению в практику концепции открытых систем. Поэтому мы начнем с краткого введения в открытые системы.
Основным смыслом подхода открытых систем является упрощение комплексирования вычислительных систем за счет международной и национальной стандартизации аппаратных и программных интерфейсов. Главной побудительной причиной развития концепции открытых систем явились повсеместный переход к использованию локальных компьютерных сетей и те проблемы комплексирования аппаратно-программных средств, которые вызвал этот переход. В связи с бурным развитием технологий глобальных коммуникаций открытые системы приобретают еще большее значение и масштабность.
Ключевой фразой открытых систем, направленной в сторону пользователей, является независимость от конкретного поставщика. Ориентируясь на продукцию компаний, придерживающихся стандартов открытых систем, потребитель, который приобретает любой продукт такой компании, не попадает к ней в рабство. Он может продолжить наращивание мощности своей системы путем приобретения продуктов любой другой компании, соблюдающей стандарты. Причем это касается как аппаратных, так и программных средств и не является необоснованной декларацией. Реальная возможность независимости от поставщика проверена в отечественных условиях.
Практической опорой системных и прикладных программных средств открытых систем является стандартизованная операционная система. В настоящее время такой системой является UNIX. Фирмам-поставщикам различных вариантов ОС UNIX в результате длительной работы удалось придти к соглашению об основных стандартах этой операционной системы. Сейчас все распространенные версии UNIX в основном совместимы по части интерфейсов, предоставляемых прикладным (а в большинстве случаев и системным) программистам. Как кажется, несмотря на появление претендующей на стандарт системы Windows NT, именно UNIX останется основой открытых систем в ближайшие годы.
Технологии и стандарты открытых систем обеспечивают реальную и проверенную практикой возможность производства системных и прикладных программных средств со свойствами мобильности (portability) и интероперабельности (interoperability). Свойство мобильности означает сравнительную простоту переноса программной системы в широком спектре аппаратно-программных средств, соответствующих стандартам. Интероперабельность означает упрощения комплексирования новых программных систем на основе использования готовых компонентов со стандартными интерфейсами.
Использование подхода открытых систем выгодно и производителям, и пользователям. Прежде всего открытые системы обеспечивают естественное решение проблемы поколений аппаратных и программных средств. Производители таких средств не вынуждаются решать все проблемы заново; они могут по крайней мере временно продолжать комплексировать системы, используя существующие компоненты.
Заметим, что при этом возникает новый уровень конкуренции. Все производители обязаны обеспечить некоторую стандартную среду, но вынуждены добиваться ее как можно лучшей реализации. Конечно, через какое-то время существующие стандарты начнут играть роль сдерживания прогресса, и тогда их придется пересматривать.
Преимуществом для пользователей является то, что они могут постепенно заменять компоненты системы на более совершенные, не утрачивая работоспособности системы. В частности, в этом кроется решение проблемы постепенного наращивания вычислительных, информационных и других мощностей компьютерной системы.
Отсутствие кортежей-дубликатов
То свойство, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения по крайней мере полный набор его атрибутов обладает этим свойством. Однако при формальном определении первичного ключа требуется обеспечение его "минимальности", т.е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства - однозначно определять кортеж. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных.
Забегая вперед, заметим, что во многих практических реализациях РСУБД допускается нарушение свойства уникальности кортежей для промежуточных отношений, порождаемых неявно при выполнении запросов. Такие отношения являются не множествами, а мультимножествами, что в ряде случаев позволяет добиться определенных преимуществ, но иногда приводит к серьезным проблемам.
Отсутствие упорядоченности атрибутов
Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем такая возможность не допускается, и хотя упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения.
Отсутствие упорядоченности кортежей
Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, вообще говоря, не отношение, а некоторый упорядоченный список кортежей.
Пятая нормальная форма
Во всех рассмотренных до этого момента нормализациях производилась декомпозиция одного отношения в два. Иногда это сделать не удается, но возможна декомпозиция в большее число отношений, каждое из которых обладает лучшими свойствами.
Рассмотрим, например, отношение
СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР, ОТД_НОМЕР, ПРО_НОМЕР)
Предположим, что один и тот же сотрудник может работать в нескольких отделах и работать в каждом отделе над несколькими проектами. Первичным ключем этого отношения является полная совокупность его атрибутов, отсутствуют функциональные и многозначные зависимости.
Поэтому отношение находится в 4NF. Однако в нем могут существовать аномалии, которые можно устранить путем декомпозиции в три отношения.
Определение 12. Зависимость соединения
Отношение R (X, Y, ..., Z) удовлетворяет зависимости соединения * (X, Y, ..., Z) в том и только в том случае, когда R восстанавливается без потерь путем соединения своих проекций на X, Y, ..., Z.
Определение 13. Пятая нормальная форма
Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения - PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Введем следующие имена составных атрибутов:
СО = {СОТР_НОМЕР, ОТД_НОМЕР}
СП = {СОТР_НОМЕР, ПРО_НОМЕР}
ОП = {ОТД_НОМЕР, ПРО_НОМЕР}
Предположим, что в отношении СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ существует зависимость соединения:
* (СО, СП, ОП)
На примерах легко показать, что при вставках и удалениях кортежей могут возникнуть проблемы. Их можно устранить путем декомпозиции исходного отношения в три новых отношения:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, ОТД_НОМЕР)
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР)
ОТДЕЛЫ-ПРОЕКТЫ (ОТД_НОМЕР, ПРО_НОМЕР)
Пятая нормальная форма - это последняя нормальная форма, которую можно получить путем декомпозиции. Ее условия достаточно нетривиальны, и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением как многозначной зависимости, так и функциональной зависимости.
Поддержка исторической информации и темпоральных запросов
Обычные БД хранят мгновенный снимок модели предметной области. Любое изменение в момент времени t некоторого объекта приводит к недоступности состояния этого объекта в предыдущий момент времени. Самое интересное, что на самом деле в большинстве развитых СУБД предыдущее состояние объекта сохраняется в журнале изменений, но возможности доступа со стороны пользователя нет.
Конечно, можно явно ввести в хранимые отношения явный временной атрибут и поддерживать его значения на уровне приложений. Более того, в большинстве случаев так и поступают. Недаром в стандарте SQL появились специальные типы данных date и time. Но в таком подходе имеются несколько недостатков: СУБД не знает семантики временного поля отношения и не может контролировать корректность его значений; появляется дополнительная избыточность хранения (предыдущее состояние объекта данных хранится и в основной БД, и в журнале изменений); языки запросов реляционных СУБД не приспособлены для работы со временем.
Существует отдельное направление исследований и разработок в области темпоральных БД. В этой области исследуются вопросы моделирования данных, языки запросов, организация данных во внешней памяти и т.д. Основной тезис темпоральных систем состоит в том, что для любого объекта данных, созданного в момент времени t1 и уничтоженного в момент времени t2, в БД сохраняются (и доступны пользователям) все его состояния во временном интервале [t1,t2].
Исследования и построения прототипов темпоральных СУБД обычно выполняются на основе некоторой реляционной СУБД. Как и в случае дедуктивных БД темпоральная СУБД - это надстройка над реляционной системой. Конечно, это не лучший способ реализации с точки зрения эффективности, но он прост и позволяет производить достаточно глубокие исследования.
Примером кардинального (но, может быть, преждевременного) решения проблемы темпоральных БД может служить СУБД Postgres. Эта система была спроектирована и разработана М.Стоунбрекером для исследований и обучения студентов в университете г.Беркли, и он безбоязненно шел в ней на самые смелые эксперименты.
Главными особенностями системы управления памятью в Postgres являются, во-первых, то, что в ней не ведется обычная журнализация изменений базы данных и мгновенно обеспечивается корректное состояние базы данных после перевызова системы с утратой состояния оперативной памяти. Во-вторых, система управления памятью поддерживает исторические данные. Запросы могут содержать временные характеристики интересующих объектов. Реализационно эти два аспекта связаны.
Основное решение состоит в том, что при модификациях кортежа изменения производятся не на месте его хранения, а заводится новая запись, куда помещаются измененные поля. Эта запись содержит, кроме того, данные, характеризующие транзакцию, производившую изменения (в том числе и время ее завершения), и подшивается в список к изменявшемуся кортежу. В системе поддерживается уникальная идентификация транзакций и имеется специальная таблица транзакций, хранящаяся в стабильной памяти. Таким образом, после сбоев просто не следует обращать внимание на хвостовые записи списков, относящиеся к незакончившемся транзакциям. Синхронизация поддерживается на основе обычного двухфазного протокола захватов.
Отдельный компонент системы осуществляет архивацию объектов базы данных. Он производит сборку разросшихся списков изменявшихся кортежей и записывает их в область архивного хранения. К этой области тоже могут адресоваться запросы, но уже только на чтение.
Система ориентирована на использование оптических дисков с разовой записью и стабильной оперативной памяти (хотя бы небольшого объема). При наличии таких технических средств она выигрывает по эффективности даже при работе в традиционном режиме по сравнению со схемой с журнализацией. Однако возможна работа и на традиционной аппаратуре, тогда эффективность системы слегка уступает традиционным схемам.
Соответствующие возможности работы с историческими данными заложены в язык Postquel (и в этом его главное отличие от последних вариантов Quel). Возможна выборка информации, хранившейся в базе данных в указанное время, в указанном временном интервале и т.д.Кроме того, имеется возможность создавать версии отношений и допускается их последующая модификация с учетом изменений основных вариантов.
Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. Мы рассмотрим более подробно языки ранних СУБД в следующей лекции.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). В нескольких лекциях этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е.
при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Более точное описание возможных реализаций этих функций на основе языка SQL будет приведено в лекциях, посвященных языку SQL и его реализации.
Подготавливаемый оператор позиционного удаления
<preparable dynamic delete statement: positioned> ::=
DELETE [FROM <table name>]
WHERE CURRENT OF <cursor name>
Комментарий:
Основной смысл появления этого и следующего операторов состоит в том, что сочетание курсора, определенного на динамически подготовленном операторе выборки, и статически задаваемых операторов удаления и модификации по этому курсору, выглядит довольно нелепо. Поэтому в стандарте появились динамически подготавливаемые позиционные операторы удаления и вставки. Естественно, что выполняться они должны с помощью оператора EXECUTE.
Подготавливаемый оператор позиционной модификации
<preparable dynamic update statement: positioned> ::=
UPDATE [<table name>]
SET <set clause> [{<comma> <set clause>}...]
WHERE CURRENT OF <cursor name>
Комментарий:
Смотри предыдущий пункт.
Если внимательно сравнивать средства динамического SQL СУБД Oracle V.6 и стандарта SQL/92, то видно, что Oracle практически вкладывается в стандарт, если не считать небольших синтаксических различий и (что существенно более важно) разного стиля работы с дескрипторами. Думается, что примерно такая же ситуация имеет место в других СУБД, поддерживающих динамический SQL.
Подзапрос
Наконец, последняя конструкция SQL/89, которая может содержать табличные выражения, - это подзапрос, т.е. запрос, который может входить в предикат условия выборки оператора SQL. В SQL/89 к подзапросам применяется то ограничение, что результирующая таблица должна содержать в точности один столбец. Поэтому в синтаксических правилах, определяющих подзапрос, вместо списка выборки указано "выражение, вычисляющее значение", т.е. арифметическое выражение. Заметим еще, что поскольку подзапрос всегда вложен в некоторый другой оператор SQL, то в качестве констант в арифметическом выражении выборки и логических выражениях разделов WHERE и HAVING можно использовать значения столбцов текущих строк таблиц, участвующих в (под)запросах более внешнего уровня. Более подробно об этом см. ниже, при описании семантики табличных выражений.
Получение реляционной схемы из ER-схемы
Шаг 1. Каждая простая сущность превращается в таблицу. Простая сущность - сущность, не являющаяся подтипом и не имеющая подтипов. Имя сущности становится именем таблицы.
Шаг 2. Каждый атрибут становится возможным столбцом с тем же именем; может выбираться более точный формат. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам, - не могут.
Шаг 3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификатора, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
Шаг 4. Связи многие-к-одному (и один-к-одному) становятся внешними ключами. Т.е. делается копия уникального идентификатора с конца связи "один", и соответствующие столбцы составляют внешний ключ. Необязательные связи соответствуют столбцам, допускающим неопределенные значения; обязательные связи - столбцам, не допускающим неопределенные значения.
Шаг 5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
Шаг 6. Если в концептуальной схеме присутствовали подтипы, то возможны два способа:
все подтипы в одной таблице (а)
для каждого подтипа - отдельная таблица (б)
При применении способа (а) таблица создается для наиболее внешнего супертипа, а для подтипов могут создаваться представления. В таблицу добавляется по крайней мере один столбец, содержащий код ТИПА; он становится частью первичного ключа.
При использовании метода (б) для каждого подтипа первого уровня (для более нижних - представления) супертип воссоздается с помощью представления UNION (из всех таблиц подтипов выбираются общие столбцы - столбцы супертипа).
| Все в одной таблице | Таблица - на подтип | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Преимущества | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Все хранится вместе Легкий доступ к супертипу и подтипам Требуется меньше таблиц | Более ясны правила подтипов Программы работают только с нужными таблицами | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Недостатки | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Слишком общее решение Требуется дополнительная логика работы с разными наборами столбцов и разными ограничениями Потенциальное узкое место (в связи с блокировками) Столбцы подтипов должны быть необязательными В некоторых СУБД для хранения неопределенных значений требуется дополнительная память | Слишком много таблиц Смущающие столбцы в представлении UNION Потенциальная потеря производительности при работе через UNION Над супертипом невозможны модификации | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
общий домен (а)
явные внешние ключи (б)
Если остающиеся внешние ключи все в одном домене, т.е. имеют общий формат (способ (а)), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей; все эти столбцы могут содержать неопределенные значения.
| Общий домен | Явные внешние ключи | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Преимущества | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Нужно только два столбца | Условия соединения - явные | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Недостатки | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Оба дополнительных атрибута должны использоваться в соединениях | Слишком много столбцов | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Вариант 1 (плохой)
Вариант 2 (существенно лучше, если подтипы действительно существуют)
Вариант 3 (годится при наличии осмысленного супертипа D).
Потеря соответствия между языками программирования и языками запросов в реляционных СУБД
Мы уже говорили, что основная практическая надобность в ООБД связана с потребностью в некоторой интегрированной среде построения сложных информационных систем. В этой среде должны отсутствовать противоречия между структурной и поведенческой частями проекта и должно поддерживаться эффективное управление сложными структурами данных во внешней памяти. В отличие от случая реляционных систем, где при создании приложения приходится одновременно использовать ориентированный на работу со скалярными значениями процедурный язык программирования и ориентированный на работу со множествами декларативный язык запросов (это принято называть потерей соответствия - impedance mismatch), языковая среда ООБД - это объектно-ориентированная система программирования, естественно включающая средства работы с долговременными объектами. "Естественность" включения средств работы с БД в язык программирования означает, что работа с долговременными (хранимыми во внешней БД) объектами должна происходить на основе тех же синтаксических конструкций (и с той же семантикой), что и работа со временными, существующими только во время работы программы объектами.
Эта сторона ООБД наиболее близка родственному направлению языков программирования баз данных. Языки программирования ООБД и БД во многих своих чертах различаются только терминологически; существенным отличием является лишь поддержание в языках первого класса подхода к наследованию классов. Кроме того, языки второго класса, как правило, более развиты как в отношении системы типов, так и в отношении управляющих конструкций.
Другим аспектом языкового окружения ООБД является потребность в языках запросов, которые можно было бы использовать в интерактивном режиме. Если доступ к объектам внешней БД в языках программирования ООБД носит в основном навигационный характер, то для языков запросов более удобен декларативный стиль. Декларативные языки запросов к ООБД менее развиты, чем языки программирования ООБД, и при их реализации возникают существенные проблемы. В следующем разделе мы рассмотрим имеющиеся подходы и их ограничения более подробно. Но начнем с языков программирования ООБД.
Потребности информационных систем
Однако ситуация коренным образом отличается для упоминавшихся в начале лекции информационных систем. Эти системы главным образом ориентированы на хранение, выбор и модификацию постоянно существующей информации. Структура информации зачастую очень сложна, и хотя структуры данных различны в разных информационных системах, между ними часто бывает много общего. На начальном этапе использования вычислительной техники для управления информацией проблемы структуризации данных решались индивидуально в каждой информационной системе. Производились необходимые надстройки над файловыми системами (библиотеки программ), подобно тому, как это делается в компиляторах, редакторах и т.д.
Но поскольку информационные системы требуют сложных структур данных, эти дополнительные индивидуальные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, явилось, на наш взгляд, первой побудительной причиной создания СУБД. Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных.
Покажем это на примере. Предположим, что мы хотим реализовать простую информационную систему, поддерживающую учет сотрудников некоторой организации. Система должна выполнять следующие действия: выдавать списки сотрудников по отделам, поддерживать возможность перевода сотрудника из одного отдела в другой, приема на работу новых сотрудников и увольнения работающих. Для каждого отдела должна поддерживаться возможность получения имени руководителя этого отдела, общей численности отдела, общей суммы выплаченной в последний раз зарплаты и т.д. Для каждого сотрудника должна поддерживаться возможность выдачи номера удостоверения по полному имени сотрудника, выдачи полного имени по номеру удостоверения, получения информации о текущем соответствии занимаемой должности сотрудника и о размере его зарплаты.
Средствами SQL определяются все доступные пользователю объекты баз данных: таблицы, индексы, представления. Имеются средства уничтожения любого такого объекта. Соответствующие операторы языка могут выполняться в любой момент, и возможность выполнения операции данным пользователем зависит от ранее предоставленных ему прав.
Что касается целостности баз данных, то в System R под целостным состоянием базы данных понимается состояние, удовлетворяющее набору сохраняемых при базе данных предикатов целостности. Эти предикаты, называемые в System R условиями целостности (assertions), задаются также средствами языка SQL. Любое предложение языка выполняется в пределах некоторой транзакции - неделимой в смысле состояния базы данных последовательности предложений языка. Неделимость означает, что все изменения, произведенные в пределах одной транзакции либо целиком отображаются в состоянии базы данных, либо полностью в нем отсутствуют. Последняя возможность возникает при откате транзакции, который может произойти по инициативе пользователя (при выполнении соответствующего оператора SQL) или по инициативе системы.
Одной из причин отката транзакции по инициативе системы является как раз нарушение целостности базы данных в результате действий данной транзакции (другие возможные условия отката транзакции по инициативе системы мы рассмотрим позже). Язык SQL содержит средство установки так называемых точек сохранения (savepoint). При инициируемом пользователем откате транзакции можно указать номер точки сохранения, выше которого откат не распространяется. Инициируемый системой откат транзакции производится до ближайшей точки сохранения, в которой условие, вызвавшее откат, уже отсутствует. В частности, откат инициированный по причине нарушения условия целостности, производится до ближайшей точки сохранения, в которой условия целостности соблюдены. (Заметим, что средства установки точек сохранения отсутствуют в коммерческих расширениях System R).
Естественно, что для реального выполнения отката транзакции необходимо запоминание некоторой информации о выполнении транзакции.
В System R для этих и других целей используется специальный набор данных - журнал, в который помещаются записи обо всех меняющих состояние базы данных операциях всех транзакций. При откате транзакции происходит процесс обратного выполнения транзакции (undo), в ходе которого в обратном порядке выполняются все изменения, запомненные в журнале.
В языке SQL имеется средство определения так называемых условных воздействий (triggers), позволяющих автоматически поддерживать целостность базы данных при модификациях ее объектов. Условное воздействие - это каталогизированная операция модификации, для которой задано условие ее автоматического выполнения. Особенно существенно наличие такого аппарата в связи с наличием рассматриваемых ниже представлений базы данных, которыми может быть ограничен доступ к базе данных для ряда пользователей. Возможна ситуация, когда такие пользователи просто не могут соблюдать целостность базы данных без автоматического выполнения условных воздействий, поскольку они просто "не видят" всей базы данных и, в частности, не могут представить всех ограничений ее целостности. Заметим, что, за исключением ранних публикаций по System R, реализация механизма условных воздействий нигде не описывалась, хотя в принципе подходы к реализации достаточно понятны. Этот механизм не реализован в коммерческих системах, возникших на базе System R. Видимо, это связано с возникающими дополнительными непредсказуемыми для пользователей накладными расходами при выполнении транзакций.
Язык SQL содержит средства определения представлений. Представление - это запомненный именованный запрос на выборку данных (из одной или нескольких таблиц). Поскольку SQL - это реляционный язык, то результатом выполнения любого запроса на выборку является таблица, и поэтому концептуально можно относиться к любому представлению как к таблице (при определении представления можно, в частности, присвоить имена полям этой таблицы). В языке допускается использование ранее определенных представлений практически везде, где допускается использование таблиц (с некоторыми ограничениями по поводу возможностей модификации через представления).
Наличие возможности определять представления в совокупности с развитой системой авторизации позволяет ограничить доступ некоторых пользователей к базе данных выделенным набором представлений.
Авторизация доступа к базе данных основана также на средствах SQL. При создании любого объекта базы данных выполняющий эту операцию пользователь становится полновластным владельцем этого объекта, т.е. может выполнять по отношению к этому объекту любую функцию из предопределенного набора. Далее этот пользователь может выполнить оператор SQL, означающий передачу всех его прав на этот объект (или их подмножества) любому другому пользователю. В частности, этому пользователю может быть передано право на передачу всех переданных ему прав (или их части) третьему пользователю и т.д. Одним из прав пользователя по отношению к объекту является право на изъятие у других пользователей всех или некоторых прав, которые ранее им были переданы. Эта операция распространяется транзитивно на всех дальнейших наследников этих прав.
Наличие в языке средств определения представлений и авторизации в принципе позволяет обойтись при эксплуатации System R без традиционного администратора баз данных, поскольку практически все системные действия производятся на основе средств SQL. Тем не менее, если организационно администратор баз данных требуется, то его работа достаточно упрощается за счет унифицированного набора средств управления. Кроме того, в System R каталоги баз данных поддерживаются также в виде таблиц, и к ним применены все запросы языка SQL. Заметим, что в коммерческих СУБД появился ряд дополнительных утилит, не связанных с языком SQL (например, утилиты сбора статистики или массовой загрузки базы данных), и в этих системах, видимо, без администратора базы данных не обойтись.
По части обеспечения параллельной работы многих пользователей с одной базой данных, основной подход System R состоит в том, что пользователь не обязан знать о наличии других, конкурирующих с ним за доступ к базе данных, пользователей, т.е.
система ответственна за обеспечение изолированности пользователей с гарантией отсутствия их взаимного влияния в пределах транзакций. Из этого следует, во-первых, что в интерфейсе пользователя с системой (т.е. в языке SQL) не должно быть средств регулирования взаимодействий с другими пользователями и, во-вторых, что система должна обеспечить автоматическую сериализацию набора транзакций, т.е. обеспечить режим выполнения этого набора транзакций, эквивалентный по конечному результату некоторому последовательному выполнению этих транзакций. Эта проблема решается в System R за счет автоматического выполнения синхронизационных захватов по отношению ко всем изменяемым объектам базы данных. Имеется ряд тонкостей, связанных с такой синхронизацией, на которых мы остановимся ниже.
Одним из основных требований к СУБД вообще и к System R в частности является обеспечение надежности баз данных по отношению к различного рода сбоям. К таким сбоям могут относиться программные ошибки прикладного и системного уровня, сбои процессора, поломки внешних носителей и т.д. В частности, к одному из видов сбоев можно отнести упоминавшиеся выше нарушения целостности базы данных, и автоматический инициируемый системой откат транзакции - это системное средство восстановления базы данных после сбоев такого рода. Как мы отмечали, такое восстановление происходит путем обратного выполнения транзакции на основе информации о внесенных ею изменениях, запомненной в журнале. На информации журнала основано восстановление базы данных и после сбоев другого рода. Управление журнализацией и восстановлением в System R весьма интересно, применяемые методы в ряде случаев отличаются от методов, используемых в других СУБД.
Что касается естественных требований к эффективности системы, то здесь основные решения связаны со спецификой физической организации баз данных на внешней памяти, буферизацией используемых страниц базы данных в оперативной памяти и развитой техникой оптимизации запросов, сформулированных на SQL, производимой на стадии их компиляции.
Структурная организация System R вполне согласуется с поставленными при ее разработке целями и выбранными решениями. Основными структурными компонентами System R являются система управления реляционной памятью (Relational Storage System - RSS) и компилятор запросов языка SQL. RSS обеспечивает интерфейс довольно низкого, но достаточного для реализации SQL, уровня для доступа к хранимым в базе данным. Синхронизация транзакций, журнализация изменений и восстановление баз данных после сбоев также относятся к числу функций RSS. Компилятор запросов использует интерфейс RSS для доступа к разнообразной справочной информации (каталоги отношений, индексов, прав доступа, условий целостности, условных воздействий и т.д.) и производит рабочие программы, выполняемые в дальнейшем также с использованием интерфейса RSS. Таким образом, система естественно разделяется на два уровня - уровень управления памятью и синхронизацией, фактически, не зависящий от базового языка запросов системы, и языковый уровень (уровень SQL), на котором решается большинство проблем System R. Заметим, что эта независимость скорее условная, чем абсолютная: язык SQL можно заменить на другой язык, но он должен обладать примерно такой же семантикой.
Далее мы последовательно рассмотрим особенности организации RSS, процесс компиляции и оптимизации запросов и технику выполнения откомпилированных транзакций (включая отмеченную выше возможность динамической компиляции запросов).
Предикатные синхронизационные захваты
Несмотря на привлекательность метода гранулированных синхронизационных захватов, следует отметить что он не решает проблему фантомов (если, конечно, не ограничиться использованием захватов отношений в режимах S и X). Давно известно, что для решения этой проблемы необходимо перейти от захватов индивидуальных объектов базы данных, к захвату условий (предикатов), которым удовлетворяют эти объекты. Проблема фантомов не возникает при использовании для синхронизации уровня отношений именно потому, что отношение как логический объект представляет собой неявное условие для входящих в него кортежей. Захват отношения - это простой и частный случай предикатного захвата.
Поскольку любая операция над реляционной базой данных задается некоторым условием (т.е. в ней указывается не конкретный набор объектов базы данных, над которыми нужно выполнить операцию, а условие, которому должны удовлетворять объекты этого набора), идеальным выбором было бы требовать синхронизационный захват в режиме S или X именно этого условия. Но если посмотреть на общий вид условий, допускаемых, например, в языке SQL, то становится абсолютно непонятно, как определить совместимость двух предикатных захватов. Ясно, что без этого использовать предикатные захваты для синхронизации транзакций невозможно, а в общей форме проблема неразрешима.
К счастью, эта проблема сравнительно легко решается для случая простых условий. Будем называть простым условием конъюнкцию простых предикатов, имеющих вид
имя-атрибута { = > < } значение
В типичных СУБД, поддерживающих двухуровневую организацию (языковой уровень и уровень управления внешней памяти), в интерфейсе подсистем управления памятью (которая обычно заведует и сериализацией транзакций) допускаются только простые условия. Подсистема языкового уровня производит компиляцию исходного оператора со сложным условием в последовательность обращений к ядру СУБД, в каждом из которых содержатся только простые условия. Следовательно, в случае типовой организации реляционной СУБД простые условия можно использовать как основу предикатных захватов.
Для простых условий совместимость предикатных захватов легко определяется на основе следующей геометрической интерпретации. Пусть R отношение с атрибутами a1, a2, ..., an, а m1, m2, ..., mn - множества допустимых значений a1, a2, ..., an соответственно (все эти множества - конечные). Тогда можно сопоставить R конечное n-мерное пространство возможных значений кортежей R. Любое простое условие "вырезает" m-мерный прямоугольник в этом пространстве (m <= n).
Тогда S-X, X-S, X-X предикатные захваты от разных транзакций совместимы, если соответствующие прямоугольники не пересекаются.
Это иллюстрируется следующим примером, показывающим, что в каких бы режимах не требовала транзакция 1 захвата условия (1<=a<=4) & (b=5), а транзакция 2 - условия (1<=a<=5) & (1<=b<=3), эти захваты всегда совместимы.
Пример: (n = 2)
Заметим, что предикатные захваты простых условий описываются таблицами, немногим отличающимися от таблиц традиционных синхронизаторов.
Представления базы данных
В языке допускалось использование хранимых отношений БД и представляемых отношений. Наиболее удачным решением было использование для определения представлений общего аппарата операторов выборки. Любой оператор выборки может быть использован для определения представления.
В языке отсутствуют какие-либо ограничения по поводу использования представлений: в любом операторе SQL, в котором допускается использование имени хранимого отношения, допускается и использование имени представления. В SQL System R ничего не говорится о рекомендуемом способе реализации доступа к представлениям, но при любом способе эффект должен быть таким, как если бы выполнить полную материализацию представления до выполнения оператора.
Массу проблем, исследований и предложений породила потенциальная возможность выполнения операторов манипулирования данными над представлениями. Понятно, что эта возможность легко реализуема для простых представлений, но в более сложных случаях не только реализация, но и семантика операций становится нетривиальной. Кстати, в System R операторы манипулирования данными допускались только над простыми представлениями.
Преимущества протоколов удаленного вызова процедур
Упоминавшиеся выше протоколы удаленного вызова процедур особенно важны в системах управления базами данных, основанных на архитектуре "клиент-сервер".
Во-первых, использование механизма удаленных процедур позволяет действительно перераспределять функции между клиентской и серверной частями системы, поскольку в тексте программы удаленный вызов процедуры ничем не отличается от удаленного вызова, и следовательно, теоретически любой компонент системы может располагаться и на стороне сервера, и на стороне клиента.
Во-вторых, механизм удаленного вызова скрывает различия между взаимодействующими компьютерами. Физически неоднородная локальная сеть компьютеров приводится к логически однородной сети взаимодействующих программных компонентов. В результате пользователи не обязаны серьезно заботиться о разовой закупке совместимых серверов и рабочих станций.
Преобразования запросов на основе семантической информации
В качестве начальных примеров преобразований запросов на основе семантической информации рассмотрим подходы известных СУБД System R и INGRES к обеспечению работы с базами данных через представления. Эти преобразования не были ориентированы на оптимизацию запросов, но имеют к ней непосредственное отношение.
Представление базы данных (view) в терминах языков SQL и QUEL - это именованный каталогизированный запрос, представляющий собой с точки зрения пользователей такой же объект базы данных, как и отношение. Представления могут использоваться в запросах так же, как и хранимые отношения (с ограничениями на использование их в операторах модификации базы данных).
Семантика представлений требует, чтобы они были точными: в момент выполнения запроса над представлением получаемая информация должна точно соответствовать текущему состоянию хранимой части базы данных. Выполнение запроса над представлением требует его материализации, т.е. вычисления отношения, определяемого запросом, который связан с представлением.
Подход System R и INGRES основан на том, что представления хранятся в каталогах базы данных во внутренней форме, получаемой после выполнения грамматического разбора (а также, возможно, логической оптимизации) соответствующего запроса. При обработке запроса над представлением до выполнения фазы логической оптимизации производится слияние внутренних форм запроса и представления. Образуется некоторая новая преобразованная внутренняя форма, и над ней производится вся последующая обработка запроса, включая логическую оптимизацию и выбор оптимального плана выполнения запроса. При этом оптимизатор получает больше информации о данном запросе и может принимать более правильные решения. Приведем простой пример.
Пусть представление определено как
DEFINE VIEW V (C2) AS
SELECT C1 FROM R WHERE C1 > 6.
Запрос формулируется следующим образом:
SELECT C2 FROM V WHERE C2 < 6.
Если бы запрос компилировался в расчете на явную материализацию представления, был бы выбран способ его выполнения, основанный на последовательном сканировании V с выбором кортежей, удовлетворяющих условию.
Запрос так бы и выполнялся, чтобы в конце концов выдать пустой результат. При слиянии же внутренних форм запроса и представления мы получили бы внутреннюю форму, эквивалентную запросу
SELECT C1 FROM R WHERE C1 < 6 AND C1 >6.
Уже на фазе логической оптимизации можно было бы установить, что он эквивалентен запросу
SELECT C1 FROM R WHERE FALSE,
из чего следовало бы, что результат запроса пуст.
Очевидно, что в ряде случаев этот способ обработки запросов над представлениями базы данных позволяет добиться более эффективного выполнения запроса за счет предоставления оптимизатору большей информации. Та же идея лежит и в основе семантической оптимизации запросов: использование при оптимизации запроса семантической информации, хранящейся в базе данных независимо от данного запроса.
Другим примером преобразований запросов, имеющих непосредственное отношение к оптимизации, являются преобразования запросов на модификацию базы данных для удовлетворения существующих в базе данных ограничений целостности. Этот подход впервые был применен в СУБД INGRES, но используется и в других системах, например, в System R.
Ограничением целостности называется сохраняемое в каталогах базы данных логическое выражение, составленное из предикатов над объектами базы данных. База данных находится в целостном состоянии, если удовлетворяются все заданные ограничения целостности.
Если задан запрос на модификацию базы данных, включающей ограничения целостности, удовлетворение которых требуется при выполнении любой модификации, то можно добавить соответствующие ограничениям предикаты к логическому условию запроса.
Пусть база данных, характеризующая структуру организации, состоит из отношений EMP и DEPT. В отношении EMP регистрируются служащие организации. Схема этого отношения EMP (EMP#, EMPNAME, DEPT#); поле EMP# содержит уникальный номер служащего, поле EMPNANE - имя служащего, а DEPT# - номер отдела организации, в котором работает данный сотрудник. Отношении DEPT хранит информацию об отделах и имеет схему DEPT (DEPT#, EMPCOUNT), где в поле EMPCOUNT хранится общее число сотрудников данного отдела.
Пусть задано ограничение целостности
ASSERT B IMMEDIATE ON EMP: EMP.DEPT# = 6.
Это ограничение означает запрещение занесения, удаления и модификации кортежей в отношении EMP со значением поля DEPT#, отличным от 6. Пусть обрабатывается запрос на удаление кортежа
DELETE EMP WHERE EMPNAME = 'Brown'.
Если при компиляции запроса не учитывать наличие ограничения целостности, то корректным способом выполнения такого запроса будет следующий: последовательно выбирать кортежи, у которых значением поля EMPNAME является 'Brown'; проверять удовлетворение очередного кортежа ограничению целостности, и если проверка удовлетворительна, удалить кортеж.
Если же ограничения целостности учитываются при компиляции, то можно слить внутренние формы запроса и соответствующих ограничений целостности, а потом произвести совместную оптимизацию. В нашем случае после слияния образуется внутренняя форма, эквивалентная запросу
DELETE EMP WHERE EMPNAME = 'Brown' AND DEPT# = 6.
При выполнении такого запроса не понадобятся дополнительные вызовы проверок ограничений целостности второго типа, поскольку они все уже включены в логическое условие выполнения операции удаления. Кроме того, оптимизатор получает большую свободу в выборе способа выполнения запроса. Например, если отделы малочисленны, и для отношения EMP поддерживается индекс на поле DEPT#, то, возможно, наиболее оптимальным способом выполнения запроса будет сканирование отношения через индекс по DEPT# с условием DEPT# = 6 с удалением всякого выбираемого таким образом кортежа со значением поля EMPNAME, равным 'Brown'. Тем самым, преобразующие запрос действия, не направленные специально на оптимизацию, могут способствовать более эффективному выполнению запроса. Эффективность выполнения запроса удается повысить за счет использования знаний, независимо хранящихся в базе данных.
Рассмотренные примеры показывают, что идея семантической оптимизации в принципе не нова. Имеется и принципиальная разница между рассмотренными выше преобразованиями запросов и теми, которые производятся при семантической оптимизации.Основное отличие состоит в том, что когда производятся слияния внутренней формы запроса с внутренней формой представления или внутренними формами ограничений целостности, мы обязаны полностью и однозначно использовать внешнюю информацию, независимо от того, будут ли это способствовать оптимизации запроса: условие выборки представления должно быть целиком добавлено через AND к условию выборки запроса; то же относится и к набору логических условий ограничений целостности. Иначе семантика запроса над представлением или оператора модификации базы данных будет нарушена.
Преобразования запросов с изменением порядка реляционных операций
В традиционных оптимизаторах распространены логические преобразования, связанные с изменением порядка выполнения реляционных операций. Примером соответствующего правила преобразования в терминах реляционной алгебры может быть следующее (A и B - имена отношений):
(A JOIN B) WHERE restriction-on-A AND restriction-on-B
эквивалентно выражению
A WHERE restriction-on-A) JOIN (B WHERE restriction-on-B).
Здесь JOIN обозначает реляционный оператор естественного соединения отношений; A WHERE restriction - оператор ограничения отношения A в соответствии с предикатом restriction.
Хотя немногие реляционные системы имеют языки запросов, основанные в чистом виде на реляционной алгебре, правила преобразований алгебраических выражений могут быть полезны и в других случаях. Довольно часто реляционная алгебра используется в качестве основы внутреннего представления запроса. Естественно, что после этого можно выполнять и алгебраические преобразования.
В частности, существуют подходы, связанные с преобразованием к алгебраической форме запросов на языке SQL. Можно выявить две основные побудительные причины преобразований запросов на SQL к алгебраической форме. Первой, на наш взгляд, менее важной причиной может быть стремление к использованию реляционной алгебры в качестве унифицированного внутреннего интерфейса реляционной СУБД. Такой подход распространен при использовании специализированных машин баз данных, на основе которых реализуются различные интерфейсы доступа к базам данных. Интерфейс машины баз данных должен быть унифицирован (например, быть алгебраическим), а все остальные интерфейсы, включая интерфейс на основе SQL, приводятся к алгебраическому.
Второй причиной, особенно важной в контексте проблем оптимизации, является то, что реляционная алгебра более проста, чем язык SQL. Преобразование запроса к алгебраической форме упрощает дальнейшие действия оптимизатора по выборке оптимальных планов. Вообще говоря, развитый оптимизатор запросов системы, ориентированной на SQL, должен выявить все возможные планы выполнения любого запроса, но "пространство поиска" этих планов в общем случае очень велико; в каждом конкретном оптимизаторе используются свои эвристики для сокращения пространства поиска. Некоторые, возможно, наиболее оптимальные планы никогда не будут рассматриваться. Разумное преобразование запроса на SQL к алгебраическому представлению сокращает пространство поиска планов выполнения запроса с гарантией того, что оптимальные планы потеряны не будут.
System R
Основными целями разработчиков System R являлись следующие:
обеспечить ненавигационный интерфейс высокого уровня пользователя с системой, позволяющий достичь независимости данных и дать возможность пользователям работать максимально эффективно;
обеспечить многообразие допустимых способов использования СУБД, включая программируемые транзакции, диалоговые транзакции и генерацию отчетов;
поддерживать динамически изменяемую среду баз данных, в которой отношения, индексы, представления, транзакции и другие объекты могут легко добавляться и уничтожаться без приостановки нормального функционирования системы;
обеспечить возможность параллельной работы с одной базой данных многих пользователей с допущением параллельной модификации объектов базы данных при наличии необходимых средств защиты целостности базы данных;
обеспечить средства восстановления согласованного состояния баз данных после разного рода сбоев аппаратуры или программного обеспечения;
обеспечить гибкий механизм, позволяющий определять различные представления хранимых данных, и ограничивать этими представлениями доступ пользователей к базе данных по выборке и модификации на основе механизма авторизации;
обеспечить производительность системы при выполнении упомянутых функций, сопоставимую с производительностью существующих СУБД низкого уровня.
Структурная организация System R вполне согласуется с поставленными при ее разработке целями. Основными структурными компонентами System R являются система управления реляционной памятью (Relational Storage System - RSS) и компилятор запросов языка SQL. RSS обеспечивает интерфейс довольно низкого, но достаточного для реализации SQL уровня для доступа к хранимым в базе данным. Синхронизация транзакций, журнализация изменений и восстановление баз данных после сбоев также относятся к числу функций RSS. Компилятор запросов использует интерфейс RSS для доступа к разнообразной справочной информации (каталогам отношений, индексов, прав доступа, условий целостности, условных воздействий и т.д.) и производит рабочие программы, выполняемые в дальнейшем также с использованием интерфейса RSS. Таким образом, система естественно разделяется на два уровня - уровень управления памятью и синхронизацией, фактически, не зависящий от базового языка запросов системы, и языковой уровень (уровень SQL), на котором решается большинство проблем System R. Заметим, что эта независимость скорее условная, чем абсолютная: язык SQL можно заменить на другой язык, но он должен обладать примерно такой же семантикой.
Примеры языков программирования ООБД
Прежде всего, CO2 не является полностью самостоятельным языком. Этот язык входит в многоязыковую среду O2 и предназначен для программирования методов ранее определенных классов. Определение классов, сигнатур методов (фактически, прототипов функций в терминологии языка Си) и имен постоянно хранимых значений и объектов производится с использованием отдельного языка определения схемы БД.
Имя любого объекта трактуется как указатель на значение этого объекта; разименование производится с помощью обычного оператора Си '*'. Доступ к значению объекта возможен только из метода его класса, если только при перечислении методов оператор '*' не объявлен явно публичным.
Поддерживается операция порождения нового объекта указанного класса. В отличие от языка Си++ в CO2 невозможно совместить создание нового объекта с его инициализаций (понятие метода-конструктора начального значения объекта в CO2 не поддерживается). Для инициализации необходимо либо явно обратиться к соответствующему методу класса с указанием вновь созданного объекта (поддерживается соответствующий механизм "передачи сообщений", означающий на самом деле вызов функции), либо воспользоваться оператором '*' и явно присвоить новое значение, если '*' - публичный оператор для данного класса.
CO2 включает средства конструирования значений-кортежей, множеств и списков. Понятие значения-кортежа фактически эквивалентно понятию значения-структуры обычного языка Си (с тем отличием, что элементами кортежа могут являться объекты, множества и списки). Для значений-множеств и списков поддерживаются операции добавления и изъятия элементов, а также набор теоретико-множественных операций (и конкатенации для списков).
Основой манипулирования объектами, хранимыми в БД, является расширенное по сравнению с языком Си средство итерации. Итератор применим к значениям-множествам или спискам. Фактически он означает последовательное применение оператора-тела цикла ко всем элементам множества или списка. Если мы вспомним, что долговременно хранимому классу объектов неявно соответствуют одноименное значение-множество с элементами-объектами данного класса, то становится понятно, что итератор языка CO2 обеспечивает явную навигацию в классах объектов. Единственное, что остается от привычных пользователям СУБД языков запросов, - это ограниченная возможность указания характеристик требуемых в цикле объектов (это делается путем использования оператора разименования и явного указания условий на атрибуты; конечно, для этого нужно, чтобы оператор '*' был объявлен публичным в данном классе).
Разработчики O2 подчеркивают, что они умышленно сделали CO2 более бедным по возможностям, чем, например, язык Си++, потому что многое по части управления объектами берет на себя общий менеджер объектов системы, явно вызываемый из рабочей программы.
Примеры объектно-ориентированных СУБД
В настоящее время ведется очень много экспериментальных и производственных работ в области объектно-ориентированных СУБД. Больше всего университетских работ, которые в основном носят исследовательский характер. Но уже несколько лет назад отмечалось существование по меньшей мере тринадцати коммерчески доступных систем ООБД. Среди них уже упоминавшиеся в нашем обзоре системы O2, ORION, GemStone и Iris.
Рассмотрим особенности организации двух из них - ORION и O2.
Принципы взаимодействия между клиентскими и серверными частями
Доступ к базе данных от прикладной программы или пользователя производится путем обращения к клиентской части системы. В качестве основного интерфейса между клиентской и серверной частями выступает язык баз данных SQL.
Это язык по сути дела представляет собой текущий стандарт интерфейса СУБД в открытых системах. Собирательное название SQL-сервер относится ко всем серверам баз данных, основанных на SQL. Соблюдая предосторожности при программировании, некоторые из которых были рассмотрены на предыдущих лекциях, можно создавать прикладные информационные системы, мобильные в классе SQL-серверов.
Серверы баз данных, интерфейс которых основан исключительно на языке SQL, обладают своими преимуществами и своими недостатками. Очевидное преимущество - стандартность интерфейса. В пределе, хотя пока это не совсем так, клиентские части любой SQL-ориентированной СУБД могли бы работать с любым SQL-сервером вне зависимости от того, кто его произвел.
Недостаток тоже довольно очевиден. При таком высоком уровне интерфейса между клиентской и серверной частями системы на стороне клиента работает слишком мало программ СУБД. Это нормально, если на стороне клиента используется маломощная рабочая станция. Но если клиентский компьютер обладает достаточной мощностью, то часто возникает желание возложить на него больше функций управления базами данных, разгрузив сервер, который является узким местом всей системы.
Одним из перспективных направлений СУБД является гибкое конфигурирование системы, при котором распределение функций между клиентской и пользовательской частями СУБД определяется при установке системы.
Приведение запросов со вложенными подзапросами к запросам с соединениями
Основным отличием языка SQL от языка реляционной алгебры является возможность использовать в логическом условии выборки предикаты, содержащие вложенные подзапросы. Глубина вложенности не ограничивается языком, т.е., вообще говоря, может быть произвольной. Предикаты с вложенными подзапросами при наличии общего синтаксиса могут обладать весьма различной семантикой. Единственным общим для всех возможных семантик вложенных подзапросов алгоритмом выполнения запроса является вычисление вложенного подзапроса всякий раз при вычислении значения предиката. Поэтому естественно стремиться к такому преобразованию запроса, содержащего предикаты со вложенными подзапросами, которое сделает семантику подзапроса более явной, предоставив тем самым в дальнейшем оптимизатору возможность выбрать способ выполнения запроса, наиболее точно соответствующий семантике подзапроса.
Ниже Ri обозначает i-е отношение базы данных; Ck - k-е поле (столбец) отношения.
Предикаты, допустимые в запросах языка SQL, можно разбить на следующие четыре группы:
Простые предикаты. Это предикаты вида Ri.Ck op X, где X - константа или список констант, и op - оператор скалярного сравнения (=, !=, >, >=, <, <=) или оператор проверки вхождения во множество (IS IN, IS NOT IN).
Предикаты со вложенными подзапросами. Это предикаты вида Ri.Ck op Q, где Q - блок запроса, а op может быть таким же, как для простых предикатов. Предикат может также иметь вид Q op Ri.Ck. В этом случае оператор принадлежности ко множеству заменяется на CONTAINS или DOES NOT CONTAIN. Эти две формы симметричны. Достаточно рассматривать только одну.
Предикаты соединения. Это предикаты вида Ri.Ck op Rj.Cn, где Ri != Rj и op - оператор скалярного сравнения.
Предикаты деления. Это предикаты вида Qi op Qj, где Qi и Qj - блоки запросов, а op может быть оператором скалярного сравнения или оператором проверки вхождения в множество.
Приведенная классификация является упрощением реальной ситуации в SQL. Не рассматриваются предикаты соединения общего вида, включающие арифметические выражения с полями более чем двух отношений.
Каноническим представлением запроса на n отношениях называется запрос, содержащий n-1 предикат соединения и не содержащий предикатов со вложенными подзапросами. Фактически, каноническая форма - это алгебраическое представление запроса.
Ниже приводятся два примера канонических форм запросов с предикатами разного типа. Соответствующая техника существует и для других видов предикатов.
SELECT Ri.Ck FROM Ri WHERE Ri.Ch IS IN
SELECT Rj.Cm FROM Rj WHERE Ri.Cn = Rj.Cp
эквивалентно
SELECT Ri.Ck FROM Ri, Rj WHERE
Ri.Ch = Rj.Cm AND Ri.Cn = Rj.Cp
SELECT Ri.Ck FROM Ri WHERE Ri.Ch =
SELECT AVG (Rj.Cm) FROM Rj WHERE Rj.Cn = Ri.Cp
эквивалентно
SELECT Ri.Ck FROM Ri, Rt WHERE
Ri.Ch = Rt.Cm AND Ri.Cp = Rt.Cn
- Rt ( Cp, Cn ) = SELECT Rj.Cp, AVG (Rj.Cn) FROM Rj
GROUP BY Rj.Cp
Разумность таких преобразований обосновывается тем, что оптимизатор получает возможность выбора большего числа способов выполнения запросов. Часто открывающиеся после преобразований способы выполнения более эффективны, чем планы, используемые в традиционном оптимизаторе System R.
При использовании в оптимизаторе запросов подобного подхода не обязательно производить формальные преобразования запросов. Оптимизатор должен в большей степени использовать семантику обрабатываемого запроса, а каким образом она будет распознаваться - это вопрос техники.
Заметим, что в кратко описанном нами подходе имеются некоторые тонкие семантические некорректности. Известны исправленные методы, но они слишком сложны технически, чтобы рассматривать их на наших лекциях.
Проблемы оптимизации запросов
Как обычно, основной целью оптимизации запроса в системе ООБД является создание оптимального плана выполнения запроса с использованием примитивов доступа к внешней памяти ООБД.
Оптимизация запросов хорошо исследована и разработана в контексте реляционных БД. Известны методы синтаксической и семантической оптимизации на уровне непроцедурного представления запроса, алгоритмы выполнения элементарных реляционных операций, методы оценок стоимости планов запросов.
Конечно, объекты могут иметь существенно более сложную структуру, чем кортежи плоских отношений, но не это различие является наиболее важным. Основная сложность оптимизации запросов к ООБД следует из того, что в этом случае условия выборки формулируются в терминах "внешних" атрибутов объектов (методов), а для реальной оптимизации (т.е. для выработки оптимального плана) требуются условия, определенные на "внутренних" атрибутах (переменных состояния).
На самом деле похожая ситуация существует и в РСУБД при оптимизации запроса над представлением БД. В этом случае условия также формулируются в терминах внешних атрибутов (атрибутов представления), и в целях оптимизации запроса эти условия должны быть преобразованы в условия, определенные на атрибутах хранимых отношений. Хорошо известным методом такой "предоптимизации" является подстановка представлений, которая часто (хотя и не всегда в случае использования языка SQL) обеспечивает требуемые преобразования. Альтернативным способом выполнения запроса над представлением (иногда единственным возможным) является материализация представления.
В системах ООБД ситуация существенно усложняется двумя обстоятельствами. Во-первых, методы обычно программируются на некотором процедурном языке программирования и могут иметь параметры. Т.е. в общем случае тело метода представляет из себя не просто арифметическое выражение, как в случае определения атрибутов представления, а параметризованную программу, включающую ветвления, вызовы функций и методов других объектов.
Вторая сложность связана с возможным и распространенным в ООП поздним связыванием: точная реализация метода и даже структура объекта может быть неизвестна во время компиляции запроса.
Одним из подходов к упрощению проблемы является открытие видимости некоторых (наиболее важных для оптимизации) внутренних атрибутов объектов. В этом контексте достаточно было бы открыть видимость только для компилятора запросов, т.е. фактически запретить переопределять такие переменные в подклассах. С точки зрения пользователя такие атрибуты выглядели бы как методы без параметров, возвращающие значение соответствующего типа. С нашей точки зрения лучше было бы сохранить строгую инкапсуляцию объектов (чтобы избавить приложение от критической зависимости от реализации) и обеспечить возможности тщательного проектирования схемы ООБД с учетом потребностей оптимизации запросов.
Общий подход к предоптимизации условия выборки для одного (супер)класса объектов может быть следующим (мы предполагаем, что условия формулируются с использованием логики предикатов первого порядка без кванторов; в предикатах могут использоваться методы соответствующего класса, константы и операции сравнения):
Шаг А: Преобразовать логическую формулу условия к конъюнктивной нормальной форме (КНФ). Мы не останавливаемся на способе выбора конкретной КНФ, но естественно, должна быть выбрана "хорошая" КНФ (например, содержащая максимальное число атомарных конъюнктов).
Шаг B: Для каждого конъюнкта, включающего методы с известным во время компиляции телом, заменить вызовы методов на их тела с подставленными параметрами. (Для простоты будем предполагать, что параметры не содержат вызовов функций или методов других объектов.)
Шаг C: Для каждого такого конъюнкта произвести все возможные упрощения, т.е. вычислить все, что можно вычислить в статике. Хотя в общем виде эта задача является очень сложной, при разумном проектировании ООБД в число методов должны будут войти методы с предельно простой реализацией, задавать условия на которых будет очень естественно.
Такие условия будут упрощаться очень эффективно.
Шаг D: Если теперь появились конъюнкты, представляющие собой простые предикаты сравнения на основе переменных состояния и констант, использовать эти конъюнкты для выработки оптимального плана выполнения запроса. Если же такие конъюнкты получить не удалось, единственным способом "отфильтровать" (супер)класс объектов является его последовательный просмотр с полным вычислением (возможно упрощенного) логического выражения для каждого объекта.
Понятно, что возможности оптимизации будут зависеть от особенностей языка программирования, который используется для программирования методов, от особенностей конкретного языка запросов и от того, насколько продуманно спроектирована схема ООБД. В частности, желательно, чтобы используемый язык программирования стимулировал максимально дисциплинированный стиль программирования методов объектов. Язык запросов должен разумно ограничивать возможности пользователей (в частности, в отношении параметров методов, участвующих в условиях запросов). Наконец, в классах схемы ООБД должны содержаться простые методы, не переопределяемые в подклассах и основанные на тех переменных состояния, которые служат основой для организации методов доступа.
Заметим, что указанные ограничения не влекут зависимости прикладной программы от особенностей реализации ООБД, поскольку объекты остаются полностью инкапсулированными. Использование в условиях запросов простых методов должно стимулироваться не требованиями реализации, а семантикой объектов.
